
JMeter学习(二十三)关联
话说LoadRunner有的一些功能,比如:参数化、检查点、集合点、关联,Jmeter也都有这些功能,只是功能可能稍弱一些,今天就关联来讲解一下。
JMeter的关联方法有两种:后置处理器-正则表达式提取器与XPath Extractor。
一、正则表达式提取器
1、添加正则表达式
在需要获得数据的上一个请求上右击添加一个后置处理器-->正则表达式提取器
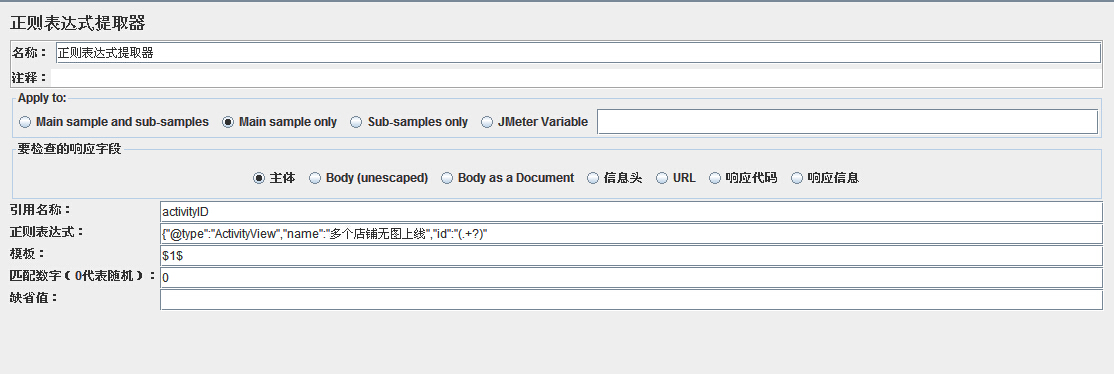
解释:
(1)引用名称:下一个请求要引用的参数名称,如填写activityID,则可用${activityID}引用它。
(2)正则表达式:
()括起来的部分就是要提取的。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式(多个括号括起来的东东),则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0,如果在LR中,取出的值是一个数组,还得处理一下,LR11版本用一个随机的函数就可以不用写大段的代码来处理数组。
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
2、关于正则表达式的举例说明
3、使用该关联的请求
如下图:
4、完整的例子:事例代码
二、XPath Extractor
XPath Extractor是另一个可被用来提取页面给定内容的Post Processor,XPath Extractor的使用方式与Regular Expression Extractor类似,只不过需要在该Extractor中指定的不是正则表达式,而是给定的XPath路径。
用xpath从前一个请求中取。这种形式比较适合于返回为xml片段的情况。在需要获得数据的请求上右击添加一个后置处理器-->xPath Extractor。引用名称即下一个请求要引用的参数名称,如填写body,则可用${body}引用它。
Xpath一般用于返回xml用得多。
XPath Extractor的设置界面:

l Use Tidy?:当需要处理的页面是HTML格式时,必须选中该选项,当需要处理的页面是XML或XHTML格式(例如,RSS返回)时,取消选中该选项。
l Reference Name:存放提取出的值的参数。
l XPath Query:用于提取值的XPath表达式。
l Default Value:参数的默认值。
三、小结这两种方式
正则表达式提取器和XPath Extractor都可以用来提取给定页面中的特定文本,并将其保存在参数中,这两种方式各有优缺点。
正则表达式提取器可以用于对页面任何文本的提取,提取的内容是根据正则表达式在页面内容中进行文本匹配;
而XPath Extractor则可以提取返回页面任意元素的任意属性。
相比较而言,
如果需要提取的文本是页面上某元素的属性值,建议使用XPath Extractor;
而如果需要提取的文本在页面上的位置不固定,或者不是元素的属性,建议使用正则表达式提取器。

