第二周作业 WordCount
1. github 地址:
https://github.com/XueRui97/WCProject
2. PSP表格:
| PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) | |
|---|---|---|---|
| · Planning | · 计划 | 60 | 50 |
| · Estimate | · 估计这个任务需要多少时间 | 40 | 30 |
| · Development | · 开发 | 400 | 450 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 40 |
| · Design Spec | · 生成设计文档 | 40 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 130 |
| · Coding | · 具体编码 | 400 | 550 |
| · Code Review | · 代码复审 | 200 | 350 |
| · Test | · 测试(自我测试,修改代码,提交修改 | 120 | 180 |
| · Reporting | · 报告 | 100 | 120 |
| · Test Report | · 测试报告 | 180 | 200 |
| · Size Measurement | · 计算工作量 | 40 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 50 |
| · 合计 | 1820 | 2260 |
3. 解题思路:
- 首先看到题目要求的用命令行参数的形式输入,就是需要用到main函数的argv参数。然后就想到,要相对不同的输入采取不同的模式,首先需要对输入的参数识别。这时,我便想有没有能够解析命令行参数的函数。然后便找到了getopt()这个函数,能够方别地解析命令行参数。
- 解决了解析参数问题后,还有就是读取输入文件的内容,以及保存处理结果需要用到写入文件。
- 然后重点就在于中间的处理过程,查行数,单词数,和字符数倒是比较简单。难点在于如何辨别代码行,空行以及注释行。而且这一点由于需求不太明确,所以需要花费很长时间。
4. 程序实现:
我是采用C语言实现的,采用面向过程编程的方式。把从头到尾的过程分成几部分,然后编写对应的函数。首先是解析命令行参数的函数,由这个函数可以获得输入的模式,以及输入输出的文件名。然后是查行数,单词数,和字符数。这三个功能相对来说比较简单,只需一次读取文件就能够完成这三个功能,所以便放在一个函数里。然后是处理代码行,空行,注释行,这三个较为麻烦,但是中间处理的过程比较类似,所以也放在一个函数里。最后保存结果也需要用一个函数来实现。实现递归处理文件也需要一个函数处理。
5. 代码说明:
解析命令行参数:
while((opt=getopt(argc,argv,"a:s:l:w:c:o:")) != -1) { switch(opt) { case 'a': //返回更复杂的数据(代码行 / 空行 / 注释行) a = 1; strcpy(inputFileName,optarg); break; case 's': //递归处理目录下符合条件的文件 l = w = c = 1; strcpy(inputFileName,optarg); break; case 'l': //行数 l = 1; strcpy(inputFileName,optarg); break; case 'w': //单词数 w = 1; strcpy(inputFileName,optarg); break; case 'c': //字符数 c = 1; strcpy(inputFileName,optarg); break; case 'o': //输出文件 o = 1; strcpy(outputFileName,optarg); } }
统计单词,行,字符数:
int countFile(char *filename){ FILE *fp; // 指向文件的指针 char buffer[1003]; //缓冲区,存储读取到的每行的内容 int bufferLen; // 缓冲区中实际存储的内容的长度 int i; // 当前读到缓冲区的第i个字符 char c; // 读取到的字符 int isLastBlank = 0; // 上个字符是否是空格 int charNum = 0; // 当前行的字符数 int wordNum = 0; // 当前行的单词数 if( (fp=fopen(filename, "rb")) == NULL ){ perror(filename); return -1; } //printf("line words chars\n"); // 每次读取一行数据,保存到buffer,每行最多只能有1000个字符 while(fgets(buffer, 1003, fp) != NULL){ bufferLen = strlen(buffer); // 遍历缓冲区的内容 for(i=0; i<bufferLen; i++){ c = buffer[i]; if( c==' ' || c=='\t'){ // 遇到空格 !isLastBlank && wordNum++; // 如果上个字符不是空格,那么单词数加1 isLastBlank = 1; }else if(c!='\n'&&c!='\r'){ // 忽略换行符 charNum++; // 如果既不是换行符也不是空格,字符数加1 isLastBlank = 0; } } !isLastBlank && wordNum++; // 如果最后一个字符不是空格,那么单词数加1 isLastBlank = 1; // 每次换行重置为1 // 一行结束,计算总字符数、总单词数、总行数 lineCnt++; // 总行数 charCnt += charNum; // 总字符数 wordCnt += wordNum; // 总单词数 // 置零,重新统计下一行 charNum = 0; wordNum = 0; } fclose(fp); return 1; }
递归处理输入文件:
辨别代码行,空行,注释行:
保存文件:
int writeOutput(char *outFile, char *inFile) { FILE *fpWrite = fopen(outFile,"w"); if (fpWrite == NULL) return -1; fprintf(fpWrite, "%s,", inFile); if (l) { fprintf(fpWrite, "行数: %d,", lineCnt); } if (w) { fprintf(fpWrite, "单词数: %d,", wordCnt); } if (c) { fprintf(fpWrite, "字符数: %d\n\n", charCnt); } fclose(fpWrite); }
6. 测试设计过程:
测试方法:白盒测试
WordCount只有一个模式(即-c -w -l -o)时,运行路径如下图:
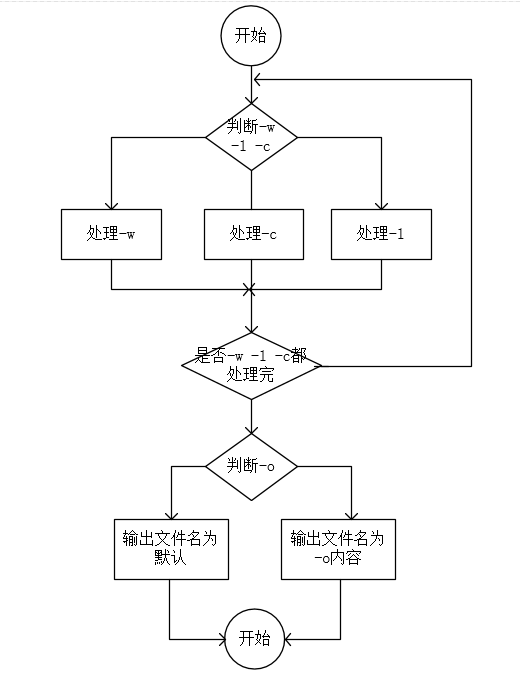
设计测试用例思路:设计出的测试用例需要能覆盖程序的所有功能,即把每一条路径都走一遍。同时,还要测试在输入参数不正确的情况下,程序会如何运行。总之,就是把程序的所有的可能的情况都运行一遍。
测试重点:重点在于对参数的判断以及执行相应的分支,以及错误情况下的运行。
10个测试用例分别为:
1. wc.exe -l test.txt 2. wc.exe -w test.txt 3. wc.exe -c test.txt 4. wc.exe -l 5. wc.exe -l test.txt -o output.txt 6. wc.exe -w test.txt -o output.txt
7. wc.exe -c example.txt -o output.txt 8. wc.exe -o output.txt 9. wc.exe -w -c test.txt 10. wc.exe -c -l -w test.txt -o output.txt
其中 1,2,3,5,6,9,10都为正常输入,能够正常输出结果,没有-o的默认保存到result.txt,有-o的保存到-o后面的文件。
4,7,8为3种错误的输入,4没有输入文件,运行后会出现错误提示提示,输入错误,没有输入文件。
7的输入文件example.txt不存在当前目录下,即输入文件不存在,此时会出现错误提示,没有找到输入文件。
8的输入没有输入文件,但有输出文件,此时会提示,输入错误,没有输入模式。
总结:正确输入都能够输出正确的结果,错误的输入能输出对应的错误提示。
7. 参考资料链接:
[1]http://www.cnblogs.com/runnyu/p/4943704.html
[2]http://www.cnblogs.com/Ming8006/p/5798186.html
[3]http://blog.csdn.net/y1196645376/article/details/53365909
