
向量时钟Vector Clock in Riak
Riak 是以 Erlang 编写的一个高度可扩展的分布式数据存储,Riak的实现是基于Amazon的Dynamo论文,Riak的设计目标之一就是高可用。Riak支持多节点构建的系统,每次读写请求不需要集群内所有节点参与也能胜任。像这样的系统,我们需要版本机制来确定哪个值是最新的。所以就引入了向量时钟(Vector Clock)
当存储一个对象到Riak时,都被打上向量时钟标签。通过向量空间祖先继承的关系比较,Riak可以自动的修复不同步的值,使数据保持最终一致性。
向量时钟的作用
有个比较经典的例子,说明向量时钟的作用。假设有如下场景:
Alice、Ben、Catby和Dave四人约定下周一起聚餐,四个人通过邮件商量聚餐的时间。
Alice首先建议周三聚餐。
之后Dave和Catby商量觉得周四更合适。
后来Dave又和Ben商量之后觉得周二也行。
最后Alice要汇总大家的意见,得到的反馈如下:
Cathy说,他和Dave商量的时间是周四
Ben说,他和Dave商量的时间是周三
此时恰好联系不上Dave,而且不知道Cathy和Ben分别与Dave确定时间的先后顺序,Alice就不能确定到底该定在哪天了。
Vector Clock就是为了解决这种问题而设计的,简单来说,就是为每个商议结果加上一个时间戳,当结果改变时,更新时间戳。所以加上时间戳之后,我们再一次描述上面的场景,如下:
当Alice第一次提议将时间定为周三时,可以这样描述信息 date = Wednesday vclock = Alice:1 其他三个人都收到了信息,Dave和Ben开始交流,Ben建议改成周二,把Alice的初试向量加进去标识Ben看到Alice的消息了 date = Tuesday vclock = Alice:1, Ben:1 Dave回复Ben,确定周二可以 date = Tuesday vclock = Alice:1, Ben:1, Dave:1 然后Cathy开始说话,也和Dave说建议周四,此时在Dave看来就收到了两个数据如下: date = Tuesday vclock = Alice:1, Ben:1, Dave:1 date = Thursday vclock = Alice:1, Cathy:1 这两份数据,各自都不是互相的祖先,所以就产生了冲突,Dave要自动解决这个冲突,他选择了周四,然后将消息改成如下,继承来自Dave现在收到的两条消息,这个消息发回给Cathy date = Thursday vclock = Alice:1, Ben:1, Cathy:1, Dave:2 最后来了,Alice只问Ben和Cathy最后的决定: Ben说 date = Tuesday vclock = Alice:1, Ben:1, Dave:1 Cathy说 date = Thursday vclock = Alice:1, Ben:1, Cathy:1, Dave:2 Alice就明白了,因为第二个Cathy说的是完全继承于Ben说的,所以最后采纳Cathy说的决定,周四去。
以上这个决策用到了向量时钟,有个图还比较清晰了说明整个过程:

向量时钟的空间无限增长问题
以上的做法还比较完美的解决了问题,这里只列举了四个决策者的向量时钟,不过在现实生活中,如果有很多的决策者,相当于有很多的客户端,整个向量时钟的长度就无限制增长了,这对于存储系统来说,不是一个好消息。我们需要想办法解决。
一个直接的想法是,不要用client来标识向量空间,用server来标识向量空间,因为server的数量是可控的,这里用X,Y两台server来重现以上决策的过程,只是标签不再用客户端,而是用server标识,决策过程如下
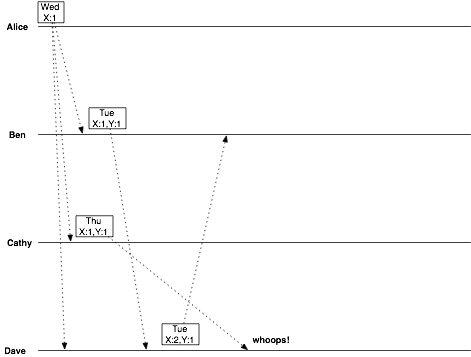
此时Dave收到两个消息
Tue X:2,Y:1 with Ben
Thu X:1,Y1 from Cathy (这个消息比较新)
发现后者是前者的祖先,所以自然抛弃祖先,最终最新的,这样就悄无声息的把Cathy给他的消息给丢了。
所以尝试用server来做标识,以期减少向量时钟的空间是不可取的,因为会丢数据。实际情况还是需要用客户端的标识来做向量时钟。
向量时钟的剪枝
所以为了解决向量时钟空间的无限增长问题,引入了向量时钟的剪枝。
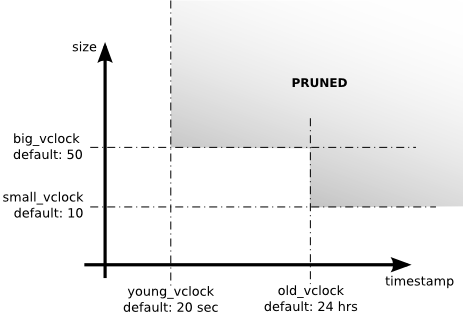
Riak用四个参数来避免向量时钟空间的无限增长:
small_vclockbig_vclockyoung_vclockold_vclock
small_vclock和big_vclock参数标识向量时钟的长度,如果长度小于small_vclock就不会被剪枝掉,如果长度大于big_vclock就会被剪枝掉
young_vclock和old_vclock参数标识存储这个向量时钟时的时间戳,剪枝策略同理,大于old_vclock的才会被剪枝掉,剪枝策略如下图
这样只会丢掉一些向量时钟的信息,即数据更新过程的信息,但是不会丢掉实实在在的数据。只有当一种情况会有问题,就是一个客户端保持了一个很久之前的向量时钟,然后继承于这个向量时钟提交了一个数据,此时就会有冲突,因为服务器这边已经没有这个很久之前的向量时钟信息了,已经被剪枝掉了可能,所以客户端提交的此次数据,在服务端无法找到一个祖先,此时就会创建一个sibling。
所以这个剪枝的策略是一个权衡tradeoff,一方面是无限增长的向量时钟的空间,另一方面是偶尔的会有"false merge",对,但肯定的是,不会悄无声息的丢数据。综上,为了防止向量时钟空间的无限增长,剪枝还是比用server标识向量时钟工作的更好。
参考:
http://docs.basho.com/riak/latest/theory/concepts/Vector-Clocks/
http://basho.com/why-vector-clocks-are-easy/
http://basho.com/why-vector-clocks-are-hard/
《大型网站系统与Java中间件实践》

