
Lucene.Net+盘古分词器(详细介绍)
文章来源:http://www.cnblogs.com/crazybottle/p/3911291.html
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。开发人员可以基于Lucene.net实现全文检索的功能。
Lucene.net是Apache软件基金会赞助的开源项目,基于Apache License协议。
Lucene.net并不是一个爬行搜索引擎,也不会自动地索引内容。我们得先将要索引的文档中的文本抽取出来,然后再将其加到Lucene.net索引中。标准的步骤是先初始化一个Analyzer、打开一个IndexWriter、然后再将文档一个接一个地加进去。一旦完成这些步骤,索引就可以在关闭前得到优化,同时所做的改变也会生效。这个过程可能比开发者习惯的方式更加手工化一些,但却在数据的索引上给予你更多的灵活性。
(来自百度百科)
盘古分词是一个中英文分词组件。作者eaglet 曾经开发过KTDictSeg 中文分词组件,拥有大量用户。作者基于之前分词组件的开发经验,结合最新的开发技术重新编写了盘古分词组件。主要有以下功能:
1、中文未登陆词识别
2、词频优先
3、一元分词,多元分词
4、中文人名分词
5、繁体中文分词
6、英文分词
7、用户自定义规则(字典管理,动态加载字典,关键词高亮)
……
由于盘古分词器不是本章的重点内容,就简单带过了。有兴趣的朋友可以自己网上找找相关资料。文章末尾会提供一个盘古分词器的应用程序供下载
先上一下Demo的图把,看下最后运行效果:
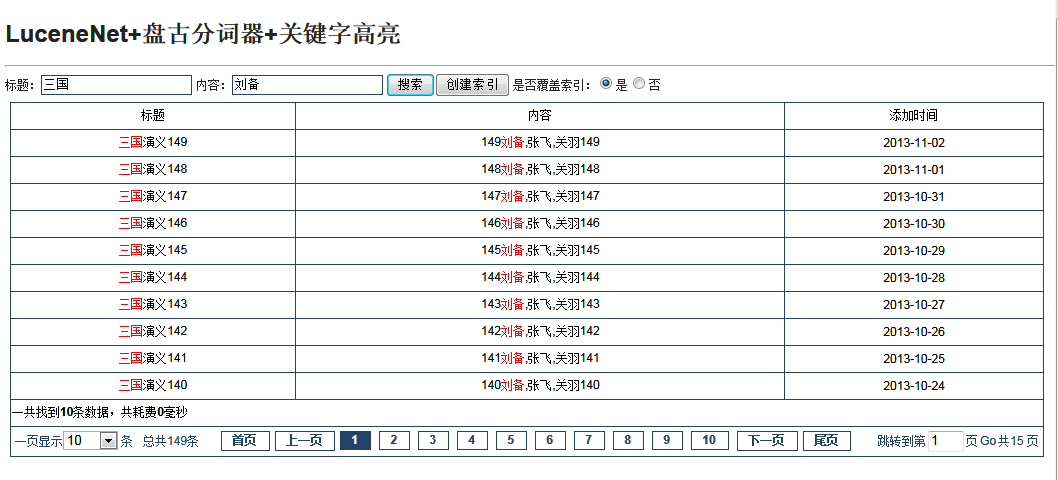
数据是临时随便创建的数据,表格和样式也是随便画的,不喜欢的朋友多包涵呐!
接下来就一步一步来讲解整个编码过程(主要对一些核心的类和细节作为讲解过程),Let's GO
第一步:创建索引
1、由于索引是存放在硬盘里的,所以先定义一个索引的目录
/// <summary> /// 索引存放目录 /// </summary> protected string IndexDic { get { return Server.MapPath("/IndexDic"); } }
2、创建索引器把要索引的内容写入到指定目录
IndexWriter writer = new IndexWriter(IndexDic, PanGuAnalyzer, isCreate, Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED);索引器的构造函数参数说明:
IndexDic是索引存放目录
PanGuAnalyzer是盘古解析器(由于默认的解析器解析能力不强,所以替换为这个)
IsCreate是索引创建方式(true:重新新建索引,false:从旧的索引执行追加)
Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED是文件长度是否限制
3、创建索引Document和往文档写入索引内容
private void AddIndex(IndexWriter writer, string title, string content,string date)
{
try
{
Document doc = new Document();
doc.Add(new Field("Title", title, Field.Store.YES, Field.Index.ANALYZED));//存储且索引
doc.Add(new Field("Content", content, Field.Store.YES, Field.Index.ANALYZED));//存储且索引
doc.Add(new Field("AddTime", date, Field.Store.YES, Field.Index.NOT_ANALYZED));//存储且索引
writer.AddDocument(doc);
}
catch (FileNotFoundException fnfe)
{
throw fnfe;
}
catch (Exception ex)
{
throw ex;
}
}
Document是索引文档,可以理解成数据库里的记录
Field是索引文档里的字段,可以直接理解成数据库里的字段
Field构造函数说明:
第一个是字段名称(实例里是Title,Content,AddTime)。
第二个是字段的存储方式(Field.Store.YES:进行存储,Filed.Store.No:不进行存储)有些字段值比较大,可以选择No不存储,对字段进行存储是为了检索的时候对某些字段进行提取。
第三个是是否索引(Field.Index.ANALYZED:索引, Field.Index.NOT_ANALYZED:非索引)
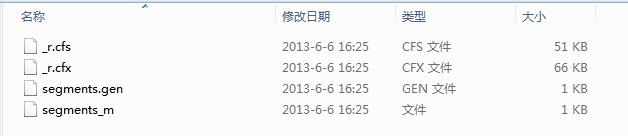
4、到此为止索引就创建完成了,应该可以看到索引目录会产生几个文件,如下图:
第二步:搜索索引
lucene的搜索相当强大,它提供了很多辅助查询类,每个类都继承自Query类,各自完成一种特殊的查询,你可以像搭积木一样将它们任意组合使用,完成一些复杂操 作;另外lucene还提供了Sort类对结果进行排序,提供了Filter类对查询条件进行限制。你或许会不自觉地拿它跟SQL语句进行比 较:“lucene能执行and、or、order by、where、like ‘%xx%’操作吗?”回答是:“当然没问题!”
private void SearchIndex() { Dictionary<string, string> dic = new Dictionary<string, string>(); BooleanQuery bQuery = new BooleanQuery(); string title = string.Empty; string content = string.Empty; if (Request.Form["title"] != null && Request.Form["title"].ToString()!="") { title =GetKeyWordsSplitBySpace( Request.Form["title"].ToString()); QueryParser parse = new QueryParser("Title", PanGuAnalyzer); Query query = parse.Parse(title); parse.SetDefaultOperator(QueryParser.Operator.AND); bQuery.Add(query, BooleanClause.Occur.MUST); dic.Add("title",Request.Form["title"].ToString()); txtTitle = Request.Form["title"].ToString(); } if (Request.Form["content"] != null && Request.Form["content"].ToString() != "") { content = GetKeyWordsSplitBySpace(Request.Form["content"].ToString()); QueryParser parse = new QueryParser("Content", PanGuAnalyzer); Query query = parse.Parse(content); parse.SetDefaultOperator(QueryParser.Operator.AND); bQuery.Add(query, BooleanClause.Occur.MUST); dic.Add("content",Request.Form["content"].ToString()); txtContent = Request.Form["content"].ToString(); } if (bQuery != null && bQuery.GetClauses().Length>0) { GetSearchResult(bQuery, dic); } }
这段代码创建了一个索引查询器,对title和content这两个字段进行查询。
1、介绍各种Query
TermQuery: 首先介绍最基本的查询,如果你想执行一个这样的查询:在content字段中查询包含‘刘备的document”,那么你可以用TermQuery:
Term t = new Term("content", "刘备"); Query query = new TermQuery(t);
BooleanQuery :如果你想这么查询:在content字段中包含”刘备“并且在title字段包含”三国“的document”,那么你可以建立两个TermQuery并把它们用BooleanQuery连接起来:
TermQuery termQuery1 = new TermQuery(new Term("content", "刘备")); TermQuery termQuery2 = new TermQuery(new Term("title", "三国")); BooleanQuery booleanQuery = new BooleanQuery(); booleanQuery.Add(termQuery1, BooleanClause.Occur.SHOULD); booleanQuery.Add(termQuery2, BooleanClause.Occur.SHOULD);
WildcardQuery :如果你想对某单词进行通配符查询,你可以用WildcardQuery,通配符包括’?’匹配一个任意字符和’*’匹配零个或多个任意字符,例如你搜索’三国*’,你可能找到’三国演义’或者’三国志’:
Query query = new WildcardQuery(new Term("content", "三国*"));
PhraseQuery :你可能对中日关系比较感兴趣,想查找‘中’和‘日’挨得比较近(5个字的距离内)的文章,超过这个距离的不予考虑,你可以:
PhraseQuery query = new PhraseQuery(); query.SetSlop(5); query.Add(new Term("content ", "中")); query.Add(new Term("content", "日"));
那么它可能搜到“中日合作……”、“中方和日方……”,但是搜不到“中国某高层领导说日本欠扁”。
PrefixQuery :如果你想搜以‘中’开头的词语,你可以用PrefixQuery:
PrefixQuery query = new PrefixQuery(new Term("content ", "中"));
FuzzyQuery :FuzzyQuery用来搜索相似的term,使用Levenshtein算法。假设你想搜索跟‘wuzza’相似的词语,你可以:
Query query = new FuzzyQuery(new Term("content", "wuzza"));
你可能得到‘fuzzy’和‘wuzzy’。
RangeQuery: 另一个常用的Query是RangeQuery,你也许想搜索时间域从20060101到20060130之间的document,你可以用RangeQuery:
RangeQuery query = new RangeQuery(new Term("time","20060101"), new Term("time","20060130"), true);
最后的true表示用闭合区间。
第三步:返回索引结果
上面介绍完各种查询的Query,接下来看看LuceneNet返回的数据集如何处理,如何显示高亮,上代码:
private void GetSearchResult(BooleanQuery bQuery,Dictionary<string,string> dicKeywords) { IndexSearcher search = new IndexSearcher(IndexDic,true); Stopwatch stopwatch = Stopwatch.StartNew(); //SortField构造函数第三个字段true为降序,false为升序 Sort sort = new Sort(new SortField("AddTime", SortField.DOC, true)); TopDocs docs = search.Search(bQuery, (Filter)null, PageSize * PageIndex, sort); stopwatch.Stop(); if (docs != null && docs.totalHits > 0) { lSearchTime = stopwatch.ElapsedMilliseconds; txtPageFoot = GetPageFoot(PageIndex, PageSize, docs.totalHits, "sabrosus"); for (int i = 0; i < docs.totalHits; i++) { if (i >= (PageIndex - 1) * PageSize && i < PageIndex * PageSize) { Document doc = search.Doc(docs.scoreDocs[i].doc); Article model = new Article() { Title = doc.Get("Title").ToString(), Content = doc.Get("Content").ToString(), AddTime = doc.Get("AddTime").ToString() }; list.Add(SetHighlighter(dicKeywords, model)); } } } }
最后这段代码相对比较简单,我就说下几个关键的类和高亮提示把。
1、关键类说明:
IndexSearcher:索引查询器,它的构造函数有两个参数,一个是索引文件路径,一个是是否只读(一般都设置为true就可以)。这个东西可以理解为SqlServer里面的查询分析器。
Sort:看字眼可知道是索引排序类。主要说一下第三个参数,第三个参数是排序方式(true为降序,false为升序)。
TopDocs:这个是查询后返回的文档,可以理解为Sqlserver的表,search.Search可以当做是在查询分析器里按了一次F5查询。
2、设置关键字高亮:
private Article SetHighlighter(Dictionary<string, string> dicKeywords, Article model) { SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"green\">", "</font>"); Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new Segment()); highlighter.FragmentSize = 50; string strTitle = string.Empty; string strContent = string.Empty; dicKeywords.TryGetValue("title", out strTitle); dicKeywords.TryGetValue("content", out strContent); if (!string.IsNullOrEmpty(strTitle)) { model.Title = highlighter.GetBestFragment(strTitle, model.Title); } if (!string.IsNullOrEmpty(strContent)) { model.Content = highlighter.GetBestFragment(strContent, model.Content); } return model; }
这里用的也是盘古的高亮组件,设置高亮主要分两个步骤:
设置高亮的显示样式、设置高亮的查询关键字
SimpleHTMLFormatter:这个类是一个HTML的格式类,构造函数有两个,一个是开始标签,一个是结束标签。
Segment:添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment。
参考文献:
http://www.cnblogs.com/jeffwongishandsome/archive/2011/01/02/1924107.html
http://space.itpub.net/12639172/viewspace-626546
Demo下载 (Demo是visual studio 2010编写的,打不开请下载vs2010或者自己更改为vs2008或其他版本)

