linux源码分析(三)-start_kernel
2016-10-26 11:01 轩脉刃 阅读(10884) 评论(0) 收藏 举报前置:这里使用的linux版本是4.8,x86体系。
start_kernel是过了引导阶段,进入到了内核启动阶段的入口。函数在init/main.c中。
set_task_stack_end_magic(&init_task);
这个函数是设置操作系统的第一个进程init。
这个init_task变量是怎么来的呢?从init/init_task.c中初始化的。
struct task_struct init_task = INIT_TASK(init_task);
EXPORT_SYMBOL(init_task);
而这个INIT_TASK的初始化在init/init_task.h:
#define INIT_TASK(tsk) \
{ \
.state = 0, \
.stack = init_stack, \
.usage = ATOMIC_INIT(2), \
.flags = PF_KTHREAD, \
.prio = MAX_PRIO-20, \
.static_prio = MAX_PRIO-20, \
.normal_prio = MAX_PRIO-20, \
...
这里使用的是gcc的结构体初始化方式。http://blog.csdn.net/justlinux2010/article/details/7494754 。这个结构体是根据task_struct结构进行初始化的。
再回到set_task_stack_end_magic
void set_task_stack_end_magic(struct task_struct *tsk)
{
unsigned long *stackend;
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
}
这个end_of_stack 在include/linux/sched.h中。它的意思是获取栈边界地址。然后把栈底地址设置为STACK_END_MAGIC。这个作为栈溢出的标记。
每个进程创建的时候,系统会为这个进程创建2个页大小的内核栈。这个内核栈底下是thread_info结构。高位是栈。
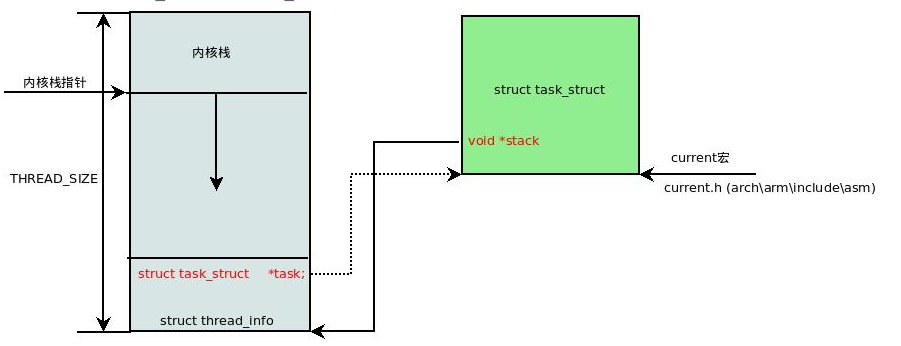
http://blog.chinaunix.net/uid-20543672-id-2996319.html
这里的STACK_END_MAGIC就是设置在thread_info结构的上面。比如如果你写了一个无限循环,导致栈使用不断增长了,那么,一旦把这个标记未修改了,就导致了栈溢出的错误。
smp_setup_processor_id();
下面是这个
smp_setup_processor_id(); // 设置smp模型的处理器id
smp模型指的是对称多处理模型(Symmetric Multi-Processor),与它对应的是NUMA非一致存储访问结构(Non-Uniform Memory Access)和MPP 海量并行处理结构(Massive Parallel Processing)。它们的区别分别在于,SMP指的是多个CPU之间是平等关系,共享全部总线,内存和I/O等。但是这个结构扩展性不好,往往CPU数量多了之后,很容易遇到抢占资源的问题。NUMA结构则是把CPU分模块,每个模块具有独立的内存,I/O插槽等。各个模块之间通过互联模块进行数据交互。但是这样,就表示了有的内存数据在这个CPU模块中,那么处理这个数据当然最好是选择当前的CPU模块,这样每个CPU实际上地位就不一致了。所以叫做非一致的存储访问结构。而MPP呢,则是由多个SMP服务器通过互联网方式连接起来。
支持SMP模型的CPU有AMD/AMD64。而支持NUMA的有X86等。而这里的代码,smp_setup_process_id在普通情况下是空实现,在不同的体系,比如arch/arm/kernel/setup.c, line 586
就有对应的逻辑了。
debug_objects_early_init();
这个函数的实际代码在lib/debugobject.c
void __init debug_objects_early_init(void)
{
int i;
for (i = 0; i < ODEBUG_HASH_SIZE; i++)
raw_spin_lock_init(&obj_hash[i].lock);
for (i = 0; i < ODEBUG_POOL_SIZE; i++)
hlist_add_head(&obj_static_pool[i].node, &obj_pool);
}
可以看到,它主要是用来对obj_hash,obj_static_pool这两个全局变量进行初始化设置。这两个全局变量在进行调试的时候会使用到。
http://m.blog.chinaunix.net/uid-27717694-id-4425488.html
boot_init_stack_canary();
这个函数是做什么的呢?我们要说堆栈溢出漏洞,它的意思就是动态分配的堆中,不按照本来分配的大小进行设置,而是使用某种方法,设置变量分配大小之外的数据。甚至设置到了函数栈的数据了,那么,这个时候就可能会被调用到注入的某个函数中了。具体攻击示例看:http://www.ibm.com/developerworks/cn/linux/l-overflow/
那么,和前面的end_magic逻辑一样,我们在堆和栈的中介处设置一个标记位(叫做canary word)。当这个位被修改的时候,我们就知道了,这个时候存在堆栈溢出,就进行错误处理。
那么这个标记位的值是怎么样子的,就是使用这个函数。这个也和CPU架构有关系了,比如在x86的系统中,是随机产生的。https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/
实时了解作者更多技术文章,技术心得,请关注微信公众号“轩脉刃的刀光剑影”
本文基于署名-非商业性使用 3.0许可协议发布,欢迎转载,演绎,但是必须保留本文的署名叶剑峰(包含链接http://www.cnblogs.com/yjf512/),且不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号