大数据初学者应该知道的知识
原文:http://lxw1234.com/archives/2016/11/779.htm
导读:
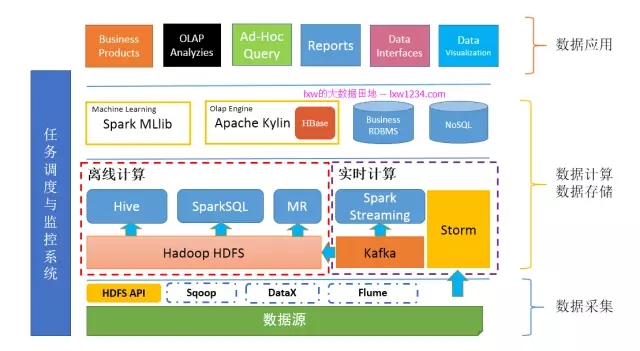
- 第一章:初识Hadoop
- 第二章:更高效的WordCount
- 第三章:把别处的数据搞到Hadoop上
- 第四章:把Hadoop上的数据搞到别处去
- 第五章:快一点吧,我的SQL
- 第六章:一夫多妻制
- 第七章:越来越多的分析任务
- 第八章:我的数据要实时
- 第九章:我的数据要对外
- 第十章:牛逼高大上的机器学习
经常有初学者在博客和QQ问我,自己想往大数据方向发展,该学哪些技术,学习路线是什么样的,觉得大数据很火,就业很好,薪资很高。如果自己很迷茫,为了这些原因想往大数据方向发展,也可以,那么我就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?是计算机专业,对操作系统、硬件、网络、服务器感兴趣?是软件专业,对软件开发、编程、写代码感兴趣?还是数学、统计学专业,对数据和数字特别感兴趣。。
其实这就是想告诉你的大数据的三个发展方向,平台搭建/优化/运维/监控、大数据开发/设计/架构、数据分析/挖掘。请不要问我哪个容易,哪个前景好,哪个钱多。
先扯一下大数据的4V特征:
- 数据量大,TB->PB
- 数据类型繁多,结构化、非结构化文本、日志、视频、图片、地理位置等;
- 商业价值高,但是这种价值需要在海量数据之上,通过数据分析与机器学习更快速的挖掘出来;
- 处理时效性高,海量数据的处理需求不再局限在离线计算当中。
现如今,正式为了应对大数据的这几个特点,开源的大数据框架越来越多,越来越强,先列举一些常见的:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
……
眼花了吧,上面的有30多种吧,别说精通了,全部都会使用的,估计也没几个。
就我个人而言,主要经验是在第二个方向(开发/设计/架构),且听听我的建议吧。
第一章:初识Hadoop
1.1 学会百度与Google
不论遇到什么问题,先试试搜索并自己解决。
Google首选,翻不过去的,就用百度吧。
1.2 参考资料首选官方文档
特别是对于入门来说,官方文档永远是首选文档。
相信搞这块的大多是文化人,英文凑合就行,实在看不下去的,请参考第一步。
1.3 先让Hadoop跑起来
Hadoop可以算是大数据存储和计算的开山鼻祖,现在大多开源的大数据框架都依赖Hadoop或者与它能很好的兼容。
关于Hadoop,你至少需要搞清楚以下是什么:
- Hadoop 1.0、Hadoop 2.0
- MapReduce、HDFS
- NameNode、DataNode
- JobTracker、TaskTracker
- Yarn、ResourceManager、NodeManager
自己搭建Hadoop,请使用第一步和第二步,能让它跑起来就行。
建议先使用安装包命令行安装,不要使用管理工具安装。
另外:Hadoop1.0知道它就行了,现在都用Hadoop 2.0.
1.4 试试使用Hadoop
HDFS目录操作命令;
上传、下载文件命令;
提交运行MapReduce示例程序;
打开Hadoop WEB界面,查看Job运行状态,查看Job运行日志。
知道Hadoop的系统日志在哪里。
1.5 你该了解它们的原理了
MapReduce:如何分而治之;
HDFS:数据到底在哪里,什么是副本;
Yarn到底是什么,它能干什么;
NameNode到底在干些什么;
ResourceManager到底在干些什么;
1.6 自己写一个MapReduce程序
请仿照WordCount例子,自己写一个(照抄也行)WordCount程序,
打包并提交到Hadoop运行。
你不会Java?Shell、Python都可以,有个东西叫Hadoop Streaming。
如果你认真完成了以上几步,恭喜你,你的一只脚已经进来了。
第二章:更高效的WordCount
2.1 学点SQL吧
你知道数据库吗?你会写SQL吗?
如果不会,请学点SQL吧。
2.2 SQL版WordCount
在1.6中,你写(或者抄)的WordCount一共有几行代码?
给你看看我的:
SELECT word,COUNT(1) FROM wordcount GROUP BY word;
这便是SQL的魅力,编程需要几十行,甚至上百行代码,我这一句就搞定;使用SQL处理分析Hadoop上的数据,方便、高效、易上手、更是趋势。不论是离线计算还是实时计算,越来越多的大数据处理框架都在积极提供SQL接口。
2.3 SQL On Hadoop之Hive
什么是Hive?官方给的解释是:
The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
为什么说Hive是数据仓库工具,而不是数据库工具呢?有的朋友可能不知道数据仓库,数据仓库是逻辑上的概念,底层使用的是数据库,数据仓库中的数据有这两个特点:最全的历史数据(海量)、相对稳定的;所谓相对稳定,指的是数据仓库不同于业务系统数据库,数据经常会被更新,数据一旦进入数据仓库,很少会被更新和删除,只会被大量查询。而Hive,也是具备这两个特点,因此,Hive适合做海量数据的数据仓库工具,而不是数据库工具。
2.4 安装配置Hive
请参考1.1 和 1.2 完成Hive的安装配置。可以正常进入Hive命令行。
2.5 试试使用Hive
请参考1.1 和 1.2 ,在Hive中创建wordcount表,并运行2.2中的SQL语句。
在Hadoop WEB界面中找到刚才运行的SQL任务。
看SQL查询结果是否和1.4中MapReduce中的结果一致。
2.6 Hive是怎么工作的
明明写的是SQL,为什么Hadoop WEB界面中看到的是MapReduce任务?
2.7 学会Hive的基本命令
创建、删除表;
加载数据到表;
下载Hive表的数据;
请参考1.2,学习更多关于Hive的语法和命令。
如果你已经按照《写给大数据开发初学者的话》中第一章和第二章的流程认真完整的走了一遍,那么你应该已经具备以下技能和知识点:
- 0和Hadoop2.0的区别;
- MapReduce的原理(还是那个经典的题目,一个10G大小的文件,给定1G大小的内存,如何使用Java程序统计出现次数最多的10个单词及次数);
- HDFS读写数据的流程;向HDFS中PUT数据;从HDFS中下载数据;
- 自己会写简单的MapReduce程序,运行出现问题,知道在哪里查看日志;
- 会写简单的SELECT、WHERE、GROUP BY等SQL语句;
- Hive SQL转换成MapReduce的大致流程;
- Hive中常见的语句:创建表、删除表、往表中加载数据、分区、将表中数据下载到本地;
从上面的学习,你已经了解到,HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。
此时,你的”大数据平台”是这样的:
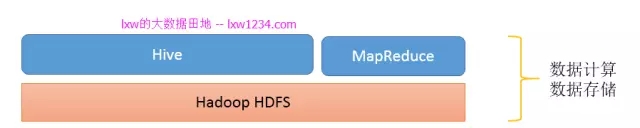
那么问题来了,海量数据如何到HDFS上呢?
第三章:把别处的数据搞到Hadoop上
此处也可以叫做数据采集,把各个数据源的数据采集到Hadoop上。
3.1 HDFS PUT命令
这个在前面你应该已经使用过了。
put命令在实际环境中也比较常用,通常配合shell、python等脚本语言来使用。
建议熟练掌握。
3.2 HDFS API
HDFS提供了写数据的API,自己用编程语言将数据写入HDFS,put命令本身也是使用API。
实际环境中一般自己较少编写程序使用API来写数据到HDFS,通常都是使用其他框架封装好的方法。比如:Hive中的INSERT语句,Spark中的saveAsTextfile等。
建议了解原理,会写Demo。
3.3 Sqoop
Sqoop是一个主要用于Hadoop/Hive与传统关系型数据库Oracle/MySQL/SQLServer等之间进行数据交换的开源框架。
就像Hive把SQL翻译成MapReduce一样,Sqoop把你指定的参数翻译成MapReduce,提交到Hadoop运行,完成Hadoop与其他数据库之间的数据交换。
自己下载和配置Sqoop(建议先使用Sqoop1,Sqoop2比较复杂)。
了解Sqoop常用的配置参数和方法。
使用Sqoop完成从MySQL同步数据到HDFS;
使用Sqoop完成从MySQL同步数据到Hive表;
PS:如果后续选型确定使用Sqoop作为数据交换工具,那么建议熟练掌握,否则,了解和会用Demo即可。
3.4 Flume
Flume是一个分布式的海量日志采集和传输框架,因为“采集和传输框架”,所以它并不适合关系型数据库的数据采集和传输。
Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。
因此,如果你的业务有这些数据源的数据,并且需要实时的采集,那么就应该考虑使用Flume。
下载和配置Flume。
使用Flume监控一个不断追加数据的文件,并将数据传输到HDFS;
PS:Flume的配置和使用较为复杂,如果你没有足够的兴趣和耐心,可以先跳过Flume。
3.5 阿里开源的DataX
之所以介绍这个,是因为我们公司目前使用的Hadoop与关系型数据库数据交换的工具,就是之前基于DataX开发的,非常好用。
可以参考我的博文《异构数据源海量数据交换工具-Taobao DataX 下载和使用》。
现在DataX已经是3.0版本,支持很多数据源。
你也可以在其之上做二次开发。
PS:有兴趣的可以研究和使用一下,对比一下它与Sqoop。
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
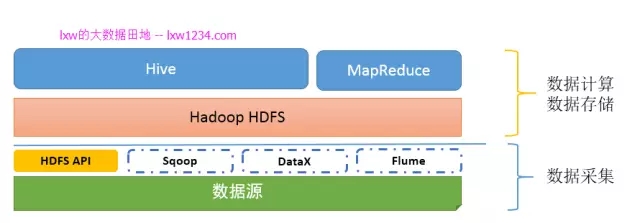
第四章:把Hadoop上的数据搞到别处去
前面介绍了如何把数据源的数据采集到Hadoop上,数据到Hadoop上之后,便可以使用Hive和MapReduce进行分析了。那么接下来的问题是,分析完的结果如何从Hadoop上同步到其他系统和应用中去呢?
其实,此处的方法和第三章基本一致的。
4.1 HDFS GET命令
把HDFS上的文件GET到本地。需要熟练掌握。
4.2 HDFS API
同3.2.
4.3 Sqoop
同3.3.
使用Sqoop完成将HDFS上的文件同步到MySQL;
使用Sqoop完成将Hive表中的数据同步到MySQL;
4.4 DataX
同3.5.
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
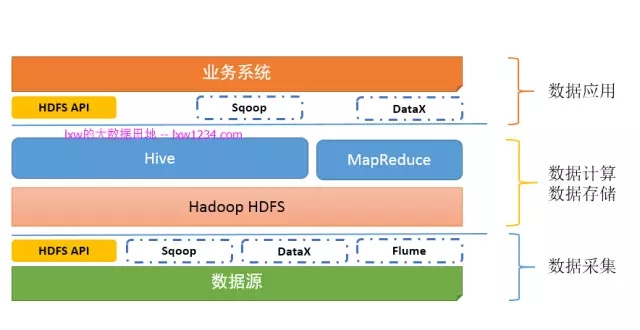
如果你已经按照《写给大数据开发初学者的话2》中第三章和第四章的流程认真完整的走了一遍,那么你应该已经具备以下技能和知识点:
知道如何把已有的数据采集到HDFS上,包括离线采集和实时采集;
你已经知道sqoop(或者还有DataX)是HDFS和其他数据源之间的数据交换工具;
你已经知道flume可以用作实时的日志采集。
从前面的学习,对于大数据平台,你已经掌握的不少的知识和技能,搭建Hadoop集群,把数据采集到Hadoop上,使用Hive和MapReduce来分析数据,把分析结果同步到其他数据源。
接下来的问题来了,Hive使用的越来越多,你会发现很多不爽的地方,特别是速度慢,大多情况下,明明我的数据量很小,它都要申请资源,启动MapReduce来执行。
第五章:快一点吧,我的SQL
其实大家都已经发现Hive后台使用MapReduce作为执行引擎,实在是有点慢。
因此SQL On Hadoop的框架越来越多,按我的了解,最常用的按照流行度依次为SparkSQL、Impala和Presto.
这三种框架基于半内存或者全内存,提供了SQL接口来快速查询分析Hadoop上的数据。关于三者的比较,请参考1.1.
我们目前使用的是SparkSQL,至于为什么用SparkSQL,原因大概有以下吧:
使用Spark还做了其他事情,不想引入过多的框架;
Impala对内存的需求太大,没有过多资源部署;
5.1 关于Spark和SparkSQL
什么是Spark,什么是SparkSQL。
Spark有的核心概念及名词解释。
SparkSQL和Spark是什么关系,SparkSQL和Hive是什么关系。
SparkSQL为什么比Hive跑的快。
5.2 如何部署和运行SparkSQL
Spark有哪些部署模式?
如何在Yarn上运行SparkSQL?
使用SparkSQL查询Hive中的表。
PS: Spark不是一门短时间内就能掌握的技术,因此建议在了解了Spark之后,可以先从SparkSQL入手,循序渐进。
关于Spark和SparkSQL,可参考 http://lxw1234.com/archives/category/spark
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
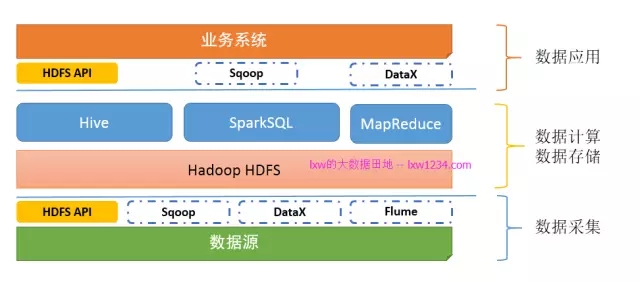
第六章:一夫多妻制
请不要被这个名字所诱惑。其实我想说的是数据的一次采集、多次消费。
在实际业务场景下,特别是对于一些监控日志,想即时的从日志中了解一些指标(关于实时计算,后面章节会有介绍),这时候,从HDFS上分析就太慢了,尽管是通过Flume采集的,但Flume也不能间隔很短就往HDFS上滚动文件,这样会导致小文件特别多。
为了满足数据的一次采集、多次消费的需求,这里要说的便是Kafka。
6.1 关于Kafka
什么是Kafka?
Kafka的核心概念及名词解释。
6.2 如何部署和使用Kafka
使用单机部署Kafka,并成功运行自带的生产者和消费者例子。
使用Java程序自己编写并运行生产者和消费者程序。
Flume和Kafka的集成,使用Flume监控日志,并将日志数据实时发送至Kafka。
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
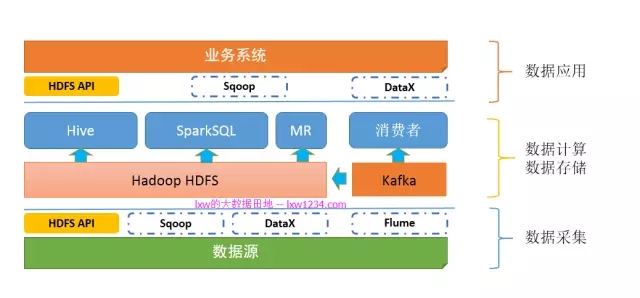
这时,使用Flume采集的数据,不是直接到HDFS上,而是先到Kafka,Kafka中的数据可以由多个消费者同时消费,其中一个消费者,就是将数据同步到HDFS。
如果你已经按照《写给大数据开发初学者的话3》中第五章和第六章的流程认真完整的走了一遍,那么你应该已经具备以下技能和知识点:
- 为什么Spark比MapReduce快。
- 使用SparkSQL代替Hive,更快的运行SQL。
- 使用Kafka完成数据的一次收集,多次消费架构。
- 自己可以写程序完成Kafka的生产者和消费者。
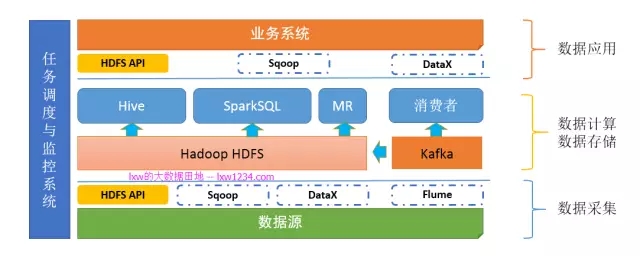
从前面的学习,你已经掌握了大数据平台中的数据采集、数据存储和计算、数据交换等大部分技能,而这其中的每一步,都需要一个任务(程序)来完成,各个任务之间又存在一定的依赖性,比如,必须等数据采集任务成功完成后,数据计算任务才能开始运行。如果一个任务执行失败,需要给开发运维人员发送告警,同时需要提供完整的日志来方便查错。
第七章:越来越多的分析任务
不仅仅是分析任务,数据采集、数据交换同样是一个个的任务。这些任务中,有的是定时触发,有点则需要依赖其他任务来触发。当平台中有几百上千个任务需要维护和运行时候,仅仅靠crontab远远不够了,这时便需要一个调度监控系统来完成这件事。调度监控系统是整个数据平台的中枢系统,类似于AppMaster,负责分配和监控任务。
7.1 Apache Oozie
1. Oozie是什么?有哪些功能?
2. Oozie可以调度哪些类型的任务(程序)?
3. Oozie可以支持哪些任务触发方式?
4. 安装配置Oozie。
7.2 其他开源的任务调度系统
Azkaban:
https://azkaban.github.io/
light-task-scheduler:
https://github.com/ltsopensource/light-task-scheduler
Zeus:
https://github.com/alibaba/zeus
等等……
另外,我这边是之前单独开发的任务调度与监控系统,具体请参考《大数据平台任务调度与监控系统》.
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
第八章:我的数据要实时
在第六章介绍Kafka的时候提到了一些需要实时指标的业务场景,实时基本可以分为绝对实时和准实时,绝对实时的延迟要求一般在毫秒级,准实时的延迟要求一般在秒、分钟级。对于需要绝对实时的业务场景,用的比较多的是Storm,对于其他准实时的业务场景,可以是Storm,也可以是Spark Streaming。当然,如果可以的话,也可以自己写程序来做。
8.1 Storm
1. 什么是Storm?有哪些可能的应用场景?
2. Storm由哪些核心组件构成,各自担任什么角色?
3. Storm的简单安装和部署。
4. 自己编写Demo程序,使用Storm完成实时数据流计算。
8.2 Spark Streaming
1. 什么是Spark Streaming,它和Spark是什么关系?
2. Spark Streaming和Storm比较,各有什么优缺点?
3. 使用Kafka + Spark Streaming,完成实时计算的Demo程序。
如果你认真完成了上面的学习和实践,此时,你的”大数据平台”应该是这样的:
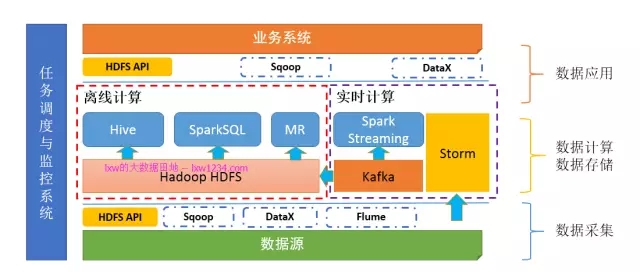
至此,你的大数据平台底层架构已经成型了,其中包括了数据采集、数据存储与计算(离线和实时)、数据同步、任务调度与监控这几大模块。接下来是时候考虑如何更好的对外提供数据了。
第九章:我的数据要对外
通常对外(业务)提供数据访问,大体上包含以下方面:
离线:比如,每天将前一天的数据提供到指定的数据源(DB、FILE、FTP)等;离线数据的提供可以采用Sqoop、DataX等离线数据交换工具。
实时:比如,在线网站的推荐系统,需要实时从数据平台中获取给用户的推荐数据,这种要求延时非常低(50毫秒以内)。
根据延时要求和实时数据的查询需要,可能的方案有:HBase、Redis、MongoDB、ElasticSearch等。
OLAP分析:OLAP除了要求底层的数据模型比较规范,另外,对查询的响应速度要求也越来越高,可能的方案有:Impala、Presto、SparkSQL、Kylin。如果你的数据模型比较规模,那么Kylin是最好的选择。
即席查询:即席查询的数据比较随意,一般很难建立通用的数据模型,因此可能的方案有:Impala、Presto、SparkSQL。
这么多比较成熟的框架和方案,需要结合自己的业务需求及数据平台技术架构,选择合适的。原则只有一个:越简单越稳定的,就是最好的。
如果你已经掌握了如何很好的对外(业务)提供数据,那么你的“大数据平台”应该是这样的:
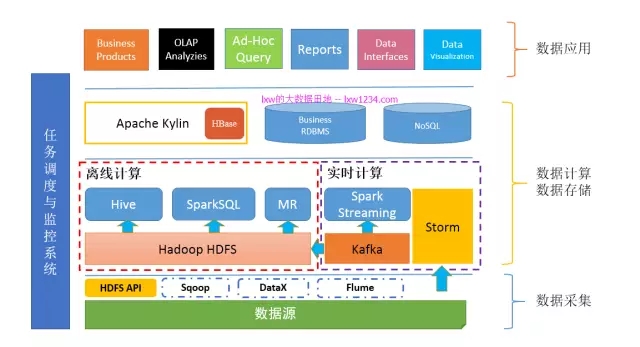
第十章:牛逼高大上的机器学习
关于这块,我这个门外汉也只能是简单介绍一下了。数学专业毕业的我非常惭愧,很后悔当时没有好好学数学。
在我们的业务中,遇到的能用机器学习解决的问题大概这么三类:
- 分类问题:包括二分类和多分类,二分类就是解决了预测的问题,就像预测一封邮件是否垃圾邮件;多分类解决的是文本的分类;
- 聚类问题:从用户搜索过的关键词,对用户进行大概的归类。
- 推荐问题:根据用户的历史浏览和点击行为进行相关推荐。
大多数行业,使用机器学习解决的,也就是这几类问题。
入门学习线路:
数学基础;
机器学习实战(Machine Learning in Action),懂Python最好;
SparkMlLib提供了一些封装好的算法,以及特征处理、特征选择的方法。
机器学习确实牛逼高大上,也是我学习的目标。
那么,可以把机器学习部分也加进你的“大数据平台”了。