
【原创】构建高性能ASP.NET站点之一 剖析页面的处理过程(前端)
构建高性能ASP.NET站点之一 剖析页面的处理过程(前端)
前言:在对ASP.NET网站进行优化的时候,往往不是只是懂得ASP.NET就足够了的。 在优化的过程中,一般先是找出问题可能存在的地方,然后证明找出的问题就是要解决的问题,确认之后,在进行一些措施。系列文章在结构上的安排是这样的:先讲述前端的调优,我会在文章的标题后面标上”前端”,如果是后台代码的调优,我会在标题上标上”后端”,如果是数据库设计的调优,我会在标题上标上”数据库”,希望大家多多提建议。
系列文章链接:构建高性能ASP.NET站点之一 剖析页面的处理过程(前端)
构建高性能ASP.NET站点 第六章—性能瓶颈诊断与初步调优(上篇)—识别性能瓶颈
构建高性能ASP.NET站点 第六章—性能瓶颈诊断与初步调优(下前篇)—简单的优化措施
构建高性能ASP.NET站点 第六章—性能瓶颈诊断与初步调优(下后篇)—减少不必要的请求
构建高性能ASP.NET站点 第七章 如何解决内存的问题(前篇)—托管资源优化—垃圾回收机制深度剖析
构建高性能ASP.NET站点 第七章 如何解决内存的问题(前中篇)—托管资源优化—监测CLR性能
本篇主要剖析过程,让大家有个全面的了解,下一篇就开始分步剖析了。
本篇的议题如下:
剖析页面的解析过程
分析出可能存在的优化点
剖析页面的解析过程
页面的解析过程,这里说的过程不是我们常说的ASP.NET页面的生命周期的过程,而且浏览器请求一个页面,然后浏览器呈现页面的过程。
在本篇的文章中,我会先阐述页面的解析过程,显示从整体上阐述,然后在每一个点上提出优化的方法。先整体,后局部。
当浏览器在请求一个Web页面是从URL开始的。下面就是过程描述:
1. 输入URL地址或者点击URL的一个链接
2. 浏览器根据URL地址,结合DNS,解析出URL对应的IP地址
3. 发送HTTP请求
4. 开始连接请求的服务器并且请求相关的内容(至于请求时怎么被处理的,我们这里暂时不讨论,只是后面的文章要讨论的问题)
5. 浏览器解析从服务器端返回的内容,并且把页面显现出来,同时也继续进行其他的请求。
上面基本上就是一个页面被请求到现实的过程。下面我们就开始剖析这个过程。
当输入URL之后,浏览器就要知道这个URL对应的IP是什么,只有知道了IP地址,浏览器才能准备的把请求发送到指定的服务器的具体IP和端口号上面。
浏览器的DNS解析器负责把URL解析为正确的IP地址。这个解析的工作是要花时间的,而且这个解析的时间段内,浏览器不是能从服务器那里下载到任何的东西的。但是这个解析的过程是可以优化的。试想,如果每次浏览器每次请求一个URL都需要解析,那么每次的请求都有一点的时间消耗,可能这个时间消耗很短,但是性能的提升就是一点点的“调”出来的。如果把对应URL和IP地址缓存起来,那么当再次请求相同的URL时,浏览器就不用去解析,而是直接读取缓存,这样势必会快一点。
其实浏览器和操纵系统是提供了这样的支持的。
当获得了IP地址之后,那么浏览器就向服务器发送HTTP的请求,下面我们就稍微看下这个发送请求是怎么样被发送的:
1. 浏览器通过发送一个TCP的包,要求服务器打开连接
2. 服务器也通过发送一个包来应答客户端的浏览器,告诉浏览器连接开了。
3. 浏览器发送一个HTTP的GET请求,这个请求包含了很多的东西了,例如我们常见的cookie和其他的head头信息。
这样,一个请求就算是发过去了。
请求发送去之后,之后就是服务器的事情了,服务器端的程序,例如,浏览器清楚的文件是一个ASP.NET的页面,那么服务器端就把请求通过IIS交给ASP.NET 运行时,最后进行一系列的活动之后,把最后的结果,当然,一般是以是以html的形式发送到客户端。
其实首先到达浏览器的就是html的那些文档,所谓的html的文档,就是纯粹的html代码,不包含什么图片,脚本,css等的。也就是页面的html结构。因为此时返回的只是页面的html结构。这个html文档的发送到浏览器的时间是很短的,一般是占整个响应时间的10%左右。
这样之后,那么页面的基本的骨架就在浏览器中了,下一步就是浏览器解析页面的过程,也就是一步步从上到下的解析html的骨架了。
如果此时在html文档中,遇到了img标签,那么浏览器就会发送HTTP请求到这个img响应的URL地址去获取图片,然后呈现出来。如果在html文档中有很多的图片,flash,那么浏览器就会一个个的请求,然后呈现。
到这里,大家也许感觉到这种方式有点慢了。确实这个图片等资源文件的请求的部分也是可以优化的。暂不说别的,如果每个图片都要请求,那么就要进行之前说的那些步骤:解析url,打开tcp连接等等。开连接也是要消耗资源的,就像我们在进行数据库访问一样,我们也是尽可能的少开数据库连接,多用连接池中的连接。道理一样,tcp连接也是可以重用的。但是重用也有问题:如果两个图片它们的url地址如下:
 代码
代码

<img src="q2.gif" height="16" width="16" />
<img src="q3.gif" height="16" width="16" />
<img src="q4.gif" height="16" width="16" />
<img src="q5.gif" height="16" width="16" />
<img src="q6.gif" height="16" width="16" />
<img src="q7.gif" height="16" width="16" />
<img src="q8.gif" height="16" width="16" />
<img src="q9.gif" height="16" width="16" />
<img src="q10.gif" height="16" width="16" />
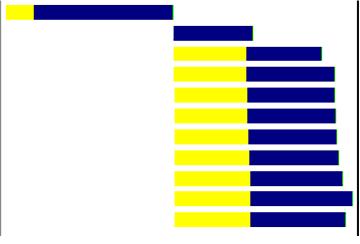
请求这些图片的时间消耗如下图:

大家首先看到最上面的黄线的部分,这个黄线就代表了浏览器打开连接,黄线的后半部分为蓝色,就表示浏览器请求到了html的文档。
最上面的第二条蓝线就表示第一个图片已经请求到了,此时请求这个图片使用还是之前的一个tcp的连接。
大家在看到第三条线,前部分是黄色的,表示请求第二个图片的时候又开了一个tcp的连接,这条线的后半部分为蓝色,表示图片已经请求到了。
剩下的要请求的一些图片都使用上一个tcp连接。
确实,tcp的连接时充分的被使用了,但是图片下载的速度确实慢了,从图中看出,图片是一个个的顺序的下载下来的。整个页面的响应时间可想而知。
如果采用下一种方式,如:
其实这就是一个权衡的问题了。
实际上浏览器也是内置了以一些优化方式的,例如缓存图片,脚本等。或者采用并行下载图片的方式,谈到并行下载,就如上图所看到的,势必会消耗更多的连接资源。
今天主要对页面的过程进行了初步的剖析,是的大家有个总体的把握,下一篇我们就开始逐步优化,敬请关注,也希望大家多多提出意见和反馈。先谢过了啊! :)
版权为小洋和博客园所有,欢迎转载,转载请标明出处给作者。
http://www.cnblogs.com/yanyangtian

