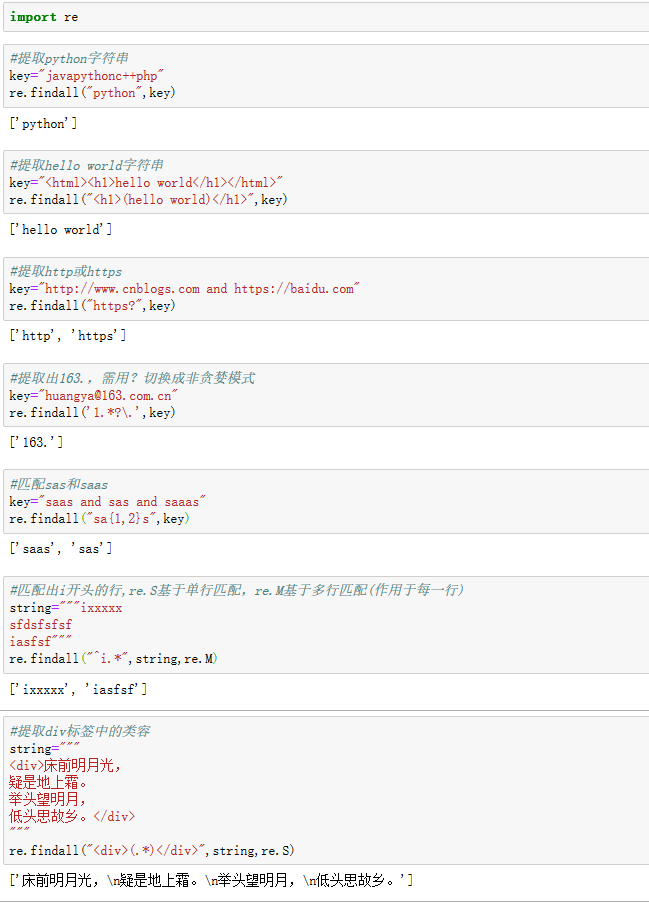
模块-re
常用表达式规则:
| . | 默认匹配除\n之外的任意一个字符,一个点代表一个字符,指定flag DOTA L L则匹配任意字符,包括换行 |
| ^ |
匹配字符串开头,若指定flag MULTILINE忽略换行符,也可匹配上(r'^a','\nabc\ndef') re.starch('^a','abcd')等效re.match('a','abcd') |
| $ |
匹配字符串结尾,指定flag MULTILINE,也可匹配re.search('a.$','a1\na2\na3\n) re.match('a$','a')只能匹配a,即以a开头并以a结尾,同一个a,也就只能匹配一个a |
| * | 匹配*号前一个字符0至多次,re.search('a*','aaabbaaaa')匹配到'aaa' |
| + | 匹配+号前一个字符1至多次,re.search('ba+',bbbbbabab')匹配到'baba' |
| ? | 匹配?号前一个字符0或1次,re.search('ba?','absba')匹配到'ba' |
| {m} | 匹配前一个字符m次,re.seatch('b{3}','dddaaabbbb')匹配到'bbb' |
| {n,m} | 匹配前一个字符n到m次,re.findall('ab{1,2}','ababvab')匹配到['abab','ab'],先匹配m个,m个配匹完后再匹配m-1个,直到m=n。即先最大化匹配 |
| | | 匹配|号左或右的字符,re.search('abc|Cd','abcdef')匹配到'abc','abCd'则匹配到Cd,要配匹到abcd或abCd则写成abcd|abCd,也可写成'ab[c|C]d' |
| (....) | 分组匹配,re.search("(abc){2}a(123|45)","abcabca456c").group()则配匹abcabca45或abcabca1245,用groups()则返回('abc', '45') |
| [0-9] | b表示0-9任意数字,[a-b],[A-B] |
| \A | 只从字符开头匹配,同^,类似match |
| \Z | 匹配字符串结尾,同$ |
| \d | s数字0-9,同[0-9] ,\d+配匹贪婪匹配,即匹配最多如re.search('\d+','123sdf')配匹到123而非1 |
| \D | 配匹非数字 |
| \w | 匹配[0-9A-Za-z],即除特殊字符 |
| \W | 匹配非[0-9A-Za-z],即特殊字符 |
| \s | 匹配配匹空白字符,\t,\n,\r |
| (?P<name>) | 分组匹配,分组并指定名称返回re.search("(?P<province>[0-9]{4})(?P<city>\d{3})",'1236527').group()返回1236527,groups()返回('1236', '527'),groupdict()返回字典{'province': '1236', 'city': '527'} |
re匹配语法:
- re.match从头开始匹配,第一个值开始匹配,只匹配一次,返回一对象,对象可用group()取值
- re.search全局匹配,找到就返回,只匹配一次。返回一对象,对象可用group()取值
- re.findall全局匹配,把所有匹配到的字符放到一个列表中返回
例:
s='123abc1234def'
match_res=re.match('[0-9]',s)
if match_res:
print(match_res.group())
- re.split以匹配到的字符当作列表分隔符
例:
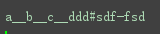
s='a123b456c789ddd#sdf-fsd'
print(re.split('\d+|#|-',s,maxsplit=None))
#maxsplit指定split多少次

- re.sub匹配字符并替换
例:
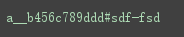
s='a123b456c789ddd#sdf-fsd'
print(re.sub('\d+','__',s))
例:提换指定个数
s='a123b456c789ddd#sdf-fsd'
#只替换一个
print(re.sub('\d+','__',s,count=1))
- re.fullmatch全部匹配,整个字符串配匹成功就返回re object,否则返回None
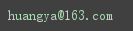
re.fullmatch('\w+@\w+\.(com|cn|edu)',"huangya@163.com").group()
- re.compile先将规则进行编译,再用对象去配匹。对于同一个规则匹配多次,速度会提高
例:
pattern=re.compile('\w+@\w+\.(com|cn|edu)')
pattern.fullmatch('huangya@163.com').group()
标识符
- re.I(re.IGNORECASE)忽略大小写
- re.M(MULTILINE)多行模式,改变'^'和'$'的行为
- re.S(DOTALL)改变'.'的行为,匹配包括换行符
- re.X(VERBOSE)可以给你的表达式写注释,使其更可读
练习