
实用网页抓取
0、前言
本文主要介绍如何抓取网页中的内容、如何解决乱码问题、如何解决登录问题以及对所采集的数据进行处理显示的过程。效果如下所示:

1、下载网页并加载至HtmlAgilityPack
这里主要用WebClient类的DownloadString方法和HtmlAgilityPack中HtmlDocument类LoadHtml方法来实现。主要代码如下。
var url = page == 1 ? "http://www.cnblogs.com/" : "http://www.cnblogs.com/sitehome/p/" + page; var wc = new WebClient { BaseAddress = url, Encoding = Encoding.UTF8 }; var doc = new HtmlDocument(); var html = wc.DownloadString(url); doc.LoadHtml(html);
2、解决乱码问题
在抓取cnbeta的时候,我发现用上述方法抓取的html是乱码,开始我以为是网页编码问题,结果发现html网页是UTF-8格式,编码一致。最后发现原因是网页被压缩过,WebClient类不能处理被压缩过了网页,不过可以从WebClient类扩展出新的类,来支持网页压缩问题。核心代码如下,使用时用XWebClient替换WebClient即可。
public class XWebClient : WebClient {protected override WebRequest GetWebRequest(Uri address) { var request = base.GetWebRequest(address) as HttpWebRequest; request.AutomaticDecompression = DecompressionMethods.Deflate | DecompressionMethods.GZip;return request; } }
3、解决登录问题
某些网站的一些网页,需要登录才能查看,仅靠网址是没办法抓到的,这需要从html协议相关的知识了,不过这里不需要那么深的知识,先来一个具体的例子,先用chrome打开博客园、用F12或右键点击“审查元素”打开“开发者工具/Developer Tools”,选择“网路/Network”选项卡,刷新网页,点击开发者工具中的第一个请求,如下图所示:
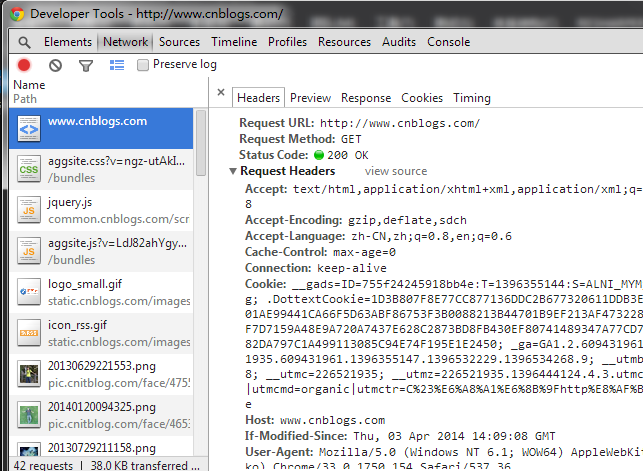
此时就可以看到刚才那次请求的请求头(Request Header)了,有兴趣的童鞋可以对照着http协议来查看每一个部分代表什么含义,而这里只关注其中的Cookie部分,这里包括了自动登录需要的信息,而回到问题,我不仅需要url,还需要携带cookie,而WebClient对象是没有Cookie相关的属性的,这时候又要扩展WebClient对象了。核心代码如下:
public class XWebClient : WebClient { public XWebClient() { Cookies = new CookieContainer(); } public CookieContainer Cookies { get; private set; } protected override WebRequest GetWebRequest(Uri address) { var request = base.GetWebRequest(address) as HttpWebRequest; request.AutomaticDecompression = DecompressionMethods.Deflate | DecompressionMethods.GZip; if (request.CookieContainer == null) { request.CookieContainer = Cookies; } return request; } }
这里GetWebRequest函数中获得WebRequest中的CookieContainer是null,所以我暴露了一个CookieContainer,用来添加Cookie,使用时调用其Add(new Cookie(string name, string value, string path, string domain))方法即可,这里path一般为“/”,domain为url,上图中的Cookie按分号分割,等号左边的就是name,右边的就是value。把所有的Cookie添加进去后,就可以抓取登录后的网页了。
4、Html解析
这里使用HtmlAgilityPack的HtmlDocument对象的DocumentNode.SelectSingleNode方法来选择元素,得到的HtmlNode对象取.Attributes["href"].Value即得到属性值,取InnerText即得到InnerText。
这里的SelectSingleNode方法是可以接收XPath作为参数的,而这可以大大简化解析难度。
在网页上的一个元素上悬停,右键点击“审查元素”,然后在被选中的那一块,右键点击“Copy XPath”,然后粘贴在SelectSingleNode方法的参数位置即可。对XPath感兴趣的童鞋,可以随便看看其它元素的XPath,观察XPath的语法规则。如果找不到某个元素对应的html节点,可以点击开发者工具左上角的放大镜,并在网页上点击该元素,其html节点就自动被选中了。
5、对采集的数据进行过滤和排序
这里用Linq to Objects就可以,这里是最有个性化的步骤,以博客园为例,可以对发布时间、点击数、顶的数目、评论数、top N等等进行过滤或排序,甚至对某某人进行屏蔽,非常自由。
我最后筛选出数据有三个属性:Text,为显示的文本,可以包含评论数、发表时间、标题之类的信息;Summary:为鼠标悬停时提示的文本;Url:为点击链接后用浏览器打开的网址。
6、显示
我采用Wpf作为UI,代码如下:
<Window x:Class="NewsCatcher.MainWindow" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" Title="MainWindow" Height="720" Width="1024" WindowStartupLocation="CenterScreen"> <ListView Name="listView"> <ListView.View> <GridView> <GridView.Columns> <GridViewColumn Header="新闻列表"> <GridViewColumn.CellTemplate> <DataTemplate> <TextBlock Width="960"> <Hyperlink NavigateUri="{Binding Url}" ToolTip="{Binding Summary}" RequestNavigate="Hyperlink_OnRequestNavigate"> <TextBlock FontSize="20" Text="{Binding Text}" /> </Hyperlink> </TextBlock> </DataTemplate> </GridViewColumn.CellTemplate> </GridViewColumn> </GridView.Columns> </GridView> </ListView.View> </ListView> </Window>
事件处理程序Hyperlink_OnRequestNavigate的代码如下,启用新进程使用默认浏览器来打开网站(如果不加那个参数,那么总是用IE打开网站):
private void Hyperlink_OnRequestNavigate(object sender, RequestNavigateEventArgs e) { (sender as Hyperlink).Foreground = Brushes.Red; var uri = e.Uri.AbsoluteUri; Process.Start(new ProcessStartInfo(WindowsHelper.GetDefaultBrowser(), uri)); e.Handled = true; }
WindowsHelper类的代码:
public static class WindowsHelper { private static string defaultBrowser; public static string GetDefaultBrowser() { if (defaultBrowser == null) { var key = Registry.ClassesRoot.OpenSubKey(@"http\shell\open\command\"); var s = key.GetValue("").ToString(); defaultBrowser = new string(s.SkipWhile(c => c != '"').Skip(1).TakeWhile(c => c != '"').ToArray()).Trim().Trim('"'); } return defaultBrowser; } }
7、使用.NET 4.5的异步特性来处理多个网站的加载问题
程序会自动记录浏览记录,且已浏览的链接不再显示出来。这里比较耗时的功能有:从xml文件中反序列化出历史数据、从各个网站下载并解析,它们是可以并行的,然而解析完成之后要排除历史数据中已有的数据,这个过程需要等待反序列化过程完成,代码如下:
deserialization = new Task(delegate { try { history = NEWSHISTORY_XML.Deserialize<List<HistoryItem>>(); history.RemoveAll(h => h.Time < DateTime.Now.AddDays(-7).ToInt32()); } catch (Exception) { history = new List<HistoryItem>(); } }); cnblogs = new Task(async delegate { try { var result = Cnblogs(); await deserialization; AddIfNotClicked(result); } catch (Exception exception) { itemsSource.Add(new ShowItem { Text = "Cnblogs Fails", Summary = exception.Message }); } listView.Dispatcher.Invoke(() => listView.Items.Refresh()); }); cnbeta = new Task(async delegate { try { var result = CnBeta(); await deserialization; AddIfNotClicked(result); } catch (Exception exception) { itemsSource.Add(new ShowItem { Text = "CnBeta Fails", Summary = exception.Message }); } listView.Dispatcher.Invoke(() => listView.Items.Refresh()); }); deserialization.Start(); cnblogs.Start(); cnbeta.Start();
private void AddIfNotClicked(IEnumerable<ShowItem> result) { foreach (var item in result.Where(i => history.All(h => h.Url != i.Url))) { itemsSource.Add(item); } }
itemsSource = new List<ShowItem>(); listView.ItemsSource = itemsSource;
8、结语
以上就是给自己经常访问的网站做信息抓取的实践了,实际上做出的东西对我来说是很有用的,我再也不会像以前那样,隔一会儿就要打开网站看追的美剧有没有更新了。对博客按推荐数排序,是一种比较高效的方式了。
由于代码中有我的Cookie,就不放出下载了。
应要求,给个demo,我把需要登录的哪些网站去掉了,保留了一个福利网站。
posted on 2014-04-03 23:43 yao2yao4 阅读(9021) 评论(21) 编辑 收藏 举报


