

Spark学习笔记(4)---Spark作业执行源码分析
作业执行源码分析
当我们的代码执行到了action(行动)操作之后就会触发作业运行。在Spark调度中最重要的是DAGScheduler和TaskScheduler两个调度器,其中,DAGScheduler负责任务的逻辑调度,
将作业拆分为不同阶段的具有依赖关系的任务集。TaskScheduler则负责具体任务的调度执行。
提交作业
WordCount.scala执行到wordSort.collect()才会触发作业执行,在RDD的源码的collect方法触发了SparkContext的runJob方法来提交作业。SparkContext的runJob方法经过几次调用后,
进入DAGScheduler的runJob方法,其中SparkContext中调用DAGScheduler类runJob方法代码如下:
def runJob[T, U: ClassTag](rdd: RDD[T],func: (TaskContext, Iterator[T]) => U,partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
...
// 调用DAGScheduler的runJob进行处理
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
// 做checkpoint,以后再说
rdd.doCheckpoint()
}
在DAGScheduler类内部会进行一列的方法调用,首先是在runJob方法里,调用submitJob方法来继续提交作业,这里会发生阻塞,知道返回作业完成或失败的结果;然后在submitJob方法里,创建了一个JobWaiter对象,
并借助内部消息处理进行把这个对象发送给DAGScheduler的内嵌类DAGSchedulerEventProcessLoop进行处理;最后在DAGSchedulerEventProcessLoop消息接收方法OnReceive中,接收到JobSubmitted样例类完成模式匹配后,
继续调用DAGScheduler的handleJobSubmitted方法来提交作业,在该方法中进行划分阶段。
def submitJob[T, U](rdd: RDD[T],func: (TaskContext, Iterator[T]) => U,partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
划分调度阶段
Spark调度阶段的划分是由DAGScheduler实现的,DAGScheduler会从最后一个RDD出发使用广度优先遍历整个依赖树,从而划分调度阶段,
调度阶段的划分是以是否为宽依赖进行的,即当某个RDD的操作是Shuffle时,以该Shuffle操作为界限划分成前后两个调度阶段
代码实现是在DAGScheduler的handleJobSubmitted方法中。
private[scheduler] def handleJobSubmitted(jobId: Int,finalRDD: RDD[_],func: (TaskContext, Iterator[_]) => _,partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
// 第一步:使用最后一个RDD创建一个finalStage
var finalStage: ResultStage = null
try {
// 创建一个stage,并将它加入DAGScheduler内部的内存缓冲中, newResultStage的时候就已经得到了他所有的ParentStage
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {...}
// 第二步:用finalStage,创建一个Job
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
// 第三步:将job加入内存缓存中
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 第四步:使用submitStage方法来提交最后一个stage,
// 最后的结果就是,第一个stage提交,其它stage都在等待队列中
submitStage(finalStage)
// 提交等待的stage
submitWaitingStages()
}
// newResultStage会调用getParentStagesAndId得到所有的父类stage以及它们的id
private def newResultStage(rdd: RDD[_],func: (TaskContext, Iterator[_]) => _,partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 得到所有的父stage
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
// 继续调用getParentStages
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId)
val id = nextStageId.getAndIncrement()
(parentStages, id)
}
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
// 所依赖RDD操作类型是ShuffleDependency,需要划分ShuffleMap调度阶段,
// 以getShuffleMapStage方法为入口,向前遍历划分调度阶段
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
// 从最后一个RDD向前遍历这个依赖树,如果该RDD依赖树存在ShuffleDependency的RDD,
// 则存在父调度阶段,反之,不存在
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
}
//
private def getShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _],firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => stage
case None =>
// We are going to register ancestor shuffle dependencies
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
if (!shuffleToMapStage.contains(dep.shuffleId)) {
// 如果shuffleToMapStage中没有,那么就new一个shuffleMapStage
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}
// 可以对比这个算法和getParentStages,该方法返回所有的宽依赖
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
val parents = new Stack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
for (dep <- r.dependencies) {
dep match {
// 所依赖RDD操作类型是ShuffleDependency,作为划分ShuffleMap调度阶段界限
case shufDep: ShuffleDependency[_, _, _] =>
if (!shuffleToMapStage.contains(shufDep.shuffleId)) {
parents.push(shufDep)
}
case _ =>
}
waitingForVisit.push(dep.rdd)
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents
}
只看代码还是会头大,我们结合一个图来讲解上面的代码:如下图,有7个RDD,分别是rddA~rddG,它们之间有5个操作,其划分调度阶段如下:
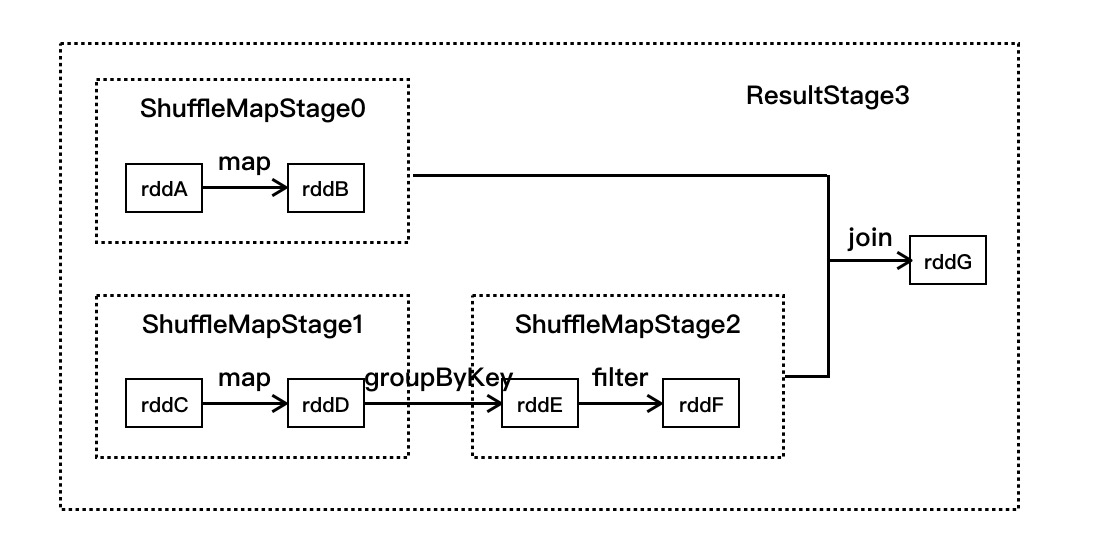
- 在SparkContext中提交运行时,会调用DAGScheduler的handleJobSubmitted进行处理,在该方法中会先找到最后一个RDD(即rddG),并调用getParentStages方法
- 在getParentStages方法判断rddG的依赖RDD树中是否存在shuffle操作,在该例子中发现join操作为shuffle操作,则获取该操作的RDD为rddB和rddF
- 使用getAncestorShuffleDependencies方法从rddB向前遍历,发现该依赖分支上没有其他的宽依赖,调用newOrUsedShuffleStage方法生成调度阶段ShuffleMapStage0
- 使用getAncestorShuffleDependencies方法从rddB向前遍历,发现groupByKey宽依赖操作,以此为分界划分rddC和rddD为ShuffleMapStage1, rddE和rddF为ShuffleMapStage2
- 最后生成rddG的ResultStage3。
总结,语句
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)在生成finalStage的同时,建立起所有调度阶段的依赖关系,最后通过finalStage生成一个作业实例,在该作业实例中按照顺序提交调度阶段进行执行。
提交调度阶段
通过handleJobSubmitted方法中的submitStage(finalStage)来提交作业。在submitStage方法中调用getMissingParentStages方法获取finalStage父调度阶段,如果不存在父调度阶段,则使用submitMissingTasks方法提交执行,如果存在父调度阶段,
则把该调度阶段存放到waitingStages列表中,同时递归调用submitStage。
/**
* 提交stage的方法
* stage划分算法的入口,stage划分算法是由submitStage()与getMissingParentStages()共同组成
*/
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// getMissingParentStages获取当前stage的父stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
// 直到最初的stage,它没有父stage,那么此时,就会去首先提交第一个stage,stage0
// 其余的stage,都在waitingStages里
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
// 递归调用submitStage方法去提交父stage
submitStage(parent)
}
// 并且当前stage放入waitingStages等待执行的stage队列中
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
// rdd的依赖
for (dep <- rdd.dependencies) {
dep match {
// 如果是宽依赖,那么就创建一个shuffleMapStage
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getShuffleMapStage(shufDep, stage.firstJobId)
// 判断是否可用,也就是判断父stage有没有结果, 看源码可以发现就是判断_numAvailableOutputs == numPartitions
// _numAvailableOutputs就是每个task成功后会+1
if (!mapStage.isAvailable) {
missing += mapStage
}
// 如果是窄依赖,那么将依赖的rdd放入栈中
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
// 首先往栈中推入了stage最后一个rdd
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}
同样的,我们画图来讲解提交调度阶段,如下图
提交任务
在submitStage中会执行submitMissingTasks方法中,会根据调度阶段partition个数生成对应个数task,这些任务组成一个任务集提交到TaskScheduler进行处理。
对于ResultStage生成ResultTask,对于ShuffleMapStage生成ShuffleMapTask。
private def submitMissingTasks(stage: Stage, jobId: Int) {
...
// 为stage创建指定数量的task
// 这里有一个很关键,就是task最佳位置的计算
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
// 给每个partition创建一个task
// 给每个task计算最佳位置
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics)
}
}
} catch {...}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
// 提交taskSet,Standalone模式,使用的是TaskSchedulerImpl
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
// 如果调度阶段不存在任务标记,则标记调度阶段已经完成
markStageAsFinished(stage, None)
...
}
}
当TaskSchedulerImpl收到发送过来的任务集时,在submitTasks方法中构建一个TaskSetManager的实例,用于管理这个任务集的生命周期,而该TaskSetManager会放入系统的调度池中,根据系统设置的调度算法进行调度,
TaskSchedulerImpl.submitTasks方法代码如下:
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 为每一个taskSet创建一个taskSetManager
// taskSetManager在后面负责,TaskSet的任务执行状况的监视和管理
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 把manager加入内存缓存中
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 将该任务集的管理器加入到系统调度池中,由系统统一调配,该调度器属于应用级别
// 支持FIFO和FAIR两种,默认FIFO
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
...
}
// 在创建SparkContext,创建TaskScheduler的时候,创建了StandaloneSchedulerBackend,这个backend是负责
// 创建AppClient,向Master注册Application的, 详见Spark运行时消息通信
backend.reviveOffers()
}
StandaloneSchedulerBackend的reviveOffers方法是继承于父类CoarseGrainedSchedulerBackend,该方法会向DriverEndpoint发送消息,调用makeOffers方法。在该方法中先会获取集群中可用的Executor,
然后发送到TaskSchedulerImpl中进行对任务集的任务分配运行资源,最后提交到launchTasks方法中。CoarseGrainedSchedulerBackend.DriverEndpoint.makeOffers代码如下:
private def makeOffers() {
// 获取集群中可用的Executor列表
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
// workOffers是每个Executor可用的cpu资源数量
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
// 第一步:调用TaskSchedulerImpl的resourceOffers()方法,执行任务分配算法,将各个task分配到executor上去
// 第二步:分配好task到executor之后,执行自己的launchTasks方法,将分配的task发送LaunchTask消息到对应executor上去,由executor启动并执行
launchTasks(scheduler.resourceOffers(workOffers))
}
第一步:在TaskSchedulerImpl的resourceOffers()方法里进行非常重要的步骤--资源分配, 在分配过程中会根据调度策略对TaskSetMannager进行排序,
然后依次对这些TaskSetManager按照就近原则分配资源,按照顺序为PROCESS_LOCAL NODE_LOCAL NO_PREF RACK_LOCAL ANY
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
for (o <- offers) {
executorIdToHost(o.executorId) = o.host
executorIdToTaskCount.getOrElseUpdate(o.executorId, 0)
if (!executorsByHost.contains(o.host)) {
executorsByHost(o.host) = new HashSet[String]()
executorAdded(o.executorId, o.host)
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// 首先,将可用的executor进行shuffle
val shuffledOffers = Random.shuffle(offers)
// tasks,是一个序列,其中的每个元素又是一个ArrayBuffer
// 并且每个子ArrayBuffer的数量是固定的,也就是这个executor可用的cpu数量
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
// 从rootPool中取出排序了的TaskSetManager
// 在创建完TaskScheduler StandaloneSchedulerBackend之后,会执行initialize()方法,其实会创建一个调度池
// 这里就是所有提交的TaskSetManager,首先会放入这个调度池中,然后再执行task分配算法的时候,会从这个调度池中,取出排好队的TaskSetManager
val sortedTaskSets = rootPool.getSortedTaskSetQueue
// 如果有新加入的Executor,需要重新计算数据本地性
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
// 对当前taskset尝试使用最小本地化级别,将taskset的task,在executor上进行启动
// 如果启动不了,就跳出这个do while,进入下一级本地化级别,一次类推
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
第二步:分配好资源的任务提交到CoarseGrainedSchedulerBackend的launchTasks方法中,在该方法中会把任务一个个发送到Worker节点上的CoarseGrainedExecutorBacken,
然后通过其内部的Executor来执行任务
// 根据分配好的tasks,在executor上启动相应的task
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 序列化
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = ...
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
} else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
// 向Worker节点的CoarseGrainedExecutorBackend发送消息执行Task
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
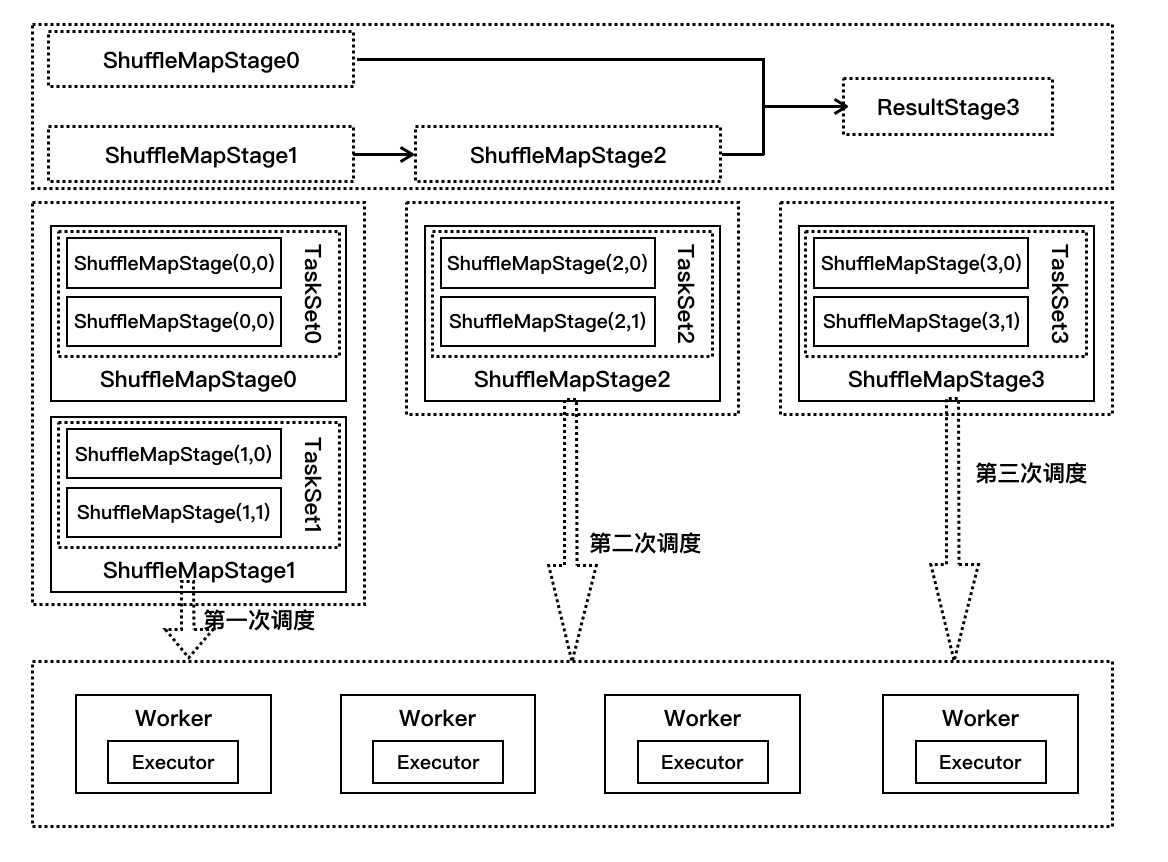
我们继续通过图解来解释以上代码的调用过程,如下图所示:

- 在提交stage中,第一次调用的是ShuffleMapStage0和ShuffleMapStage1,假设都只有两个partition,ShuffleMapStage0是TaskSet0,
ShuffleMapStage1是TaskSet1,每个TaskSet都有两个任务在执行。 - TaskScheduler收到发送过来的任务集TaskSet0和TaskSet1,在submitTasks方法中分别构建TaskSetManager0和TaskSetManager1,并把它们两放到系统的调度池,
根据系统设置的调度算法进行调度(FIFO或者FAIR) - 在TaskSchedulerImpl的resourceOffers方法中按照就近原则进行资源分配,使用CoarseGrainedSchedulerBackend的launchTasks方法把任务发送到Worker节点上的
CoarseGrainedExecutorBackend调用其Executor来执行任务 - 当ShuffleMapStage2同理,ResultStage3生成的是ResultTask
执行任务
当CoarseGrainedExecutorBackend接收到LaunchTask消息时,会调用Executor的launchTask方法进行处理。在Executor的launchTask方法中,初始化一个TaskRunner来封装任务,
它用于管理任务运行时的细节,再把TaskRunner对象放入到ThreadPool中去执行。TaskRunner.run的前半部分代码如下:
override def run(): Unit = {
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
val deserializeStartTime = System.currentTimeMillis()
// 设置当前类加载器,使用类加载器的原因,用反射的方式来动态加载一个类,然后创建这个类的对象
Thread.currentThread.setContextClassLoader(replClassLoader)
val ser = env.closureSerializer.newInstance()
logInfo(s"Running $taskName (TID $taskId)")
// 向DriverEndpoint发送状态更新信息
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
startGCTime = computeTotalGcTime()
try {
// 反序列化
val (taskFiles, taskJars, taskProps, taskBytes) =
Task.deserializeWithDependencies(serializedTask)
// Must be set before updateDependencies() is called, in case fetching dependencies
// requires access to properties contained within (e.g. for access control).
Executor.taskDeserializationProps.set(taskProps)
updateDependencies(taskFiles, taskJars)
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
task.localProperties = taskProps
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
if (killed) {
throw new TaskKilledException
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
var threwException = true
// value对于shuffleMapTask来说,其实就是MapStatus,封装了shuffleMapTask计算的数据,输出的位置
val value = try {
val res = task.run( // 具体实现在ShuffleMapTask和ResultTask中
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {...}
...
对于ShuffleMapTask, 它的计算结果会写到BlockManager之中,最终返回给DAGScheduler的是一个MapStatus。该对象管理了ShuffleMapTask的运算结果存储到BlockManager里的相关存储信息,而不是计算结果本身,
这些存储信息将会成为下一阶段的任务需要获得的输入数据时的依据。ShuffleMapTask.runTask代码如下:
override def runTask(context: TaskContext): MapStatus = {
// 反序列化获取rdd和rdd的依赖
// 通过broadcast variable拿到rdd的数据
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
var writer: ShuffleWriter[Any, Any] = null
try {
// 从shuffleManager中获取shuffleWriter
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
// rdd.iterator传入当前task要处理的哪个partition,执行我们自己定义的算子或者是函数
// 如果rdd已经cache或者checkpoint,那么直接读取,否则计算,计算结果保存在本地系统的blockmanager中
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
// 返回结果MapStatus,其实就是blockmanager相关信息
writer.stop(success = true).get
} catch {...}
ResultTask的runTask方法如下,它返回的是func函数的计算结果
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
func(context, rdd.iterator(partition, context))
}
获取执行结果
对于Executor的计算结果,会根据结果的大小有不同的策略
- 生成结果大于1GB,直接丢弃,可以通过spark.driver.maxResultSize来配置
- 生成结果大小在[128MB-200kB, 1GB], 会把结果以taskId为编号存入到BlockManager中,然后把编号通过Netty发送给DriverEndpoint,Netty传输框架最大值和预留空间的差值
- 生成结果大小在[0, 128MB-200KB],通过Netty直接发送到DriverEndpoint。
具体执行在TaskRunner的run方法后半部分:
// 对生成的结果序列化,并将结果放入DirectTaskResult中
val resultSer = env.serializer.newInstance()
val beforeSerialization = System.currentTimeMillis()
val valueBytes = resultSer.serialize(value)
val afterSerialization = System.currentTimeMillis()
// Note: accumulator updates must be collected after TaskMetrics is updated
val accumUpdates = task.collectAccumulatorUpdates()
val directResult = new DirectTaskResult(valueBytes, accumUpdates)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
if (maxResultSize > 0 && resultSize > maxResultSize) {
// 大于1G,直接丢弃
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
} else if (resultSize > maxDirectResultSize) {
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
// IndirectTaskResult间接结果
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
// 直接发送
serializedDirectResult
}
}
// CoraseGrainedExecutorBackend的statusUpdate方法
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {...}

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步