《数据库系统概论》 -- 11.并发机制
1.背景
事务在执行过程中需要不同的资源,有时需要CPU,有时需要I/O,有时需要通信。如果事务串行执行,则许多系统资源将处于空闲状态。
在单处理机系统中,事务的并行执行实际上是这些并行事务的并行操作操作轮流交叉运行,称交叉并发方式。
在多处理机系统中,每个处理机可以运行一个事务,多个处理机可以同时运行多个事务,称同时并发方式。
2.并发类型
并发事务会造成数据不一致,主要包括丢失修改、不可重复读、读“脏”数据
并发控制可实现事务的隔离性与一致性
2.1丢失修改
T1,T2同时读入同一数据进行相同的修改,则可能会丢失某一事务的修改
2.2不可重复读
T2先读,T1修改,T2再读,单个记录两次数据不一致;
T2先读,T1删除,T2再读,记录数减少或不存在;
T2先读,T1新增,T2再读,记录数增多;
2.3读脏数据
T1先修改,T2读取,T1某种原因被撤销,T2读的数据为脏数据
3.并发处理
主要的技术有封锁、时间戳、乐观控制法和多版本并发控制。
3.1封锁
原理
事务T在对某个数据对象(如表、记录)操作之前,先向系统发出请求,对其加锁,加锁后事务T在释放他的锁之前,其他事务不能更新此数据对象。
封锁类型
排它锁(X锁):事务T对数据对象D加X锁,其他事务不可读写该数据对象D
共享锁(S锁):事务T对数据对象D加S锁,其他事务可以读取D,但不可写D
封锁协议
一级封锁协议
T在修改D之前加X锁,结束后释放
可以解决丢失修改
二级封锁协议
T在修改D之前加X锁,结束后释放;T在读取D之前加S锁,读取完释放
可以解决丢失修改+读“脏”数据
三级封锁协议
T在修改D之前加X锁,结束后释放;T在读取D之前加S锁,T结束后释放
可以解决丢失修改+读“脏”数据+不可重复读
活锁与死锁
活锁
多个事务排队执行,无优先级策略导致事务T之后的事务一直先于T执行,T一直等待,称为活锁
解决:采用“先来先服务”的策略
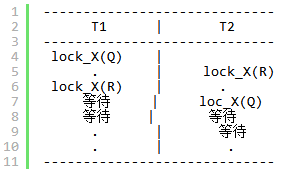
死锁
T1封锁了R1,T2封锁了R2,T1又请求封锁R2,T2又请求封锁R1,则处于死锁状态。
操作系统采用的解决方法
一次封锁法
要求每个事务必须一次将所有要使用的数据全部枷锁,否则不能继续。
缺点:降低了DBS并发度
顺序封锁发
预先对数据对象规定一个封锁顺序,所有事务按这个顺序实施封锁
缺点:维护资源封锁顺序成本太高
数据库采用的解决办法(诊断并解除死锁)
超时法
设置一个事务的等待时间,超过则认为死锁
缺点:等待时间不好设置
等待图法
并发控制子系统周期性地生成事务等待图,并进行检测,如果存在回路,则表明出现了死锁
可串行化调度
概念
多个事务通过某一调度策略来并发执行的结果要与按某一次序串行执行这些事务的结果相同。称这个调度策略为可串行化调度。
可串行性是并发事务调度的准则。
冲突操作
不同事务对同一个数据的读写操作和写写操作
冲突可串行化调度
一个调度Sc在保证冲突操作的次序不变的情况下,通过交换两个事务不冲突操作的次序得到另一个调度Sc',如果Sc'是串行的,则称调度Sc为冲突可串行化的调度。
Sc1=r1(A) w1(A) r2(A) w2(A) r1(B) w1(B) r2(B) w2(B)
可以通过调换两个事务的不冲突操作r2(A) w2(A) r1(B) w1(B),得到如下串行调度
Sc2= r1(A) w1(A) r1(B) w1(B) r2(A) w2(A) r2(B) w2(B)
则Sc1为冲突可串行化调度
冲突可串行化调度是可串行化调度的充分条件,不是必要条件。如下
L1=W1(Y) W1(X) W2(Y) W2(X) W3(X)是串行调度
L2= W1(Y) W2(Y)W1(X) W2(X) W3(X)是冲突可串行化调度,也是可串行化调度
L3= W1(Y) W2(Y W2(X))W1(X) W3(X)不是冲突可串行化调度,是可串行化调度
两段锁协议
作用:实现可串行化调度
原理:所有事务必须分两个阶段对数据项加锁和解锁。
在对任何数据进行读、写操作之前,首先获得锁;
在释放一个封锁之后,不能再申请任何形式的锁。
与一次封锁法异同:
两端所协议的加锁时间点可以不是同一时刻,而一次封锁法必须是同一时刻;
遵循两端所协议,依然有可能发生死锁。
封锁粒度
概念
封锁对象的大小称为封锁粒度。如属性值、元组、关系、索引等逻辑单元;或数据页、索引页、物理记录等物理单元。
封锁粒度越大,并发度越小,系统开销越小
多粒度封锁
多粒度树:根节点是整个数据库,叶结点是最小的数据粒度,注:最大最小自己控制。
多粒度封锁协议允许多粒度树中每个节点备独立加锁,但一个节点加锁意味着这个节点的所有后裔节点都被加以同样的锁
显式封锁:直接加到该数据对象上的锁
隐式封锁:由于上级节点加锁而导致该数据对象被加锁
意向锁
背景:由于检查显隐封锁的效率很低(显式需检查所有后裔节点,隐式需检查所有上级节点),所以引进意向锁。
概念:对任一节点加锁时,必须先对它的上层节点加意向锁。
类型
意向共享锁(IS锁)
对某节点加S锁,则对它的上层节点加IS锁
意向排它锁(IX锁)
对某节点加X锁,则对它的上层节点加IX锁
共享意向排它锁(SIX锁)
如果对某个表加SIX锁,表示该事务需要读整个表(所以整个表S锁),另要更新部分元组(所以要加IX锁)
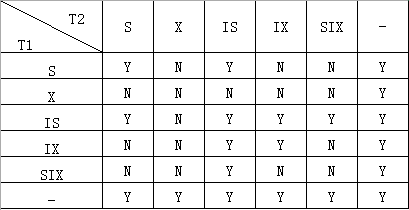
意向锁的相容矩阵