springboot三:SpringBoot Web开发
上一篇:springboot二:SpringBoot和Spring配置的区别。
一、SpringBoot整合Servlet
SpringBoot中整合Servlet有两种方式。
方式一:
①:首先创建一个IndexServlet类并且继承HttpServlet,并按照需要实现其方法,doGet()/doPost()。
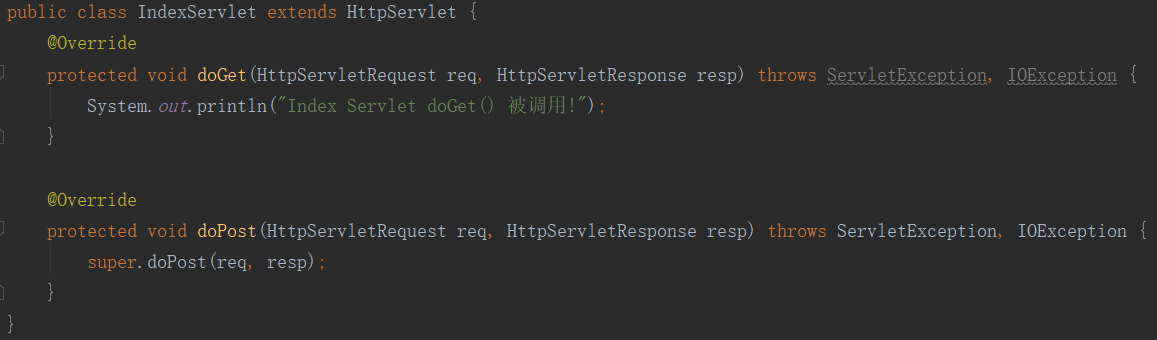
②:然后在IndexServlet类上使用@WebServlet注解,并使用urlPatterns来映射地址。
③:凡是使用了注解@WebServlet或者@WebFilter等,启动类需要找到这些类,那么需要一个扫描注解。
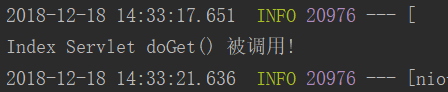
在启动类上添加@ServletComponentScan注解,运行启动类,使用浏览器访问http://localhost:8080/index.html后控制台输出如下结果。
方式二:
在已经创建好IndexServlet的前提下,我们在启动类自己定义组件(去掉方式中的注解)。因为是Servlet,我们使用ServletRegistrationBean这个类,并且使用@Bean注解将其注入容器。然后运行访问index.html能够输出如上结果。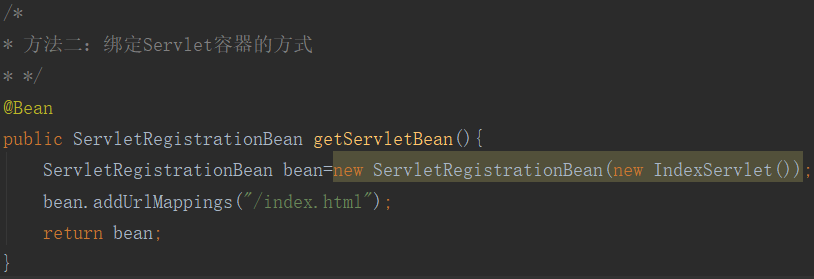
二、SpringBoot整合Filter
Filter是拦截器,他会根据绑定的Url去拦截具体的地址,然后做相应的处理,过滤一些不需要的内容,在SpringBoot中整合Filter和Servlet一样有两种方式。
方式一:
①:和Servlet一样创建一个IndexFilter类实现Filter接口。在Filter接口中有三个方法:init(),doFilter(),destory()。init和destory就是filter的初始化方法和销毁方法,我们在拦截器中需要进行拦截写的逻辑代码在doFilter()中。
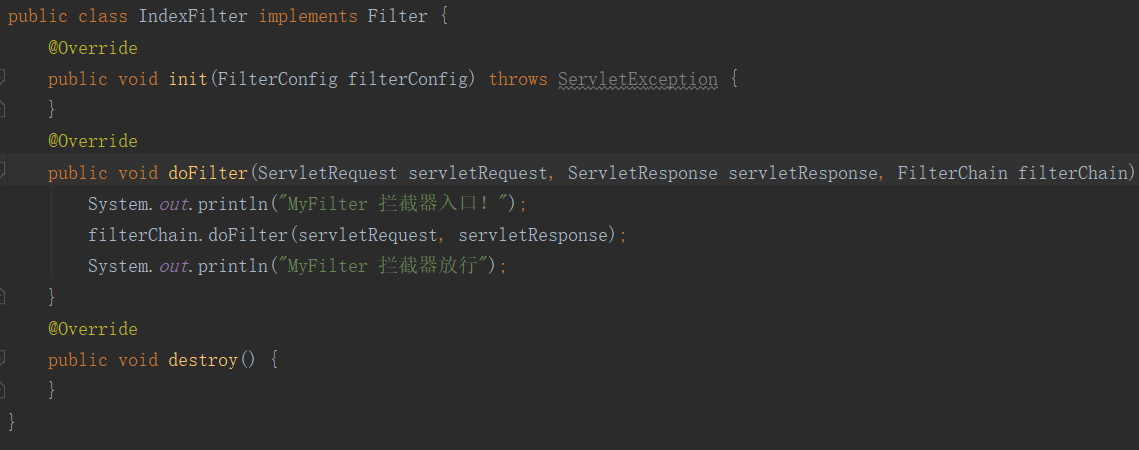
②:在IndexFilter类上使用@WebFilter注解。其中urlPatterns是绑定的拦截地址。

③:和servlet一样,需要在启动类添加扫描注解@ServletComponentScan。完成后运行启动类,访问http://localhost:8080/index.html,控制台输出如下结果。

方式二:
和Servlet类似,在启动类自己添加组件,这是是Filter,所以使用的类是FilterRegistrationBean。
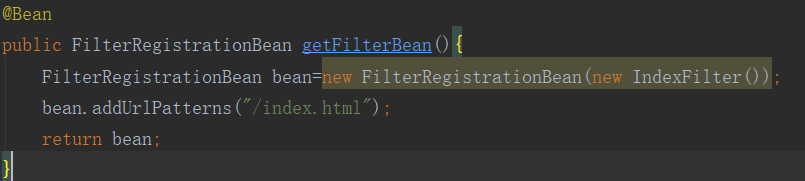
注意:我们在拦截器拦截Url地址的时候,通常不是拦截一个,我们会拦截对个,会将urlPatterns="/*"这种形式。
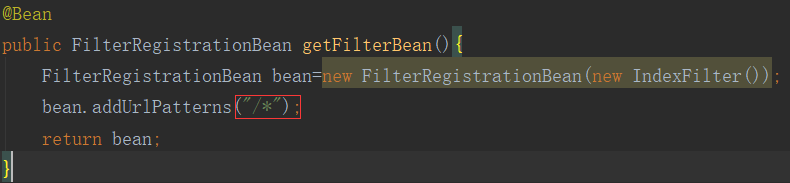
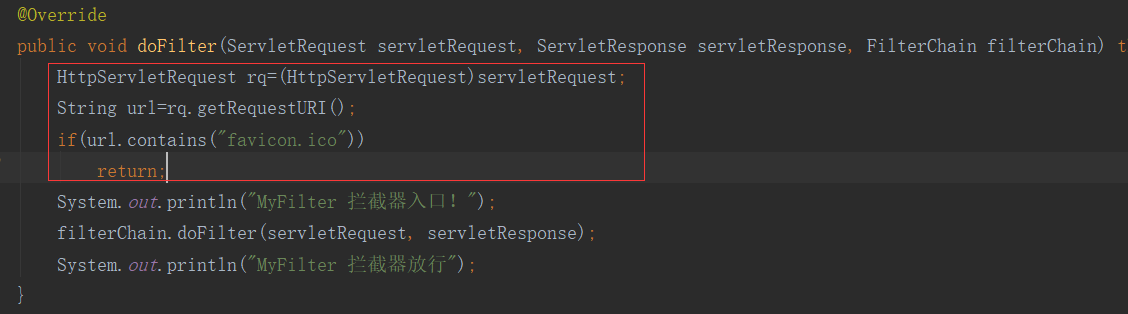
但是会出现一个问题,在谷歌浏览器会出现多出来的一个空拦截,但是在火狐上不会。但是这是什么原因呢?因为,在谷歌浏览器中,除了普通的地址被拦截外,还会拦截网站的图标favicon.ico。为了避免这个,我们在Filter的类的doFilter()做一个优化如下。然后就没有这个问题了。

三、springBoot整合Listener
常用的web事件的监听接口如下:
ServletContextListener:用于监听Web的启动和关闭。
ServletContextAttributeListener:用于监听ServletContext范围内属性的改变。
ServletRequestListener:用于监听用户请求。
ServletRequestAttributeListener:用于监听ServletRequest范围属性的改变。
HttpSessionListener:用于监听用户session的开始和结束。
HttpSessionAttributeListener:用于监听HttpSession范围的属性的改变。
SpringBoot整合Listener和前面Servlet、Filter一样。我们以ServletContextListener为例:
方式一:新建MyListener实现接口ServletContextListener。
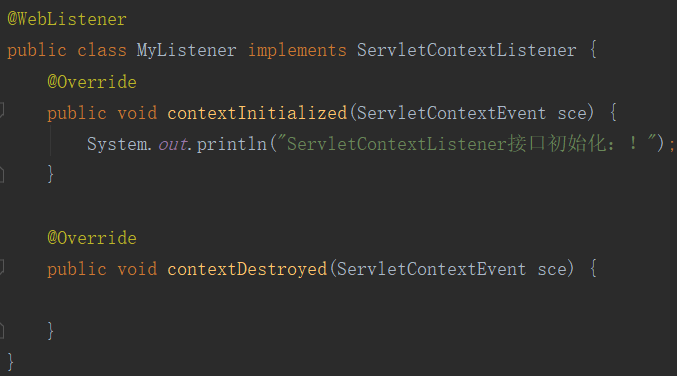
方式二:在启动类手动添加组件,启动启动类时会出现初始化信息。

四、SpringBoot访问web中的静态资源常见的目录结构
①:classpath:/META-INF/resources/
②:classpath: /resources/
③:classpath:/static/ 这个是常见项目自动生成的类,用得最多的目录。
④:classpath:/public/
⑤:/ 当前项目的根目录。
⑥:src/main/webapp 我们常用的jsp就是放在这里。
五、SpringBoot整合web中的jsp模板
SpringBoot 官方是不推荐使用Jsp这个引擎模板的,所以他的默认配置中没有配置的Jsp支持。如果要使用Jsp那么需要添加jsp的依赖包:jstl标签和jsp引擎。
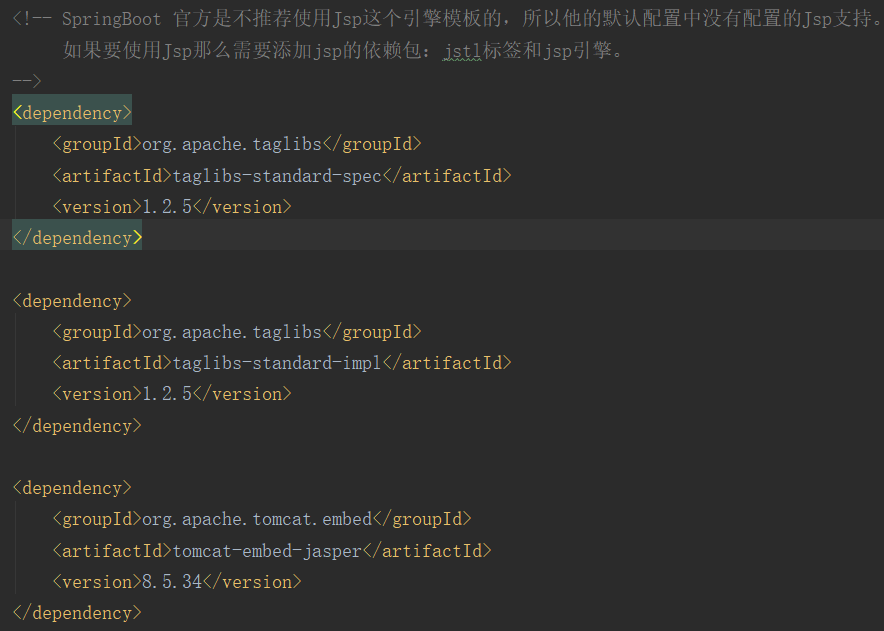
我们需要在全局配置文件中配置jsp的头和尾信息。在main目录下创建webapp/WEB-INF/jsp目录存放我们的jsp文件。具体使用和spring中一样。Controller中的@RequestMapping注解就可以。
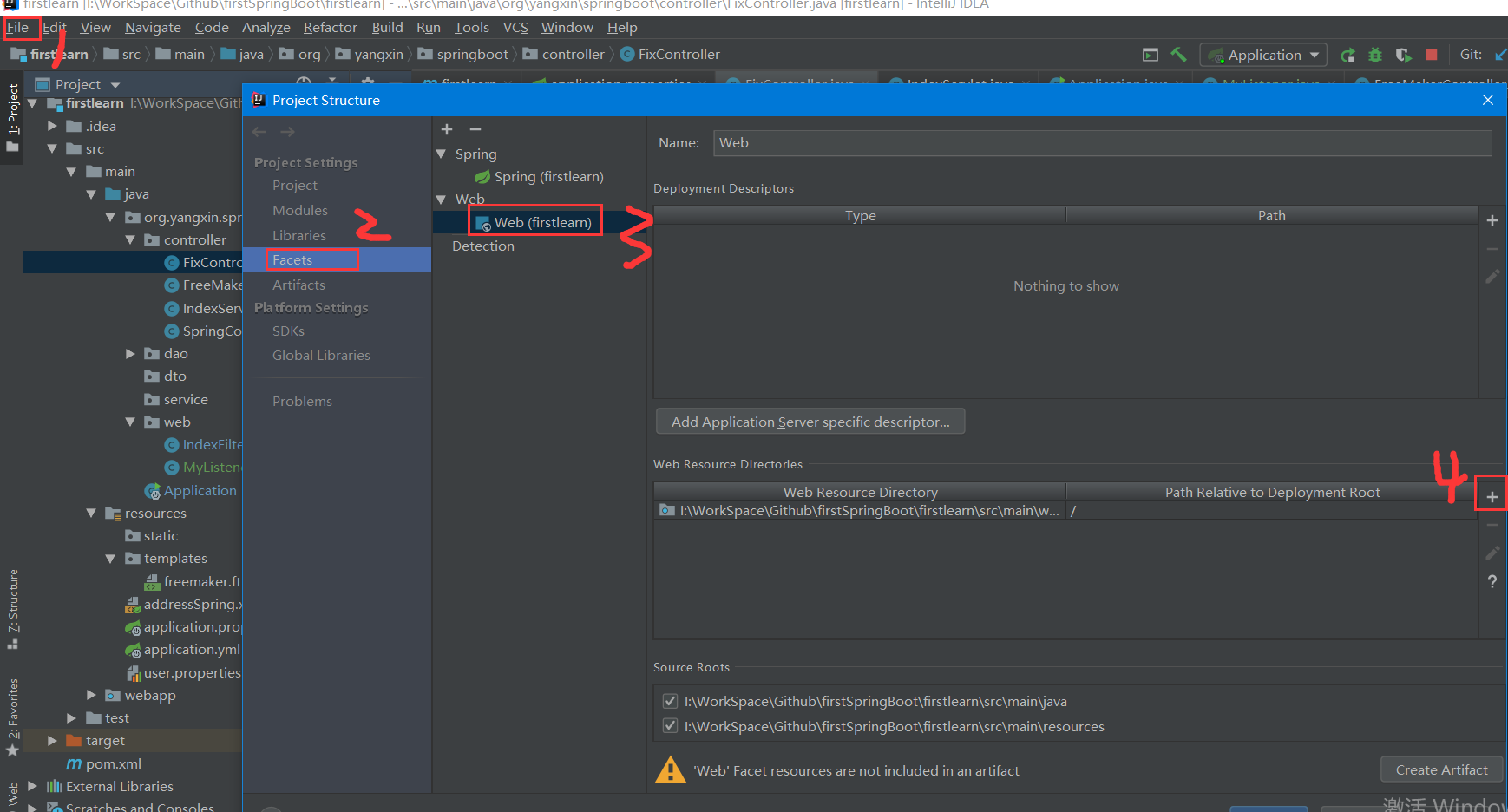
注意:在创建的webapp/WEB-INF/jsp中,没有创建Jsp的选项的解决方法。
在file->project structure->facets->Web->Web Resource Directories哪儿点击+号,把创建的路径添加进来,就可以创建了。
六、FreeMaker
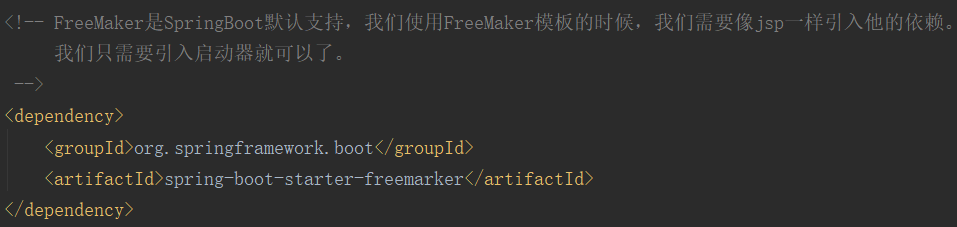
freeMaker和Jsp一样是一种页面视图模板,springBoot默认就支持这个模板。
使用FreeMaker步骤:
①:配置freeMaker依赖:
②:创建Controller,使用@RequestMapping指向路径:
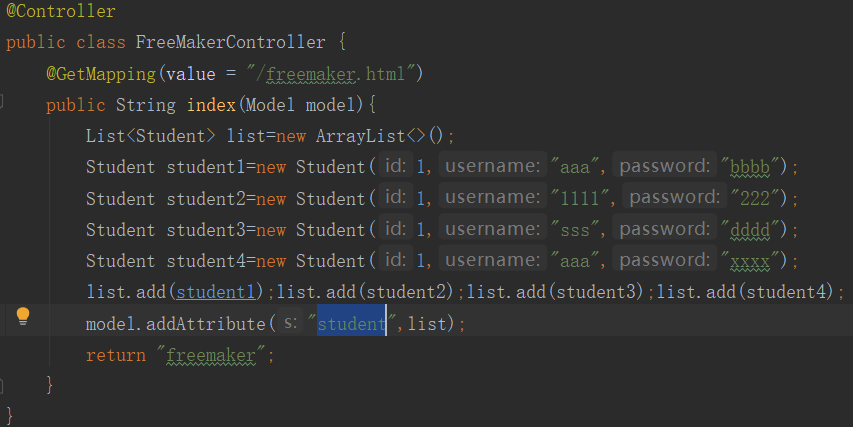
③:再在templates中new一个html,由于FreeMaker的后缀是.ftl,所以讲后缀.html改为.ftl。
④:启动启动类,运行结果:没有任何样式很丑。
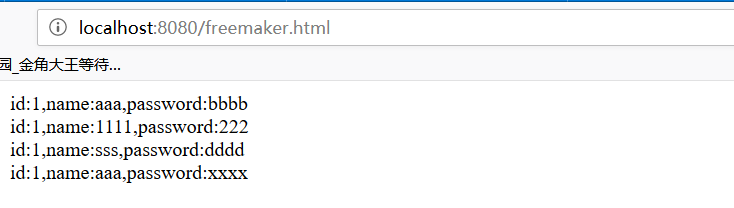
在FreeMaker中是像Jsp中的<c:foreach>的语法,<#list> <#if>........更多语法参考:http://freemarker.foofun.cn/dgui_quickstart_basics.html官网。
七、Thymeleaf
thymeleaf是springBoot有一个默认支持的视图,使用他要引入thymeleaf的依赖。除此外使用和其他的模板区别不大。

但是他有着自己的输入输出格式。thymeleaf也是使用${}的形式,但是有极大的区别:1.thymeleaf依附于某个标签显示,<div th:text="${student.id}"></div>。2.如果想独立的显示,那么需要使用[[${}}]]这样的形式显示。
thymeleaf常用的标签语法总结:
①:变量的输出和字符串的操作:th:text在页面上输出结果,会把特殊字符转义输出,[[]]与此等价;th:utext:在页面上输出值,不会把特殊字符转义,[()]与此等价;th:value:在input中显示数值。
②:#表示在thymeleaf中表示调用内置对象,dates,strings.....
③:分支:th:if、th:switch、th:each。
八、扩展SpringBoot中的SpringMvc的默认配置
如果我们的controller中配置springmvc不做任何操作,只是返回一个视图。我们在SpringMvc中是使用<mvc:view-controller path="/index.html" view-name="index"/>。
但是在SpringBoot中建议使用注解完成一切的配置。我们创建一个Config配置类,继承WebMvcConfigurationSupport。效果是一样的。
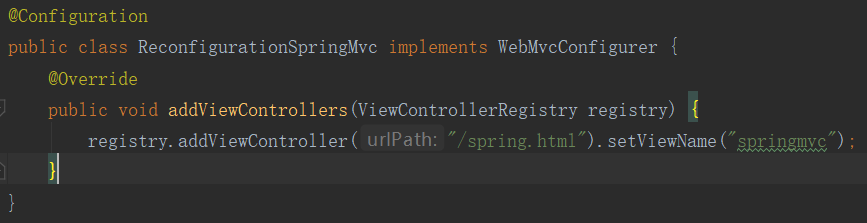
@EnableWebMvc:我们在上面的方式是,在SpringBoot原有的配置生效,然后加上我们现在的配置一起生效的作用;但是@EnableWebMvc的作用是,让SpringBoot里的默认配置全部失效,配置这个注解后,只有我们配置的配置才生效,那么就回到原来的springmvc的情况了。
八、springBoot整合JDBC
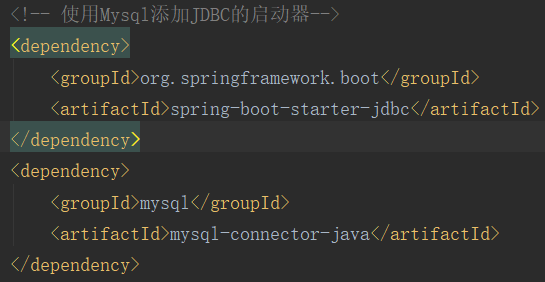
①:导入JDBC所需要的必要启动器和依赖。
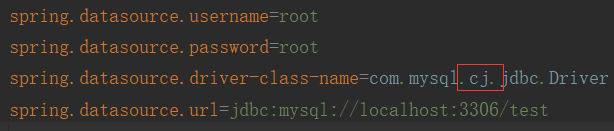
②:配置数据库的属性:在全局配置文件中配置:在一般配置driver都是com.mysql.jdbc.Driver,但是在SpringBoot的新版本中,配置驱动需要加上com.mysql.cj.jdbc.Driver。在SpringBoot中的数据源都是默认配置的,不像我们在Spring中需要自己配置dataSource、sqlSessionFactory等配置。
注意:SpringBoot2.0后默认使用的是HikariDataSource这个数据源,据说性能上是c3p0的25倍。
③:测试连接信息
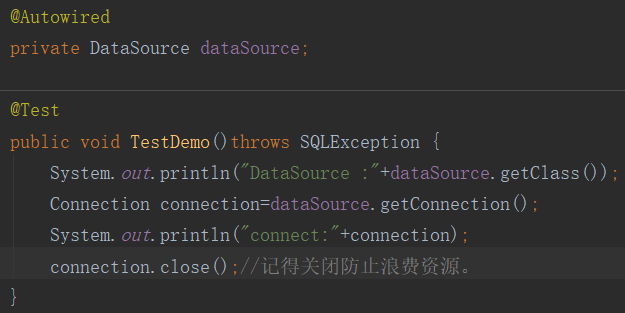
输出信息发现,目前使用的DataSource是HikariDataSourece。

④.具体的数据库操作,用JDBC、SpringBoot默认配置了JdbcTemplate,配置了数据源可以直接使用。
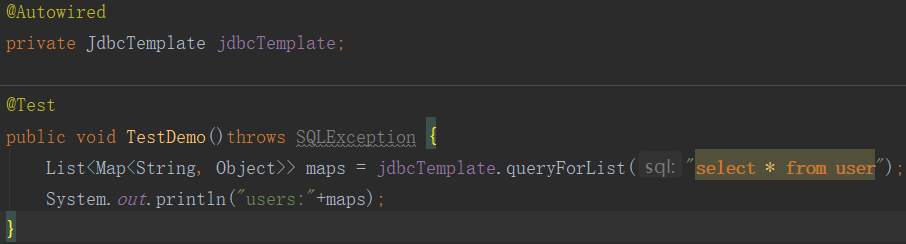
![]()
九、SpringBoot整合Druid数据源。
SpringBoot默认使用的HiKariDataSource。在项目中经常使用的是阿里巴巴的Druid数据源,目前是公认JAVA中最好用的数据源,除了Druid提供数据源外,还提供一套完整和扩展功能。
①:druid数据源使用的是log4j日志框架,在SpringBoot框架默认使用的是slf4j+log-back,所以我们在使用druid框架时,需要将这两个东西引入。
log4j、log4j2、slf4j+log-back的区别:
1.log4j和log4j2不是同一个作者写的,两者并没有什么联系。
2.log4j、slf4j+log-back是一个作者写的,log4j是最先写出来的,受到广泛的欢迎,于是作者在log4j的基础上开发出 slf4j+log- back框架。
②:在全局配置中配置Druid的基础属性,在配置这个基本属性的时候,因为SpringBoot的默认数据源是HiKariSource,所以需要更改数据源,spring.datasource.type=com.alibaba.druid.pool.DruidDataSource。
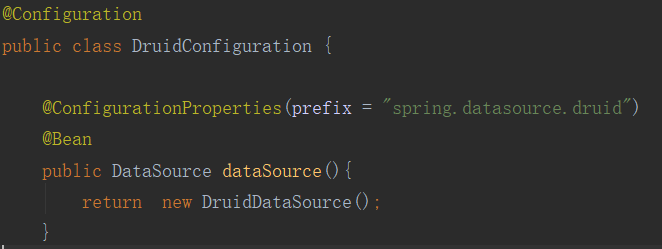
③:需要将我们配置全局变量的这些配置信息,加载到Druid上,新建一个Druid 的配置文件,使用@ConfigurationProperties将配置文件中的数据导入到DataSource中。
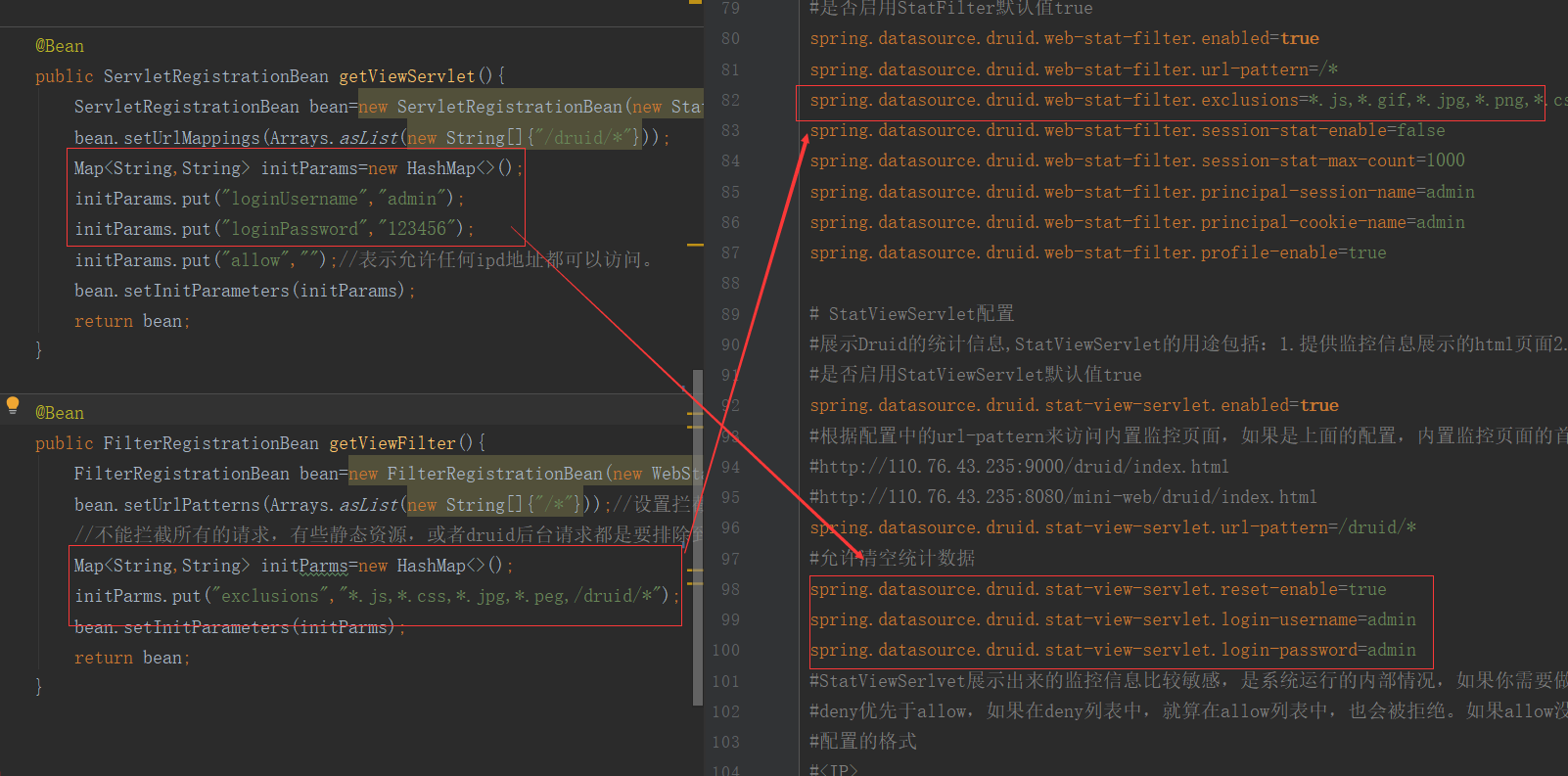
④:配置Druid的Servlet和Filter拦截器,和前面的整合Servlet一样。Servlet配置将要加载的Url地址,和Druid后台管理的用户和密码,允许访问和不允许访问的ip地址的设置。Filter中拦截所有的Url地址,但不拦截一些静态资源和Druid后台路径。
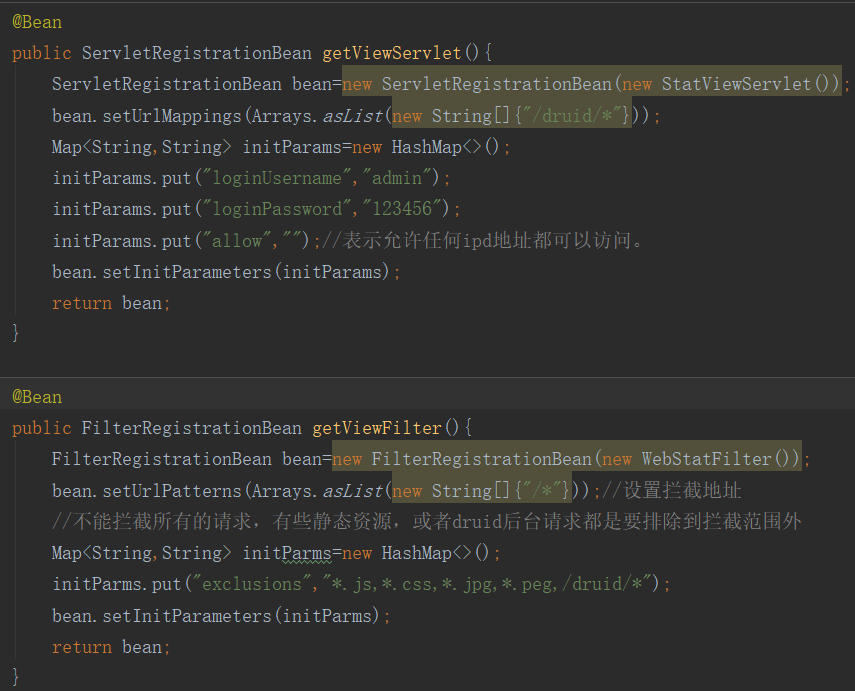
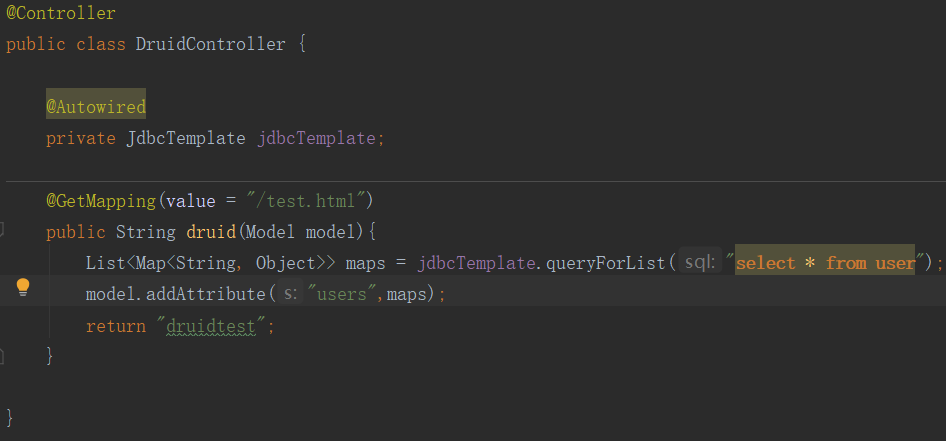
⑤:创建Controller和jsp页面实现,数据交互:
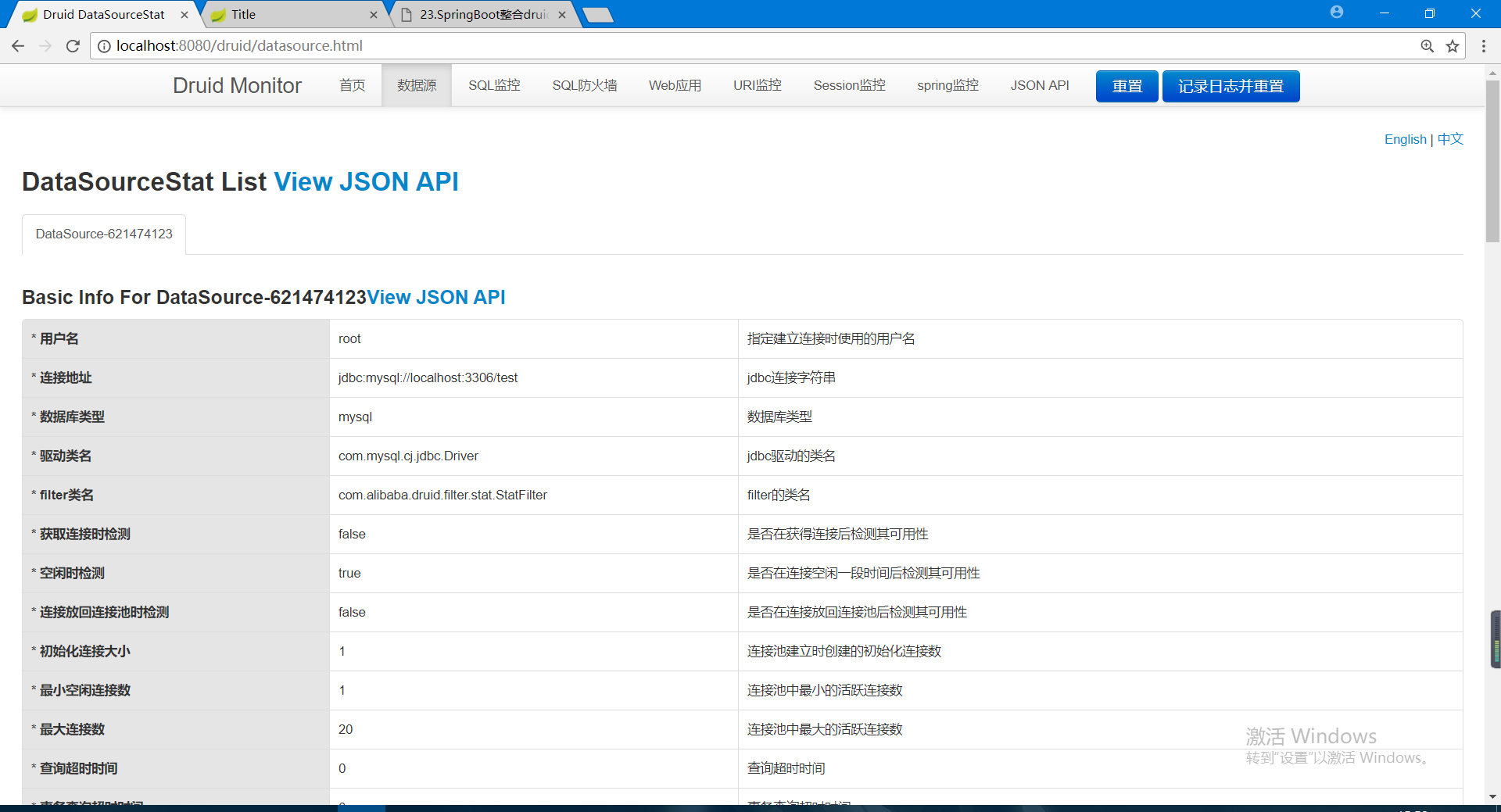
⑥:启动启动类,我们访问http:localhost:8080/druid/login输入我们配置用户名和密码登录到后台。
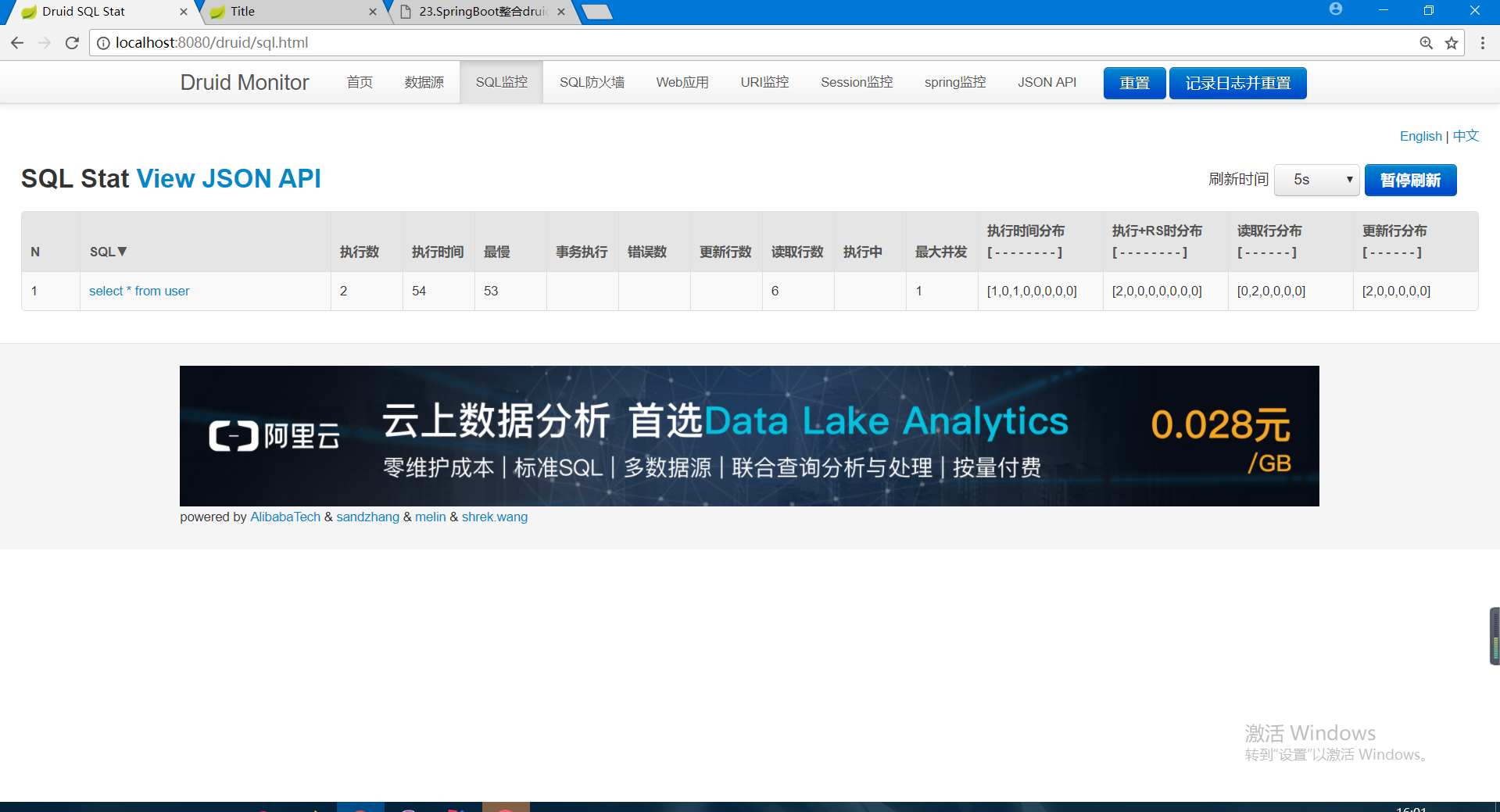
⑦:我们再访问我们的jsp页面:http://localhost:8080/test.html。
检测到后台的数据库相关的信息:
另外一种实现方式:在新的SpringBoot版本中,阿里巴巴将Druid整合成启动器了,我们只需要在项目中添加druid-spring-boot-starter即可,不需要添加log4j的依赖实现也比较简单。但是在全局配置有一些改动:
①:不需要在全局变量中配置切换数据源。
②:并且在配置的语法上有一些区别。在数据库基础信息的配置从spring.datasource....变成spring.datasource.druid.....对Druid的专属配置、配置文件的前缀也改变了。
这一种实现方式除了方式一中的第一步和第二步不一样外,其他都是一样的。
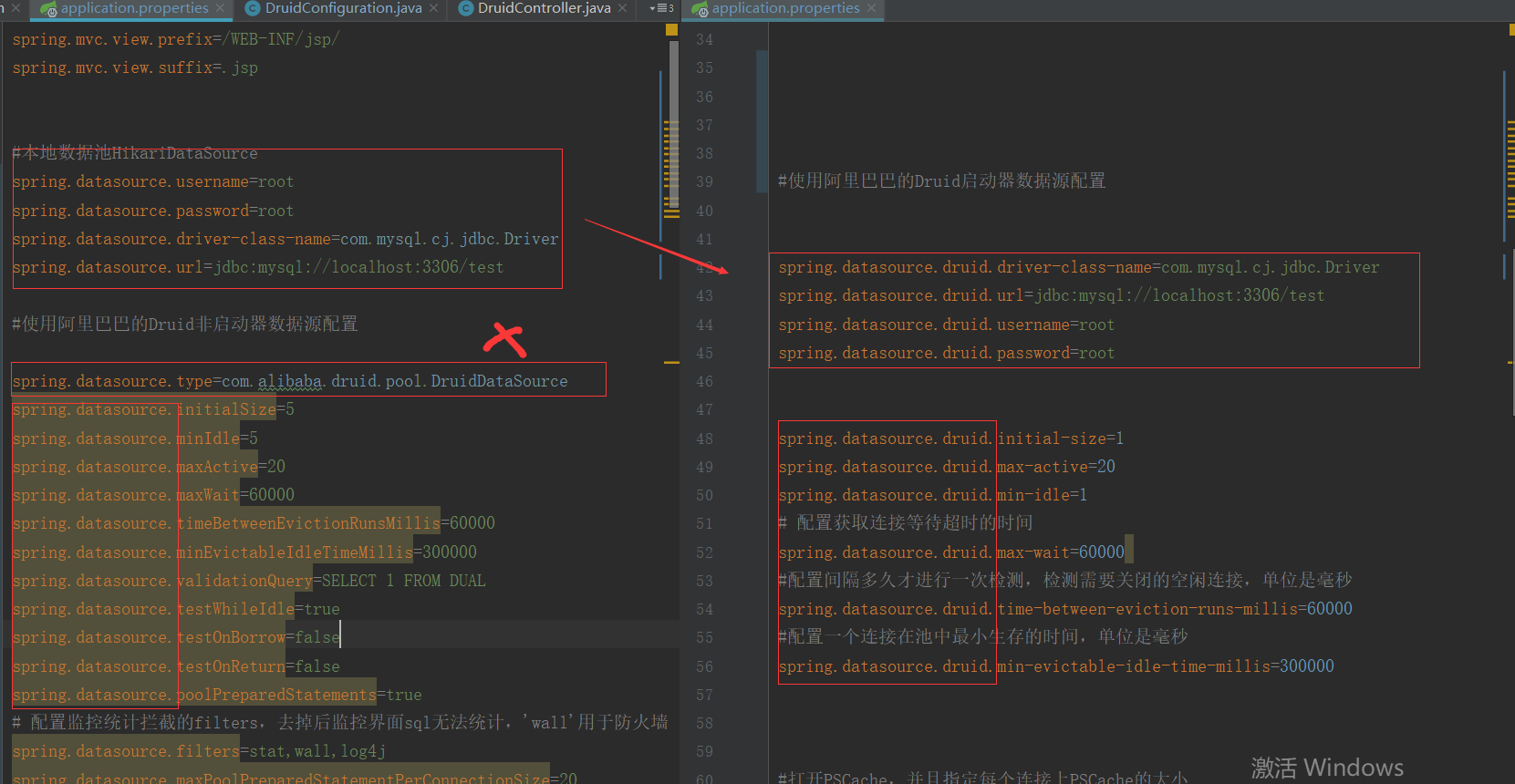
我之前是使用配置类,来配置Druid的基础信息,当然还有另外一种方式,直接使用全局配置。
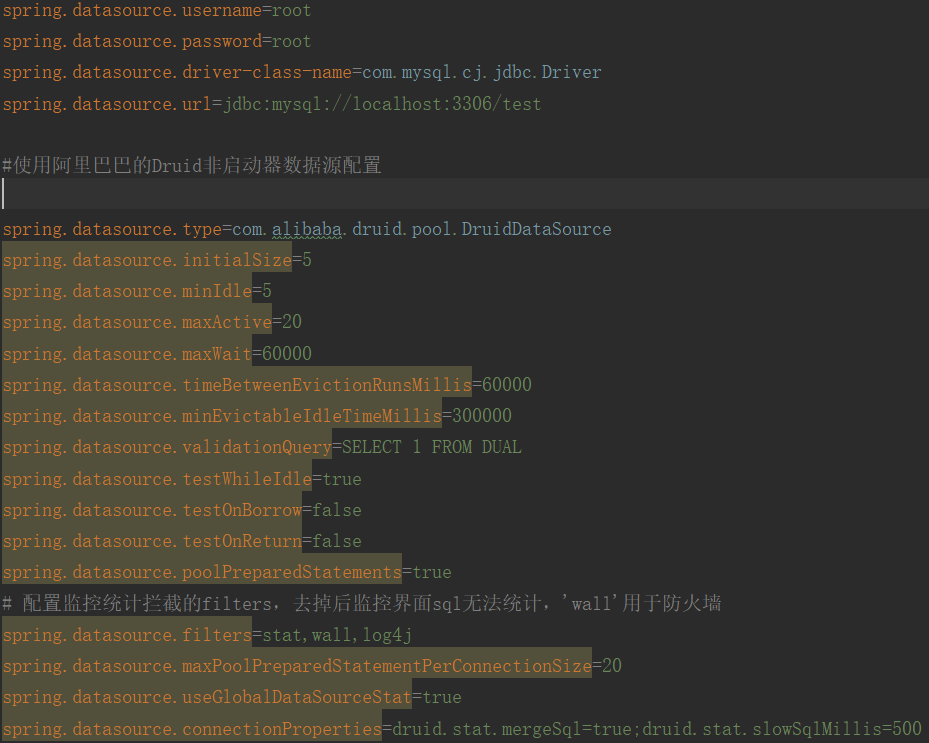
spring.mvc.view.prefix=/WEB-INF/jsp/ spring.mvc.view.suffix=.jsp #本地数据池HikariDataSource #spring.datasource.username=root #spring.datasource.password=root #spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #spring.datasource.url=jdbc:mysql://localhost:3306/test #使用阿里巴巴的Druid非启动器数据源配置 #spring.datasource.type=com.alibaba.druid.pool.DruidDataSource #spring.datasource.initialSize=5 #spring.datasource.minIdle=5 #spring.datasource.maxActive=20 #spring.datasource.maxWait=60000 #spring.datasource.timeBetweenEvictionRunsMillis=60000 #spring.datasource.minEvictableIdleTimeMillis=300000 #spring.datasource.validationQuery=SELECT 1 FROM DUAL #spring.datasource.testWhileIdle=true #spring.datasource.testOnBorrow=false #spring.datasource.testOnReturn=false #spring.datasource.poolPreparedStatements=true # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 #spring.datasource.filters=stat,wall,log4j #spring.datasource.maxPoolPreparedStatementPerConnectionSize=20 #spring.datasource.useGlobalDataSourceStat=true #spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500 #使用阿里巴巴的Druid启动器数据源配置 spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/test spring.datasource.druid.username=root spring.datasource.druid.password=root spring.datasource.druid.initial-size=1 spring.datasource.druid.max-active=20 spring.datasource.druid.min-idle=1 # 配置获取连接等待超时的时间 spring.datasource.druid.max-wait=60000 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 spring.datasource.druid.time-between-eviction-runs-millis=60000 #配置一个连接在池中最小生存的时间,单位是毫秒 spring.datasource.druid.min-evictable-idle-time-millis=300000 #打开PSCache,并且指定每个连接上PSCache的大小 spring.datasource.druid.pool-prepared-statements=true spring.datasource.druid.max-pool-prepared-statement-per-connection-size=20 #spring.datasource.druid.max-open-prepared-statements=和上面的等价 spring.datasource.druid.validation-query=SELECT 'x' spring.datasource.druid.test-on-borrow=false spring.datasource.druid.test-on-return=false spring.datasource.druid.test-while-idle=true #配置多个英文逗号分隔 spring.datasource.druid.filters= stat spring.datasource.druid.use-global-data-source-stat=true spring.datasource.druid.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500 # WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter #是否启用StatFilter默认值true spring.datasource.druid.web-stat-filter.enabled=true spring.datasource.druid.web-stat-filter.url-pattern=/* spring.datasource.druid.web-stat-filter.exclusions=*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/* spring.datasource.druid.web-stat-filter.session-stat-enable=false spring.datasource.druid.web-stat-filter.session-stat-max-count=1000 spring.datasource.druid.web-stat-filter.principal-session-name=admin spring.datasource.druid.web-stat-filter.principal-cookie-name=admin spring.datasource.druid.web-stat-filter.profile-enable=true # StatViewServlet配置 #展示Druid的统计信息,StatViewServlet的用途包括:1.提供监控信息展示的html页面2.提供监控信息的JSON API #是否启用StatViewServlet默认值true spring.datasource.druid.stat-view-servlet.enabled=true #根据配置中的url-pattern来访问内置监控页面,如果是上面的配置,内置监控页面的首页是/druid/index.html例如: #http://110.76.43.235:9000/druid/index.html #http://110.76.43.235:8080/mini-web/druid/index.html spring.datasource.druid.stat-view-servlet.url-pattern=/druid/* #允许清空统计数据 spring.datasource.druid.stat-view-servlet.reset-enable=true spring.datasource.druid.stat-view-servlet.login-username=admin spring.datasource.druid.stat-view-servlet.login-password=admin #StatViewSerlvet展示出来的监控信息比较敏感,是系统运行的内部情况,如果你需要做访问控制,可以配置allow和deny这两个参数 #deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝。如果allow没有配置或者为空,则允许所有访问 #配置的格式 #<IP> #或者<IP>/<SUB_NET_MASK_size>其中128.242.127.1/24 #24表示,前面24位是子网掩码,比对的时候,前面24位相同就匹配,不支持IPV6。 spring.datasource.druid.stat-view-servlet.allow= spring.datasource.druid.stat-view-servlet.deny=128.242.127.1/24,128.242.128.1 # Spring监控配置,说明请参考Druid Github Wiki,配置_Druid和Spring关联监控配置 spring.datasource.druid.aop-patterns= # Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔
十、整合Mybatis.
①:在SpringBoot中整合Mybatis,在第九的基础上,添加Mybatis的启动器。
②:新建实体类型Student,新建接口类 AcquireData,并且新建mybatis-config.xml全局配置文件,和对应接口的mapper。具体可以参考:。
③:在全局配置文件中绑定新建的配置文件。

④:在启动类添加注解@MapperScan({"接口类所在包地址"}),来告诉SpringBoot映射接口的位置。
结语
学习了关于SpringBoot的一系列的整合:servlet、Filter、Listener、JDBC、Druid数据源、mybatis的整合。和在SpringBoot中使用Jsp的方式,和FreeMaker、Thymeleaf两个视图模板的使用,为学习SpringBoot的实战项目打下基础。
