深度学习实践系列之--身份证上汉字及数字识别系统的实现(上)
前言:
本文章将记录我利用深度学习方法实现身份证图像的信息识别系统的实现过程,及学习到的心得与体会。本次实践是我投身AI的初次系统化的付诸实践,意义重大,让自己成长许多。终于有空闲的时间,将其记录,只为更好的分享与学习。
目录:
1、本人的主要工作
2、关键技术
3、模型训练
4、系统设计及实现
5、总结
正文:
一、本人的主要工作
深度学习技术与传统模式识别技术相比,免去人工提取特征,识别率更高。我基于深度学习的技术背景,主要的研究内容如下:
1)身份证图像涉及个人隐私,很难获取其数据训练集。针对此问题,我采用获取身份证上印刷体汉字和数字的数据训练集的方法,利用Python图像库(PIL)将13类汉字印刷体字体转换成6492个类别,建立了较大的字符训练集;
2)如何获取身份证图片上的字符是在设计中一个重要问题。我采用水平和垂直投影技术,首先对身份证图像进行预处理,然后对图片在水平和垂直方向上像素求和,区分字符与空白区域,完成了身份证图像中字符定位与分割工作,有很好的切分效果;
3)在模型训练中模型的选择与设计是一个重要的环节,本文选择Lenet模型,发现模型层次太浅,然后增加卷积层和池化层,设计出了改进的深层Lenet模型,然后采用Caffe深度学习工具对模型进行训练,并在训练好的模型上进行测试,实验表明,模型的测试精度达到96.2%。
基于上述研究,本文设计并实现了身份证图像自动识别系统,该系统先从移动端拍照获取身份证图片,然后在Flask轻量级web服务器上将身份证图像输入到模型中进行识别,并返回识别结果。设计的系统能准确识别出身份证上文字信息,具有较高的准确率,有一定的实用价值。
二、关键技术
2.1 深度学习介绍
深度学习技术被提出后,发展迅速,在人工智能领域取得了很好的成绩,越来越多优秀的神经网络也应运而生。深度学习通过建立多个隐层的深层次网络结构,比如卷积神经网络,可以用来研究并处理目前计算机视觉领域的一些热门的问题,如图像识别和图像检索。
深度学习建立从输入数据层到高层输出层语义的映射关系,免去了人工提取特征的步骤,建立了类似人脑神经网的分层模型结构。深度学习的示意图如图所示
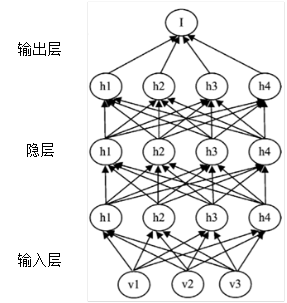
图 有多个隐层的深度学习示意图
深度学习的学习过程会分层进行,深度学习经过多层的学习,最终可以很好的表示数据特征。
2.2 卷积神经网络(CNN)
卷积神经网络有了很多年的发展,CNN在对图像的识别上有很好的表现,利用权值共享的方式,降低了网络的维度,也加快了训练网络的效率。
CNN具有多层的神经网络,有卷积层、池化层和线性整流层等,具体CNN网络结构示意图如图所示:
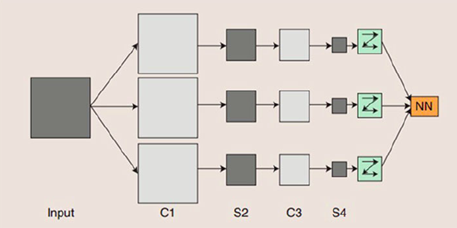
图 卷积神经网络示意图
如上图所示,输入数据图像Input分别与三个滤波器做卷积运算。卷积完成后, 函数得到的特征映射图,然后再将特征映射图输入到 层。S2层处理完后到达C3层,和 C1 的处理步骤一样,以此类推,最终输出结果。
卷积神经网络的网络结构如下:
1)卷积层(Convolutional layer)
卷积层由卷积单元组成,卷积单元进行着卷积运算,目的是提取出不同的形色各异的特征。
2)线性整流层(ReLU layer)
线性整流层使用线性整流(Rectified Linear Units, ReLU)作为这一层神经的激活函数(Activation function)。它可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层。ReLU可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成产生显著影响。
3)池化层(Pooling Layer)
池化(Pooling)是卷积神经网络中另一个重要的概念。Pooling是一种向下采样过程,它将划定的区域输出最大值。Pooling层的作用是通过减小数据参数数量有效的控制过拟合。在平时的使用中,Convolutional层之间都会按照一定的周期来插入Pooling层。
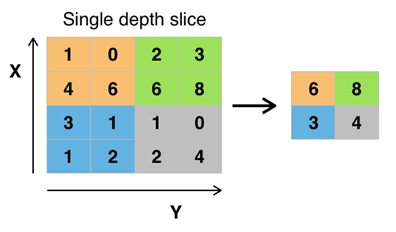
图 池化层下采样过程图
池化层通常会分别作用于每个输入的特征并减小其大小。目前最常用形式的池化层是每隔2个元素从图像划分出2x2的区块,然后对每个区块中的4个数取最大值。这将会减少75%的数据量。过去,平均池化的使用曾经较为广泛,但是最近由于最大池化在实践中的表现更好,平均池化已经不太常用。
因为池化层太快地减小了数据量的大小,对与数据特征的学习不利,目前的趋势是使用较小的池化滤镜,甚至不再使用池化层。
4)损失函数层(loss layer)
损失函数层通常是网络的最后一层,用于表示预测与测试结果之间的差别。在网络中有不同类型的损失函数。
2.1.3 Lenet模型和Alexnet模型
1)Lenet模型
Lenet由Yan Le Cun等人于1998年提出,在手写数字的识别上有极高的准确率。 输入层大小为128×128,第一个卷积层窗口大小为 5×5,有 20 个过滤器共生成 20 张特征图,第二个卷积层窗口大小为 5×5,50 个过滤器共生成 50 张特征图,两个池化层窗口大小均为 2,第一个全连接层共有 500 个神经元,如图所示。
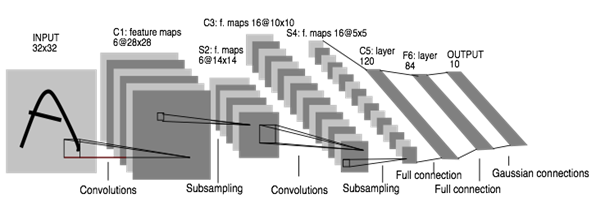
图 Lennet模型示意图
2)Alexnet模型
Alexnet比Lenet的网络结构更深,如图 Alexnet示意图所示。
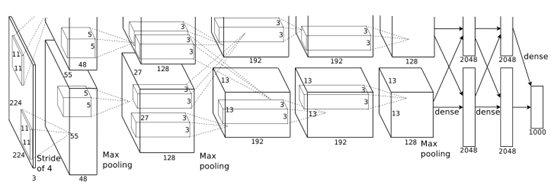
图 Alexnet网络模型示意图
在Alexnet网络模型中输入的图像规格是224*224三通道的RGB颜色图像,特征的提取采用5*5的卷积核。在使用中Alexnet会输入227*227三通道图片,而不是它规格中的大小。在提取特征图时采用公式,如下所示:
[img_size - filter_size]/stride +1 = new_feture_size
其中[ ]表示向下取整,图片并且是RGB通道的。
2.2 深度学习框架Caffe介绍
Caffe是目前深度学习领域主流的一个开源库,采用C++和CUDA实现,支持MATLAB和Python接口,优点是速度快、开放性好、易于模块化拓展。Caffe可以广泛应用在多个领域,典型的如图像分类、语音识别等。
Caffe框架可以从三方面来理解:1)数据存储:Caffe通过四维数组(blobs)来保存模型计算上的数据,大型数据存储在LevelDB数据库中。2)层结构: Caffe支持完整的层类型,按照分层模型,可以在分层模型中保证了数据参数传递的准确性; 3)网络和运行方式:一个深度神经网络起始于数据层,数据层加载数据,中间每一层计算出梯度,最后一层完成分类重建,这样一整套运行流程使得Caffe有很好的健壮性。
2.3 字符定位与切割
在对输入的身份证图片进行识别前,要进行必要的图片预处理。在本文的系统中是基于单个字符的数据集训练得到的模型,系统中输入身份证图片后要对文字区域进行定位与切割,以此来获取身份证 图片上的每一个字符。
本文的字符定位与切割采用水平和垂直投影分割法,具体流程如下:1)首先对图像进行二值化处理,将图像转变成黑白的灰度图;2)在字符区域图像中呈现出白色,空隙区域为黑色,通过水平投影的方式将字符区域与空隙区域分割开,以此来确定字符所在行。3)使用垂直投影分割法,将字符从二值化图像的每一行中分割出来,如此经过垂直与水平的切割,可以将每个字都分割出来。
三、模型训练
3.1 获取数据样本库
本系统中,要获取的身份证上的字体为印刷体,目前有很多开源的手写汉字数据库,比如中科院的CASIA手写中文字库]中的 HWDB1.1 脱机字库子集。如果利用手写汉字库进行本系统的模型训练,会导致模型精度不高,而且适用情景也有偏差。所以在本系统中我将用Python生成印刷体汉字图片字库。
在日常使用中,共有3755个常用汉字,如何获取这些数据训练集成为一个要解决的问题。在Python图像库(PIL)是很好的工具,有很优秀的图像处理功能,本文利用PIL对数据训练集进行处理。PIL实现文字转换成图片的过程核心代码如下所示:
find_image_bbox = FindImageBBox() img = Image.new("RGB", (self.width, self.height), "black") draw = ImageDraw.Draw(img)
PIL将文字绘制到img上,之后把图片保存成jpg格式。
从项目的font_path目录下选择字体格式文件,有ttf、ttc、otf等格式的文件,都通过ImageFont的truetype()方法设置选择哪种字体文件
然后将文字绘制到图片中,输出文字图片的列表:
draw.text((0, 0), char, (255, 255, 255),font=font)
data = list(img.getdata())
经过实验,本文收集到一级常用和次常用的汉字共有6492个,将每个汉字写入脚本的数据文件中,然后使用上述PIL方法依次读取数据文件中的汉字并生成字体图片输出,并将字体图片按顺序分类存放,汉字的脚本见下面的链接:脚本链接GitHub

字体文件下载地址:链接
这里生成的字体图片如图所示,最后会组合类别:

这里附上执行获取数据集的脚本代码:
3.2 处理数据集图片
本文采用Caffe框架在分割好的字符集上进行训练。在训练网络前首先要准备好数据训练集。在Caffe中直接使用的是lmdb或者leveldb文件,所以我们需要将图片文件转化成db文件,让Caffe可识别。在Caffe的工程目录下的tools里很多工具类文件,其中的convert_imageset.cpp的作用就是将图片数据训练集转换成db文件,让Caffe能够识别,在对Caffe编译之后产生可执行文件,这里convert_imageset的使用格式如下:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
如上所示,convert_imageset方法需要带四个参数,分别指定图片参数、图片存放的路径、图片清单和生成的db文件存放目录。
之后创建一个sh脚本文件将各个函数与输出进行整合,最终的目的是在相应目录下生成train_lmdb和test_lmdb文件,如下为在脚本文件中生成train_lmdb的示例代码:
GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_width=$RESIZE_WIDTH --shuffle --gray \ $TRAIN_DATA_ROOT $DATA/train.txt $EXAMPLE/train_lmdb
最后在终端下运行这个脚本文件,生成了训练用和测试用的lmdb文件,如图所示:


图 lmdb文件目录
同时会生成图片清单文件列表,本文截取部分内容,如图3.5所示:

这里附上数据集转换的完整代码:
#!/usr/bin/env sh # Create the imagenet lmdb inputs # N.B. set the path to the imagenet train + val data dirs EXAMPLE=/workspace/caffe_dataset_lower_eng mkdir -p $EXAMPLE rm -rf $EXAMPLE/train_lmdb rm -rf $EXAMPLE/val_lmdb DATA=/workspace/caffe_dataset_lower_eng TOOLS=$CAFFE_ROOT/build/tools TRAIN_DATA_ROOT=${DATA}/ VAL_DATA_ROOT=${DATA}/ # Set RESIZE=true to resize the images to 256x256. Leave as false if images have # already been resized using another tool. RESIZE=true if $RESIZE; then RESIZE_HEIGHT=28 RESIZE_WIDTH=28 else RESIZE_HEIGHT=0 RESIZE_WIDTH=0 fi if [ ! -d "$TRAIN_DATA_ROOT" ]; then echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT" echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \ "where the ImageNet training data is stored." exit 1 fi if [ ! -d "$VAL_DATA_ROOT" ]; then echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT" echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \ "where the ImageNet validation data is stored." exit 1 fi echo "Creating train lmdb..." GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_width=$RESIZE_WIDTH \ --shuffle \ --gray \ $TRAIN_DATA_ROOT \ $DATA/train.txt \ $EXAMPLE/train_lmdb GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_width=$RESIZE_WIDTH \ --shuffle \ --gray \ $VAL_DATA_ROOT \ $DATA/test.txt \ $EXAMPLE/val_lmdb echo "Done."
3.3 模型的选择
在进行网络训练前另一项关键的任务是模型的选择与配置,因为要保证模型的精度,要选一个适合本文身份证信息识别的网络模型。
首先因为汉字识别相当于一个类别很多的图片分类系统,所以先考虑深层的网络模型,优先采用Alexnet网络模型,对于汉字识别这种千分类的问题很合适,但是在具体实施时发现本文获取到的数据训练集每张图片都是64*64大小的一通道的灰度图,而Alexnet的输入规格是224*224三通道的RGB图像,在输入上不匹配,并且Alexnet在处理像素较高的图片时效果好,用在本文的训练中显然不合适。
其次是Lenet模型,没有改进的Lenet是一个浅层网络模型,如今利用这个模型对手写数字识别精度达到99%以上,效果很好,在实验时我利用在Caffe下的draw_net.py脚本并且用到pydot库来绘制Lenet的网络模型图,实验中绘制的原始Lenet网络模型图如图所示,图中有两个卷积层和两个池化层,网络层次比较浅。
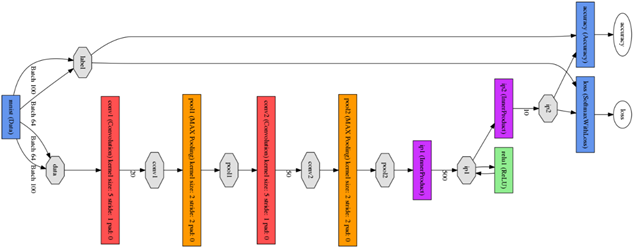
图 原始的Lenet网络模型结构图
前期实验中将数据训练集放入未改进的Lenet模型中进行训练,训练效果不理想,accurary值不是稳定上升,而是时常波动,并且出现了过拟合的现象,这里截取了一张网络迭代四千次的ROC曲线图如图所示:

图 迭代四千次的ROC曲线图
图中出现明显的波动,并且出现accuracy=1的时候的过拟合现象,因为网络层次比较浅,训练效果不理想。这是因为在汉字识别系统上,汉字分类数量巨大,有几千个分类,简单的Lenet不足够支持这么多的分类。本文尝试使用改进的Lenet网络模型用在本文的训练上,所以本文在训练网络前期实验的基础上,在Lenet-5的基础上增加隐含层,包括卷积层和池化层,最后网络结构达到了11层,修改完成后,为了查看网络的结构组成,同样使用draw_net.py脚本对改进的网络模型进行绘制,具体结构如图所示:
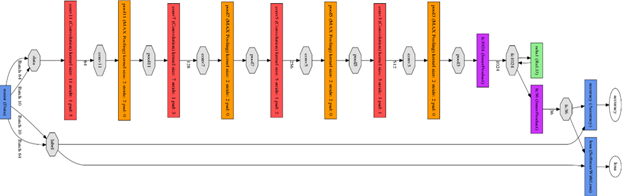
图 改进的Lenet网络模型结构图
在图中可以明显看出和原始的Lenet模型相比,改进后的模型层次明显加深,多了一倍的卷积层和池化层。经过前期训练实验得出:深层网络能更好的支持汉字的分类。
3.4 训练模型
首先编辑solver.prototxt文件:
# The train/test net protocol buffer definition net: "data/lenet_train_test.prototxt" # test_iter specifies how many forward passes the test should carry out. # In the case of MNIST, we have test batch size 100 and 100 test iterations, # covering the full 10,000 testing images. test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 # The learning rate policy lr_policy: "inv" gamma: 0.0001 power: 0.75 # Display every 100 iterations display: 100 # The maximum number of iterations max_iter: 50000 # snapshot intermediate results snapshot: 5000 snapshot_prefix: "data/lenet" # solver mode: CPU or GPU solver_mode: GPU
在Caffe的build文件夹下有tools文件夹,这个里面有个可执行文件caffe,根据上文生成的Solver文件,可以在终端直接输入命令开始训练网络:
build/tools/caffe train -solver data/deepocr/solver.prototxt --gpu=1
这里在命令行的后面添加--gpu=1,表示选择Tesla K40上GPU进行模型的训练。因为数据量和迭代次数较大,尽管在GPU环境下训练并利用cuDNN加速,但训练模型还是花费了大约8个小时的时间。最后的训练精度达到0.962,loss值较小,如图所示,图中达到预期的效果,训练成功。

图 训练并测试的结果图
为了更加详细的了解训练的过程,本文使用Python的接口对训练过程进行可视化,方便得出实验的结论,所以本文使用jupyter notebook来绘制loss值和accuracy值变化的ROC曲线图,在网页的输入框中配置相关信息即可绘制曲线图,本文使用SGDSolver,即随机梯度下降算法对曲线进行绘制:
solver = caffe.SGDSolver('data/deepocr/solver.prototxt')
然后设置迭代次数和手机数据的间隔等信息:
niter = 20000 display= 100
这里迭代次数设置为20000次是因为训练时发现迭代次数超过两万次后accuracy的值会趋于稳定,浮动很小,为了使用对训练过程进行可视化,无法利用服务器GPU进行绘制,只能在本地CPU环境下绘制,所以耗时会非常长。
迭代并获取loss和accuracy值后,初始化曲线图,将值传入,便可绘制出ROC曲线图:
ax1.set_xlabel('iteration') ax1.set_ylabel('train loss') ax2.set_ylabel('test accuracy')
loss和accuracy曲线图如图所示:

图 loss和accuracy曲线图
在图中可以看出,在迭代两万次后,loss值逐渐减小并 趋于稳定,accuracy精度值逐渐稳定达到0.96左右,
最后训练完模型后配置生成deploy.prototxt文件,这个文件会在模型的使用时用到。和训练时的网络模型文件不同,它没有数据层,并且将最后的层替换成为概率层。deploy文件通过手动配置完成。
最后附上修改后的Lenet网络:链接
其余代码见GitHub:https://github.com/still-wait/deepLearning_OCR
由于篇幅原因,本文其余内容详见 :
深度学习实践系列之--身份证上汉字及数字识别系统的实现(下)
本人原创,转载请注明:http://www.cnblogs.com/ygh1229/p/7224940.html
by still、

