
第六节:查询操作(DQL)-单表/多表查询
一. 前言
1. 简介
就查询而言,可以简单的分为:单表查询 和 多表查询。
单表查询包括:简单查询、过滤查询、结果排序、分页查询、聚集函数。
多表查询包括:笛卡尔积、外键约束、内连接查询、外链接查询、自连接查询。
2. 数据准备
(1). 用到的表:
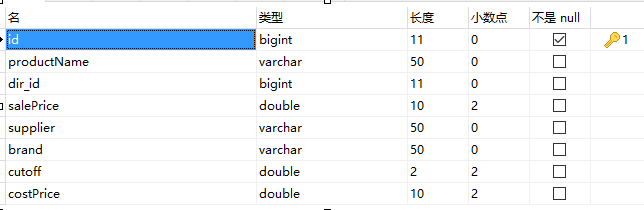
产品表(product)。包括:主键id、产品名称(productName)、分类编号(dir_id)、零售价(salePrice)、供应商(supplier)、品牌(brand)、折扣(cutoff)、成本价(costPrice)。
产品分类编号表( productdir)。 包括:主键id、编号名称( dirName)、父id( parent_id) 。
产品库存表( productstock)。包括:主键id、产品id( product_id )、库存数量( storeNum)、上次进库时间(lastIncomeDate)、上次出库时间( lastOutcomeDate)、预警数量(warningNum)。
(2). 对应的字段类型,如下图:

(3). 用到的SQL语句:
product表


CREATE TABLE `product` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `productName` varchar(50) DEFAULT NULL, `dir_id` bigint(11) DEFAULT NULL, `salePrice` double(10,2) DEFAULT NULL, `supplier` varchar(50) DEFAULT NULL, `brand` varchar(50) DEFAULT NULL, `cutoff` double(2,2) DEFAULT NULL, `costPrice` double(10,2) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=21 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of product -- ---------------------------- INSERT INTO `product` VALUES ('1', '罗技M90', '3', '90.00', '罗技', '罗技', '0.50', '35.00'); INSERT INTO `product` VALUES ('2', '罗技M100', '3', '49.00', '罗技', '罗技', '0.90', '33.00'); INSERT INTO `product` VALUES ('3', '罗技M115', '3', '99.00', '罗技', '罗技', '0.60', '38.00'); INSERT INTO `product` VALUES ('4', '罗技M125', '3', '80.00', '罗技', '罗技', '0.90', '39.00'); INSERT INTO `product` VALUES ('5', '罗技木星轨迹球', '3', '182.00', '罗技', '罗技', '0.80', '80.00'); INSERT INTO `product` VALUES ('6', '罗技火星轨迹球', '3', '349.00', '罗技', '罗技', '0.87', '290.00'); INSERT INTO `product` VALUES ('7', '罗技G9X', '3', '680.00', '罗技', '罗技', '0.70', '470.00'); INSERT INTO `product` VALUES ('8', '罗技M215', '2', '89.00', '罗技', '罗技', '0.79', '30.00'); INSERT INTO `product` VALUES ('9', '罗技M305', '2', '119.00', '罗技', '罗技', '0.82', '48.00'); INSERT INTO `product` VALUES ('10', '罗技M310', '2', '135.00', '罗技', '罗技', '0.92', '69.80'); INSERT INTO `product` VALUES ('11', '罗技M505', '2', '148.00', '罗技', '罗技', '0.92', '72.00'); INSERT INTO `product` VALUES ('12', '罗技M555', '2', '275.00', '罗技', '罗技', '0.88', '140.00'); INSERT INTO `product` VALUES ('13', '罗技M905', '2', '458.00', '罗技', '罗技', '0.88', '270.00'); INSERT INTO `product` VALUES ('14', '罗技MX1100', '2', '551.00', '罗技', '罗技', '0.76', '300.00'); INSERT INTO `product` VALUES ('15', '罗技M950', '2', '678.00', '罗技', '罗技', '0.78', '320.00'); INSERT INTO `product` VALUES ('16', '罗技MX Air', '2', '1299.00', '罗技', '罗技', '0.72', '400.00'); INSERT INTO `product` VALUES ('17', '罗技G1', '4', '155.00', '罗技', '罗技', '0.80', '49.00'); INSERT INTO `product` VALUES ('18', '罗技G3', '4', '229.00', '罗技', '罗技', '0.77', '96.00'); INSERT INTO `product` VALUES ('19', '罗技G500', '4', '399.00', '罗技', '罗技', '0.88', '130.00'); INSERT INTO `product` VALUES ('20', '罗技G700', '4', '699.00', '罗技', '罗技', '0.79', '278.00');
productdir表
CREATE TABLE `productdir` ( `id` bigint(11) NOT NULL auto_increment, `dirName` varchar(30) default NULL, `parent_id` bigint(11) default NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8; -- ---------------------------- -- Records -- ---------------------------- INSERT INTO `productdir` VALUES ('1', '鼠标', null); INSERT INTO `productdir` VALUES ('2', '无线鼠标', '1'); INSERT INTO `productdir` VALUES ('3', '有线鼠标', '1'); INSERT INTO `productdir` VALUES ('4', '游戏鼠标', '1');
productstock表
CREATE TABLE `productstock` ( `id` bigint(11) NOT NULL auto_increment, `product_id` bigint(11) default NULL, `storeNum` int(10) default NULL, `lastIncomeDate` datetime default NULL, `lastOutcomeDate` datetime default NULL, `warningNum` int(10) default NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8; -- ---------------------------- -- Records -- ---------------------------- INSERT INTO `productstock` VALUES ('1', '1', '182', '2015-03-12 20:33:00', '2015-03-12 20:33:04', '20'); INSERT INTO `productstock` VALUES ('2', '2', '27', '2015-03-02 20:33:28', '2015-03-09 20:33:40', '20'); INSERT INTO `productstock` VALUES ('3', '3', '89', '2015-02-28 20:34:13', '2015-03-12 20:34:19', '20'); INSERT INTO `productstock` VALUES ('4', '5', '19', '2015-03-01 20:34:43', '2015-03-12 20:34:48', '20'); INSERT INTO `productstock` VALUES ('5', '6', '3', '2015-02-01 20:35:12', '2015-03-02 20:35:16', '5'); INSERT INTO `productstock` VALUES ('6', '7', '2', '2015-02-02 20:35:59', '2015-02-27 20:36:05', '3'); INSERT INTO `productstock` VALUES ('7', '8', '120', '2015-03-12 20:36:31', '2015-03-12 20:36:33', '20'); INSERT INTO `productstock` VALUES ('8', '9', '58', '2015-03-02 20:36:50', '2015-03-12 20:36:53', '20'); INSERT INTO `productstock` VALUES ('9', '11', '28', '2015-03-02 20:37:12', '2015-03-12 20:37:15', '20'); INSERT INTO `productstock` VALUES ('10', '12', '8', '2015-03-02 20:37:35', '2015-03-09 20:37:38', '5'); INSERT INTO `productstock` VALUES ('11', '13', '3', '2015-03-02 20:37:58', '2015-03-12 20:38:01', '5'); INSERT INTO `productstock` VALUES ('12', '14', '6', '2015-03-02 20:38:20', '2015-03-07 20:38:23', '5'); INSERT INTO `productstock` VALUES ('13', '15', '2', '2015-02-02 20:38:38', '2015-02-24 20:38:44', '5'); INSERT INTO `productstock` VALUES ('14', '16', '3', '2015-02-02 20:39:05', '2015-02-06 20:39:09', '3'); INSERT INTO `productstock` VALUES ('15', '17', '49', '2015-03-02 20:39:36', '2015-03-12 20:39:40', '20'); INSERT INTO `productstock` VALUES ('16', '18', '14', '2015-03-02 20:39:57', '2015-03-09 20:40:01', '10'); INSERT INTO `productstock` VALUES ('17', '20', '7', '2015-03-02 20:40:22', '2015-03-03 20:40:25', '5');
二. 单表查询
1. 简单查询
a. 消除结果中的重复数据,用 DISTINCT 关键字。
b. 数学逻辑运算符(+ - * / ),运算符的优先级为:
(1). 乘除高于加减。
(2). 同级运算从左到右。
(3). 括号的优先级最高。
c. 设置列名的别名。
(1). 改变列的标题头,用 as 关键字,可以省略。
(2). 用于表示计算结果的含义。
(3). 如果别名中有特殊字符,或者轻质大小写敏感,或有空格是,都需要加双引号。
#1.需求:查询所有货品信息 select * from product #2.查询所有货品的id,productName,salePrice select id,productName,salePrice from product #3 需求:查询商品的分类编号。 SELECT DISTINCT dir_id FROM product
#需求:查询所有货品的id,名称和批发价(批发价=卖价*折扣) SELECT id,productName,salePrice*cutoff FROM product #需求:查询所有货品的id,名称,和各进50个的成本价(成本=costPirce) SELECT id,productName,costPrice*50 FROM product #需求:查询所有货品的id,名称,各进50个,并且每个运费1元的成本 SELECT id,productName,(costPrice+1)*50 FROM product
SELECT id,productName,(costPrice+1)*50 as pf FROM product SELECT id,productName,(costPrice+1)*50 pf FROM product SELECT id,productName,(costPrice+1)*50 "p f" FROM product
2. 过滤查询
a. SQL语句的执行顺序: FROM → WHERE → SELECT → ORDER BY。
b. 逻辑运算符:
(1). AND (&&) : 组合条件都为true,返回true。
(2). OR ( || ) : 组合条件之一为true, 就返回true。
(3). NOT ( ! ) : 组合条件都为false,返回true。
需求: 选择id,货品名称,批发价在300-400之间的货品 SELECT id productName,salePrice FROM product WHERE salePrice >=300 AND salePrice<=400 需求: 选择id,货品名称,分类编号为2,4的所有货品 SELECT id productName,salePrice FROM product WHERE dir_id=3 OR dir_id<=4 需求: 选择id,货品名词,分类编号不为2的所有商品 SELECT id productName,salePrice FROM product WHERE dir_id!=2 SELECT id productName,salePrice FROM product WHERE NOT dir_id=2 需求: 选择id,货品名称,分类编号的货品零售价大于等于250或者是成本大于等于200 SELECT id,productName,dir_id,salePrice,costPrice from product WHERE salePrice >=250 or costPrice>=200
c. 比较运算符:
(1). 等于: =
(2). 大于: >
(3). 大于或等于: >=
(4). 小于:<
(5). 小于或等于:<=
(6). 不等于: != 或 <>
注意:运算符的优先级由低到高:所有比较运算符 → NOT → AND → OR → 括号。
# 需求: 查询货品零售价为119的所有货品信息. SELECT * FROM product WHERE salePrice=119 #需求: 查询货品名为罗技G9X的所有货品信息. SELECT * FROM product WHERE productName='罗技G9X' SELECT * FROM product WHERE productName='罗技g9x' SELECT * FROM product WHERE BINARY productName='罗技g9x' #二进制区分大小写 #需求: 查询货品名 不为 罗技G9X的所有货品信息. SELECT * FROM product WHERE productName!='罗技G9X' SELECT * FROM product WHERE productName<>'罗技G9X' 需求: 查询分类编号不等于2的货品信息 SELECT * FROM product WHERE dir_id!=2 需求: 查询货品名称,零售价小于等于200的货品 SELECT productName FROM product WHERE salePrice<=200 需求: 查询id,货品名称,批发价大于350的货品 SELECT id,productName,salePrice *cutoff FROM product WHERE salePrice *cutoff >350 思考:使用where后面使用别名不行,总结select和where的执行顺序(思考下面两个都不好用的原因, 第二个是因为别名只能放在列名的后面) SELECT id,productName,salePrice *cutoff pf FROM product WHERE pf >350 SELECT id,productName, pf FROM product WHERE salePrice *cutoff pf >350
SELECT id,productName FROM product WHERE (NOT productName LIKE '%M%' AND salePrice > 100) OR (dir_id = 2)
d. 范围查询:BETWEEN AND 表示某一值域范围的记录。
格式: SELECT * FROM 表名 WHERE 列名 BETWEEN minvalue AND maxvalue; (两边都为闭区间)。
需求: 选择id,货品名称,批发价在300-400之间的货品 SELECT id,productName,salePrice FROM product WHERE salePrice BETWEEN 300 AND 400 需求: 选择id,货品名称,批发价不在300-400之间的货品 SELECT id,productName,salePrice FROM product WHERE NOT salePrice BETWEEN 300 AND 400
e. 集合查询:使用IN运算符,判断列的值是否在指定的集合中。
格式: WHERE 列名 IN ( 值1, 值2,....) 。
需求:选择id,货品名称,分类编号为2,4的所有货品 SELECT id productName,salePrice FROM product WHERE dir_id=2 OR dir_id=4 SELECT id productName,salePrice FROM product WHERE dir_id IN(2,4)
需求:选择id,货品名称,分类编号不为2,4的所有货品
SELECT id productName,salePrice FROM product WHERE NOT dir_id IN(2,4)
f. 空值判断:IS NULL,判断列的值是否为空。
格式:WHERE 列名 IS NULL。
--需求:查询商品名为NULL的所有商品信息。 SELECT * FROM product WHERE productName IS NULL
g. 模糊查询:使用 LIKE 运算符执行通配查询。
(1). %: 表示零或多个字符。
(2). _ : 表示一个字符。
需求: 查询id,货品名称,货品名称匹配'%罗技M9_' SELECT id, productName FROM product WHERE productName LIKE '%罗技M9_' 需求: 查询id,货品名称,分类编号,零售价大于等于200并且货品名称匹配'%罗技M1__' SELECT id,productName,dir_id FROM product WHERE productName LIKE '%罗技M9__' AND salePrice >=200
3. 结果排序
使用ORDER BY 子句进行排序,ASC: 升序 (默认,可省),DESC:降序;ORDER BY 子句出现在SELECT语句最后。
格式: SELECT *
FROM table_name
WHERE 条件
ORDER BY 列名1 [ASC/DESC] , 列名2 [ASC/DESC] .... 。
注意: 不能对使用了引号的别名进行排序。
#按照某一列来排序: #需求:选择id,货品名称,分类编号,零售价并且按零售价降序排序 SELECT id,productName,dir_id,salePrice from product ORDER BY salePrice DESC #按多列排序: #需求: 选择id,货品名称,分类编号,零售价先按分类编号排序,再按零售价排序 SELECT id,productName,dir_id,salePrice from product ORDER BY dir_id ASC,salePrice DESC #列的别名排序: #需求:查询M系列并按照批发价排序(加上别名) SELECT * ,salePrice * cutoff FROM product WHERE productName LIKE '%M%' ORDER BY salePrice * cutoff SELECT * ,salePrice * cutoff pf FROM product WHERE productName LIKE '%M%' ORDER BY pf #需求:查询分类为2并按照批发价排序(加上别名) SELECT * ,salePrice * cutoff "pf" FROM product WHERE dir_id=2 ORDER BY "pf"
4. 分页
(1). 真分页(物理分页、数据库分页):每次分页的时候,都从数据库中截取指定条数的数据。优点:不会内存溢出。缺点:复杂,翻页比较慢。
假分页(逻辑分页、内存分页):一次性把数据全部查出来,存在内存里,翻页的时候,从内存中截取指定条数即可。优点:简单,翻页快。缺点:若数据过多,可能内存溢出。
(2). MySQL中分页的写法:
格式:LIMIT beginIndex, pageSize ;
其中,beginIndex,表示从哪一个索引位置开始截取数据(索引是从0开始), pageSize,表示每页显示最多的条数
分页语句:SELECT * FROM 表名 LIMIT (currentPage-1)*pageSize,pageSize .
currentPage为当前页数,通常是前端传递过来的。
-- 分页 (获取的是 第11,12,13 条数据) SELECT * FROM product LIMIT 10,3
(3). SQLServer分页:
方案一:利用ROW_NUMBER() over() 和 between and,进行分页。ROW_NUMBER() over() 表示把该表按照某个字段进行排序,然后新生成一列,从1到n,如下图:
over里的排序要晚于外层 where,group by,order by
会按照over里面的排序,新增一列(1----n),比如 newRow, 然后基于这一列,使用between and 进行区间获取
可以将出来的数据进行排列1-----n,即多了一列
select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor
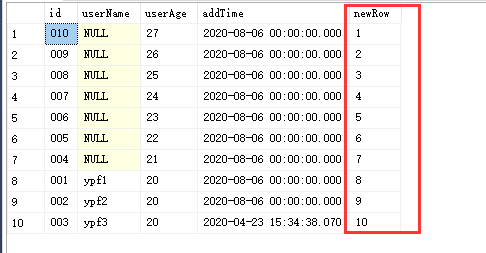
演变过程:
select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor select * from (select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor) as t select * from (select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor) as t where t.newRow between 1 and 2
方案2: 利用offset-fetch (SQLServer2012后开始支持),分页实现的思路:
--在分页实现中,使用Order By子句,按照指定的columns对结果集进行排序;
--使用offset子句跳过前N页:offset (@PageIndex-1)*@RowsPerPage rows;
--使用fetch子句取N页:fetch next @RowsPerPage rows only;
--跨过3行取剩下的 select * from UserInfor order by userAge desc offset 3 rows --跨过3行取剩下2行 select * from UserInfor order by userAge desc offset 3 rows fetch next 2 rows only
封装成存储过程:(这里基于方案一、方案二各一种,然后基于方案一写了一个万能的分页)
-- 基于"方案一"的存储过程分页 if (exists (select * from sys.objects where name = 'FenYe1')) drop proc FenYe1 go create proc FenYe1( @pageSize int=3, --输入参数:每页的条数,默认值为2 @pageIndex int=1, --输入参数:当前页数,默认值为1 @totalCount int output, --输出参数:总条数 @pageCount int output --输出参数:总页数 ) as select * from (select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor) as t where t.newRow between ((@pageIndex-1)*@pageSize)+1 and (@pageSize*@pageIndex); select @totalCount=COUNT(*) from UserInfor; set @pageCount=CEILING(@totalCount * 1.0 /@pageSize); --执行该分页的存储过程 declare @myTotalCount int, --声明变量用来接收存储过程中的输出参数 @myPageCount int --声明变量用来接收存储过程中的输出参数 exec FenYe1 2,1,@myTotalCount output,@myPageCount output; --每页2条,求第1页的数据 select @myTotalCount as '总条数',@myPageCount as '总页数'; -- 基于"方案二"的存储过程分页 if (exists (select * from sys.objects where name = 'FenYe2')) drop proc FenYe2 go create proc FenYe2( @pageSize int=3, --输入参数:每页的条数,默认值为2 @pageIndex int=1, --输入参数:当前页数,默认值为1 @totalCount int output, --输出参数:总条数 @pageCount int output --输出参数:总页数 ) as select * from UserInfor order by userAge desc offset (@pageIndex-1)*@pageSize rows fetch next @pageSize rows only; select @totalCount=COUNT(*) from UserInfor; set @pageCount=CEILING(@totalCount * 1.0 /@pageSize); --执行该分页的存储过程 declare @myTotalCount int, --声明变量用来接收存储过程中的输出参数 @myPageCount int --声明变量用来接收存储过程中的输出参数 exec FenYe2 4,2,@myTotalCount output,@myPageCount output; --每页4条,求第2页的数据 select @myTotalCount as '总条数',@myPageCount as '总页数'; --基于"方案一"创建一个万能表的分页 if (exists (select * from sys.objects where name = 'WangNengFenYe')) drop proc WangNengFenYe go create proc WangNengFenYe( @TableName varchar(50), --表名 @ReFieldsStr varchar(200) = '*', --字段名(全部字段为*) @OrderString varchar(200), --排序字段(必须!支持多字段不用加order by) @WhereString varchar(500) =N'', --条件语句(不用加where) @PageSize int, --每页多少条记录 @PageIndex int = 1 , --指定当前为第几页 @TotalRecord int output --返回总记录数 ) as begin --处理开始点和结束点 Declare @StartRecord int; Declare @EndRecord int; Declare @TotalCountSql nvarchar(500); Declare @SqlString nvarchar(2000); set @StartRecord = (@PageIndex-1)*@PageSize + 1 set @EndRecord = @StartRecord + @PageSize - 1 SET @TotalCountSql= N'select @TotalRecord = count(*) from ' + @TableName;--总记录数语句 SET @SqlString = N'(select row_number() over (order by '+ @OrderString +') as rowId,'+@ReFieldsStr+' from '+ @TableName;--查询语句 -- IF (@WhereString! = '' or @WhereString!=null) BEGIN SET @TotalCountSql=@TotalCountSql + ' where '+ @WhereString; SET @SqlString =@SqlString+ ' where '+ @WhereString; END --第一次执行得到 --IF(@TotalRecord is null) -- BEGIN EXEC sp_executesql @totalCountSql,N'@TotalRecord int out',@TotalRecord output;--返回总记录数 -- END ----执行主语句 set @SqlString ='select * from ' + @SqlString + ') as t where rowId between ' + ltrim(str(@StartRecord)) + ' and ' + ltrim(str(@EndRecord)); Exec(@SqlString) END --执行 --对UserInfor表进行分页,根据userAge排序,每页4条,求第2页的数据 declare @totalCount int exec WangNengFenYe 'UserInfor','*','userAge desc','',4,2,@totalCount output; select @totalCount as '总条数';--总记录数。
5. 聚集函数
(1). COUNT : 统计结果的记录数。
(2). MAX : 统计计算最大值。
(3). MIN : 统计最小值。
(4). SUM: 统计计算求和。
(5). AVG: 统计计算平均值。
需求:查询所有商品平均零售价 SELECT AVG(salePrice) FROM product 需求:查询商品总记录数(注意在Java中必须使用long接收) SELECT COUNT(id) FROM product 需求:查询分类为2的商品总数 SELECT COUNT(id) FROM product WHERE dir_id=2 需求:查询商品的最小零售价,最高零售价,以及所有商品零售价总和 SELECT MIN(salePrice) 最小零售价,MAX(salePrice) 最高零售价,SUM(salePrice) 商品零售价总和 FROM product
三. 多表查询
1. 笛卡尔积
多表查询会产生笛卡尔积。 假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)},实际运行环境下,应避免使用全笛卡尔集。
解决笛卡尔积最有效的方法:等值连接(是内连接的一种)。
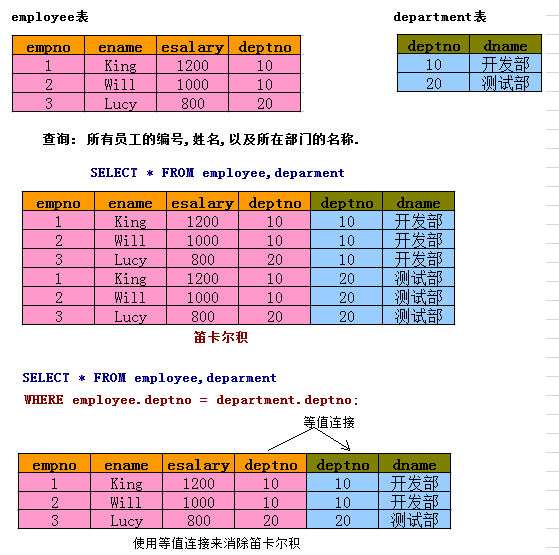
-- 需求:查询所有的货品信息+对应的货品分类信息 SELECT productName,dirName FROM product,productdir WHERE dir_id = productdir.id
2. 外键约束
(1). 主键约束(PRIMARY KEY): 约束在当前表中,指定列的值非空且唯一.
(2). 外键约束(FOREIGN KEY): A表中的外键列. A表中的外键列的值必须参照于B表中的某一列(B表主键).
注意:在MySQL中,InnoDB支持事务和外键.修改表的存储引擎为InnDB。格式:ALTER TABLE 表名 ENGINE='InnoDB'。

3. 说明
(1) 主表:数据可以独立存在,就是被参考的表。 productdir
(2). 从表:表中的数据,必须参照于主表的数据。product
注意:在删除表的时候,先删除从表,再删除主表。

3. 多表查询详解
多表查询包括三类:内连接查询(隐式内连接和显示内连接)、外连接查询 (左外链接、右外链接、全链接 )、自连接查询,各自的关系如下图:
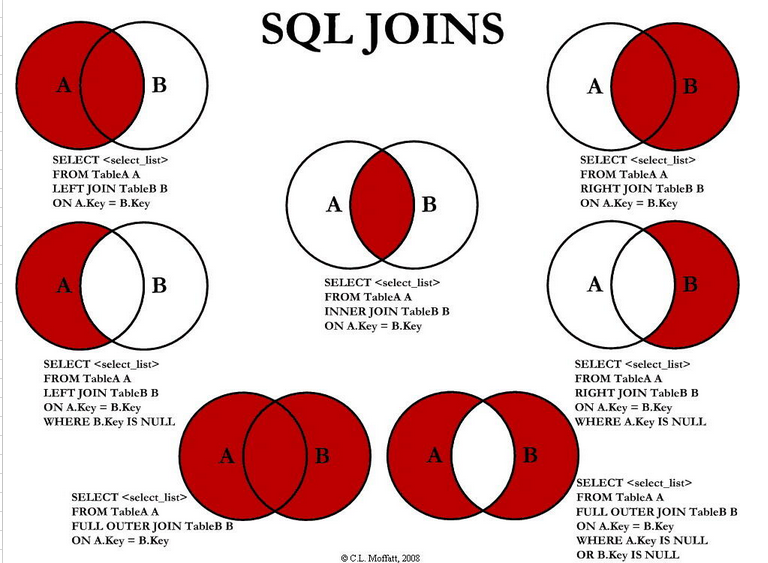
(1). 内连接
内连接查询出来的结果是多表交叉共有的,分为:隐式内连接和显示内连接。 还有一种划分方式,内连接分为:等值连接和非等值连接。
PS:不管是隐式内连接还是显示内连接, 当写法是 A.列 = B.列 的时候,就是等值连接;但如果写成 A.列!=B.列 就是非等值连接,所以说等值连接是内连接的子级。【如有出入,欢迎探讨】
A. 隐式内连接 (关键字 =)

B. 显示内连接 (关键字 inner join on,inner可以省略,推荐写法)

PS 在做等值连接的时候,若A表中的和B表中的列相同,可以缩写为:(MySQL特有)


需求:查询所有商品的名称和分类名称: 隐式内连接: SELECT p.productName,pd.dirName FROM product p,productdir pd WHERE p.dir_id = pd.id 显示内连接: SELECT p.productName,pd.dirName FROM product p INNER JOIN productdir pd ON p.dir_id = pd.id 显示内连接: SELECT p.productName,pd.dirName FROM product p JOIN productdir pd ON p.dir_id = pd.id 需求: 查询零售价大于200的无线鼠标 SELECT * FROM product p,productdir pd WHERE p.dir_id = pd.id AND p.salePrice >200 And pd.dirName ='无线鼠标' SELECT * FROM product p JOIN productdir pd on p.dir_id = pd.id WHERE p.salePrice >200 And pd.dirName ='无线鼠标' 需求: 查询每个货品对应的分类以及对应的库存 SELECT p.productName,pd.dirName,ps.storeNum FROM product p,productdir pd,productstock ps WHERE p.dir_id = pd.id AND p.id = ps.product_id SELECT p.productName,pd.dirName,ps.storeNum FROM product p JOIN productdir pd on p.dir_id = pd.id JOIN productstock ps on p.id = ps.product_id 需求: 如果库存货品都销售完成,按照利润从高到低查询货品名称,零售价,货品分类(三张表). select *, (p.salePrice - p.costPrice) * ps.storeNum lirun FROM product p,productdir pd,productstock ps WHERE p.dir_id = pd.id AND p.id = ps.product_id ORDER BY lirun DESC select *, (p.salePrice - p.costPrice) * ps.storeNum lirun FROM product p JOIN productdir pd on p.dir_id = pd.id JOIN productstock ps on p.id = ps.product_id ORDER BY lirun DESC
(2). 外连接查询
左外连接:查询出JOIN左边表的全部数据,JOIN右边的表不匹配的数据用NULL来填充,关键字:left join
右外连接:查询出JOIN右边表的全部数据,JOIN左边的表不匹配的数据用NULL来填充,关键字:right join
全连接: (左连接 - 内连接) +内连接 + (右连接 - 内连接) = 左连接+右连接-内连接 关键字:full join
PS: A LEFT JOIN B 等价于 B RIGHT JOIN A
注意:无论是内连接还是外连接,都要注意 1对多 的情况,查询出来的都是 左表的一条数据 对应 右表多条数据,即条数取决于右表。

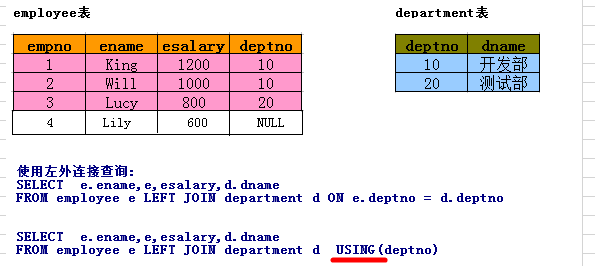
-- 外链接 # 查询所有商品的名称和分类名称 左连接: SELECT * FROM product p LEFT JOIN productdir pd ON p.dir_id = pd.id -- 等价于 SELECT * FROM productdir pd RIGHT JOIN product p ON p.dir_id = pd.id 右连接: SELECT * FROM product p RIGHT JOIN productdir pd ON p.dir_id = pd.id
(3). 自连接查询:把一张表看成两张表来做查询

三. 其它
1. group by 分组
SQL中的group By分组与linq、lambda完全不同,select指定的字段要么就要包含在group byy语句的后面,作为分组的依据;要么就要被包含在聚合函数中。常见的聚合函数有:count、sum、avg、min、max。
代码分享:
--根据用户性别分类,统计不同性别年龄最大值,年龄总和。 select userSex,MAX(userAge) as MaxAge,SUM(userAge) as TotalAges from Sys_UserInfor group by userSex
案例:要求输出每个用户的基本信息、所在的群总数、自己创建的群数、参与别人创建的群数
用到的表:


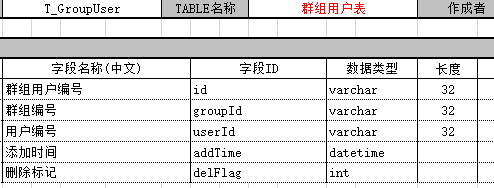
select t1.userPhone,t1.userNickName,t1.userType,TotalNum=ISNULL(t5.TotalNum,0) ,num1=ISNULL(t3.num1,0), num2=(ISNULL(t5.TotalNum,0)-ISNULL(t3.num1,0)) from T_ChatUser as t1 left join ( select t2.groupOwnerId as groupOwnerId , count(*) as num1 from T_ChatGroup as t2 group by t2.groupOwnerId ) as t3 on t1.id =t3.groupOwnerId left join ( select t4.userId, count(*) as TotalNum from T_GroupUser as t4 group by t4.userId ) as t5 on t1.id =t5.userId order by t1.addTime desc
!
- 作 者 : Yaopengfei(姚鹏飞)
- 博客地址 : http://www.cnblogs.com/yaopengfei/
- 声 明1 : 如有错误,欢迎讨论,请勿谩骂^_^。
- 声 明2 : 原创博客请在转载时保留原文链接或在文章开头加上本人博客地址,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号