

面试题(15)-- 做一道题
1. Integer a = 1 ,Integer b = 1 , a == b 结果是什么?
结果:true
2. Integer a = 1000 ,Integer b = 1000 , a == b 结果是什么?
结果:false
解析:这两道题主要考察的是 Integer [-128,127]范围之间的数据比较是相等的,超过的话 比如:-129 128 就不想等了。
3. short a = 3; a = a + 3; // 从int转换到short可能有损失
4. short a = 3; a += 3; // 结果是 6
解析:这两道提主要是考察的 类型转换的问题,从上到下转换可能存在精度的损失
5. 两个字符串比较
String str1 = "hello"; String str2 = "he" + "llo"; if (str1 == str2) { System.out.println("相等"); } else { System.out.println("不相等"); }
结果:相等
6. ArrayList list = new ArrayList(20); list 扩容几次
结果:这是指定数组大小的创建,创建时直接分配其大小,没有扩容,所以扩容时 0 次。
7. 考察类初始化顺序
class HelloA{ public HelloA(){ System.out.println("helloA"); } { System.out.println("I am helloA"); } static { System.out.println("staticA"); } } class HelloB extends HelloA{ public HelloB(){ System.out.println("helloB"); } { System.out.println("I am helloB"); } static{ System.out.println("staticB"); } public static void main(String[] args) { new HelloB(); } }
结果:
staticA
staticB
I am helloA
helloA
I am helloB
helloB
解析:Java代码中一个类初始化顺序:static变量 -- 其他成员变量 -- 构造函数 三者的调用先后顺序。
初始化父类Static --> 子类的Static (如果是类实例化,接下来还会: 初始化父类的其他成员变量->父类构造方法->子类其他成员变量->子类的构造方法)。
8. 考察 try块及finally块
class AAA1{ public static void A(){ try { B(); System.out.println("a1"); } catch (Exception e){ System.out.println("a2"); } finally { System.out.println("a3"); } } public static void B(){ try { int i = 1/0; System.out.println("b1"); } catch (Exception e){ System.out.println("b2"); } finally { System.out.println("b3"); } } public static void main(String[] args) { A(); } }
结果:
b2
b3
a1
a3
解析:如果一个方法A调用另一个方法B,而另一个方法B出现的异常 自己通过try 抓取了,那么A 就没法捕获B抛出的异常了,除非B主动向上抛出。
finally 无论时正常还是异常,都是最终要执行的代码块。
9. 列举一下 Spring常用的注解?其中@Autowired 和 @ Resource之间的区别
@RestController、@Autowired、@Resource、@RequestMapping、@Service、@Configuration、@PostMapping、@GetMapping、@Repository、@Component、@Aspect、@PointCut、@Around、@Before、@After等
@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不制定name也不制定type属性,这时将通过反射机制使用byName自动注入策略。
10. mybatis中的#{}与${}之间的区别?
#{}会被解析为JDBC预编译语句的参数标记符(占位符)
${}则直接解析为字符串变量替换, ${}会引起SQL注入问题
11. 考察SQL功底
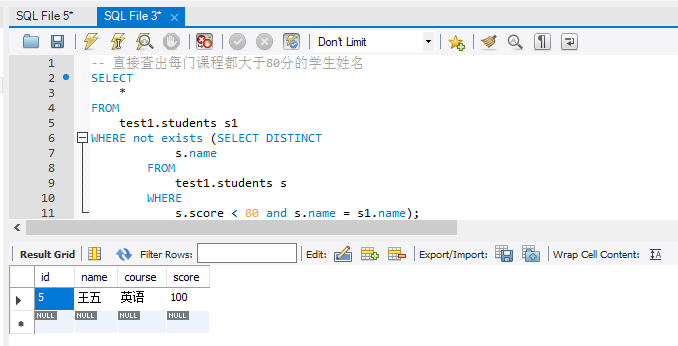
CREATE TABLE test1.`students` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(20) NOT NULL COMMENT '姓名', `course` varchar(20) NOT NULL COMMENT '课程', `score` int NOT NULL COMMENT '成绩', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='学生课程成绩表'; INSERT INTO `students` (`id`,`name`,`course`,`score`) VALUES (1,'张三','语文',81); INSERT INTO `students` (`id`,`name`,`course`,`score`) VALUES (2,'张三','数学',75); INSERT INTO `students` (`id`,`name`,`course`,`score`) VALUES (3,'李四','语文',76); INSERT INTO `students` (`id`,`name`,`course`,`score`) VALUES (4,'李四','数学',90); INSERT INTO `students` (`id`,`name`,`course`,`score`) VALUES (5,'王五','英语',100); -- 直接查出每门课程都大于80分的学生姓名 SELECT * FROM test1.students s1 WHERE not exists (SELECT DISTINCT s.name FROM test1.students s WHERE s.score < 80 and s.name = s1.name);
12. 用java写一段程序,把一个有序数组里的所有元素加入一个高度最小的二叉树
二叉查找树定义:对于任意一个节点,左边的结点均小于它,右边的结点均大于它。
思路:
要创建一个高度最小的二叉树,就必须让左右子结点的数量越接近越好,也就是说,要让中间值成为根节点,这样,左边一半是左子树,右边一半是右子树。然后,继续以类似的方式构造整棵树,数据每一段的中间值成为根元素,左边一半成为左子树,右边一半成为右子树。
程序:
package com.sinosoft.test; /** * @author Created by xushuyi * @Description * @date 2019/1/24 21:11 */ public class ThreadTest { static TreeNode createMinumumBST(int arr[], int start, int end) { if (end < start) { return null; } int mid = (end + start) / 2; TreeNode treeNode = new TreeNode(arr[mid]); treeNode.left = createMinumumBST(arr, start, mid - 1); treeNode.right = createMinumumBST(arr, mid + 1, end); return treeNode; } static TreeNode createMinumumBST(int arr[]) { return createMinumumBST(arr, 0, arr.length - 1); } public static void main(String[] args) { int arr[] = {1, 2, 3, 5, 6}; TreeNode treeNode = createMinumumBST(arr); System.out.println(treeNode.toString()); } } class TreeNode { int data; TreeNode left; TreeNode right; public TreeNode(int data) { this.data = data; } @Override public String toString() { return "TreeNode{" + "data=" + data + ", left=" + left + ", right=" + right + '}'; } }
13. 求得下面伪代码得结果
/** * 求得下列伪代码得结果 */ private static void compared() { String a = "abc"; String b = "abc"; String c = new String("abc"); String d = "ab" + "c"; System.out.println("a==b:" + (a == b) + " a.equals(b):" + (a.equals(b))); System.out.println("a==c:" + (a == c) + " a.equals(c):" + (a.equals(c))); System.out.println("a==d:" + (a == d) + " a.equals(d):" + (a.equals(d))); System.out.println("c==d:" + (c == d) + " c.equals(d):" + (c.equals(d))); }
结果:
a==b:true a.equals(b):true
a==c:false a.equals(c):true
a==d:true a.equals(d):true
c==d:false c.equals(d):true
14. 测试List扩容情况
ArrayList list = new ArrayList(); 中调用list.add(e)方法添加10个元素,list扩容(0)次,添加20个元素list扩容几次(2).
解析:ArrayList初始大小为 10, 扩容倍数为 1.5 倍。JDK1.7之前ArrayList扩容倍数是 1.5 + 1, JDK1.8开始ArrayList的扩容倍数才更改为1.5.
15. Java中Thread中的start() 和 run()的区别:
static void pong(){ System.out.print("pong"); } private static void threadTest() { Thread thread = new Thread(){ @Override public void run() { pong(); } }; thread.run(); System.out.print("ping"); }
输出结果:pongping
解析:
1、start() 方法来启动线程,真正实现了多线程运行,这时无需等待run方法体代码执行完毕而直接执行下面的代码
调用Thread中的Start()方法来启动一个线程,这时线程是出于就绪状态,并没有运行,然后通过此Thread类调用run()方法来完成其运行操作的,这里方法run()称为线程体,它包含了要执行线程的内容,run()方法运行结束,此线程终止,而CPU再运行其他线程。
2、run()方法当作普通方法的方式调用,程序还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码
如果直接用run()方法,这只是调用一个方法而已,程序中依然只有主线程 (唯一线程),其程序执行的路径还是只有一条,这样就没有达到写线程的目的。
16. 线程同步的关键字是什么?sleep()和wait()有什么区别?怎么唤醒wait()停止的线程?
synchronized volitale
每个对象都有一个锁来控制同步访问,synchronized关键字可以和对象的锁交互,来实现同步方法或同步块。sleep() 方法正在执行的线程让出CPU(然后CPU可以执行其他任务),在sleep()指定时间后CPU再回到该线程继续往下执行(注意:Sleep方法只让出了CPU,并不会释放资源锁);wait()方法则是指当前线程让自己暂时退出并让出同步资源锁,以便其他正在等待该资源的线程得到该资源进行运行,只有调用了notify()/notifyAll()方法,之前调用wait()的线程才会解除wait()状态,可以参与竞争同步资源锁,进而得到执行。(注意:notify()作用相当于叫醒睡着的人,而并不会给他分配任务,就是说notify()只是让之前调用wait()的线程有权利重新参与线程的调度)
sleep方法可以在任何地方调用,wait方法只能在同步方法或同步块中使用
sleep方法是线程类Thread的方法,调用会暂停此线程指定的时间,但监控依然保持,不会释放对象锁,到时间自动恢复;wait方法是Object方法,调用会放弃对象锁,进入等待队列,待调用notify()/notifyAll()唤醒指定(随机)的线程或所有线程,才会进入锁池。
17. 简述分布式事务除了两阶段提交外的其他解决方案
https://blog.csdn.net/hxpjava1/article/details/79409395
18. Mysql 中 int(5)和int(11)有什么区别?
mysql中int类型默认长度11,其中正负值占用了一个单位的长度,这里的长度仅代表数字的长度,即数字10长度为2,数字100长度为3,以此类推。其实这里长度只是展示的长度,与存储占用的多少无关,即int(1)和int(10)和int(11)的存储空间都是占用4字节,这里是完全一样的
19. 写一个SQL 删除User表中所有重复的token,重复的token只保留id最大的的那个(id为主键)

执行SQL情况:
思路:
1. 先根据token进行分组,筛选token量 大于 1 的记录
2. 根据筛选的token条件,按照id降序排列,然后再按照token分组,筛选出不需要删除的最大id
3. 然后根据id及 token 执行删除,最终达到条件
DELETE FROM user1 WHERE id NOT IN (SELECT uu.id FROM (SELECT u.* FROM user1 u WHERE EXISTS( SELECT u1.token FROM user1 u1 WHERE u1.token = u.token GROUP BY u1.token HAVING COUNT(1) > 1) ORDER BY id DESC) uu GROUP BY uu.token) AND token IN (SELECT uu.token FROM (SELECT u.* FROM user1 u WHERE EXISTS( SELECT u1.token FROM user1 u1 WHERE u1.token = u.token GROUP BY u1.token HAVING COUNT(1) > 1) ORDER BY id DESC) uu GROUP BY uu.token);
