1. Hadoop简介
2. Hadoop环境建立
3. 参考资料
<1>. Hadoop简介
hadoop是apache的开源项目,开发的主要目的是为了构建可靠,可拓展scalable,分布式的系统,hadoop是一系列的子工程的总和,其中包含。
1. hadoop common:为其他项目提供基础设施
2. HDFS:分布式的文件系统
3. MapReduce:A software framework for distributed processing of large data sets on compute clusters。一个简化分布式编程的框架。
4. 其他工程包含:Avro(序列化系统),Cassandra(数据库项目)等
<2>. Hadoop环境建立
这里主要是包含hadoop环境的建立,以便下面能够测试MapReduce和HDFS,注意这里仅仅是在一台主机ubuntu上测试。
2.1 ubuntu必备软件
hadoop需要首先安装jdk和ssh,rsync两个依赖项,这里暂时略去java的安装过程,ubuntu下安装ssh命令如下:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ sudo apt-get install ssh rsync
安装完成之后,试着ssh localhost:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ssh localhost
Linux ubuntu 2.6.28-11-generic #42-Ubuntu SMP Fri Apr 17 01:57:59 UTC 2009 i686
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
To access official Ubuntu documentation, please visit:
http://help.ubuntu.com/
Last login: Fri Apr 22 00:28:54 2011 from localhost
xuqiang@ubuntu:~$
表明ssh安装成功,使用exit命令退出ssh。
2.2 下载hadoop的release版本
http://apache.etoak.com//hadoop/core/
2.3 修改hadoop配置文件
在上一步下载完成的压缩包,解压,目录结构如下:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ls
bin hadoop-mapred-test-0.21.0.jar
c++ hadoop-mapred-tools-0.21.0.jar
common hdfs
conf input
hadoop-common-0.21.0.jar lib
hadoop-common-test-0.21.0.jar LICENSE.txt
hadoop-hdfs-0.21.0.jar logs
hadoop-hdfs-0.21.0-sources.jar mapred
hadoop-hdfs-ant-0.21.0.jar NOTICE.txt
hadoop-hdfs-test-0.21.0.jar output
hadoop-hdfs-test-0.21.0-sources.jar README.txt
hadoop-mapred-0.21.0.jar webapps
hadoop-mapred-0.21.0-sources.jar
hadoop-mapred-examples-0.21.0.jar
其中bin目录下主要是包含启动hadoop的脚本文件,conf目录下是hadoop的配置文件,c++目录是hadoop的c++开发时所需头文件。
修改conf/hadoop-env.sh文件,修改其中的JAVA_HOME选项:
# The java implementation to use. Required.
export JAVA_HOME=/usr/local/myinstall/jdk1.6.0_22/
2.4 试着跑一下hadoop
2.4.1 默认的情况下,hadoop是在一个所谓的standalone mode,下面是一个测试示例:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ mkdir input
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ cp ./conf/* ./input/
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ./bin/hadoop jar ./hadoop-mapred-examples-0.21.0.jar grep input output 'dfs[a-z.]+'
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ cat output/*
3 dfs.class
2 dfs.period
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.file
2.4.2 hadoop能够在一个节点上运行,此时是一个所谓的伪分布模式(pseudo-distributed).修改配置文件conf/core-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改conf/hdfs-site.xml文件:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改conf/mapred-site.xml文件:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
创建hdfs文件系统:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ./bin/hadoop namenode -format
开启hadoop:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ./bin/start-all.sh
上传刚刚建立的input文件夹下的文件到hdfs文件系统中:
bin/hadoop fs -put input/ input
还是第一个例子,但是这里是模拟运行在一个所谓的伪分布式系统中。
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ./bin/hadoop jar ./hadoop-mapred-examples-0.21.0.jar grep input output 'dfs[a-z.]+'
查看运行结果:
打开浏览器:输入如下网址:http://localhost:50070/。

之后选择/usr/xuqiang/output/part-r-00000,结果如下:
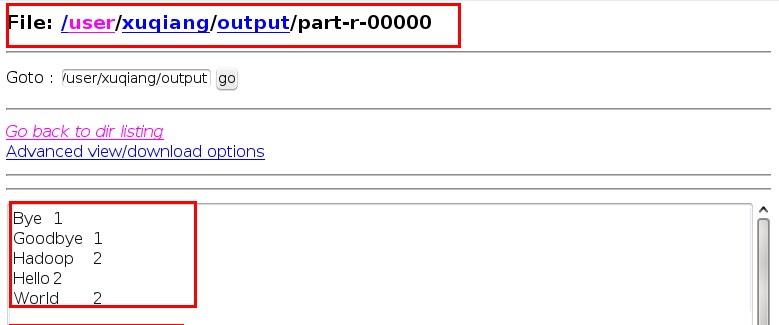
当然除了上面的方法之外还可以使用命令来查看结果,命令如下:
xuqiang@ubuntu:~/hadoop/src/hadoop-0.21.0$ ./bin/hadoop fs -cat output/*
11/04/22 04:54:39 INFO security.Groups: Group mapping impl=org.apache.hadoop.security.ShellBasedUnixGroupsMapping; cacheTimeout=300000
11/04/22 04:54:39 WARN conf.Configuration: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
这里,hadoop的开发环境已经建立完成,但是其中还是存在很多疑惑的地方,这里仅仅是一个初步的学习,下面将更加深入的了解hadoop的一些设计理念和hdfs使用,MapReduce的思想。
<3>. 参考资料
3.1 hadoop home :http://hadoop.apache.org/
3.2 Introduction to Parallel Programming and MapReduce:http://code.google.com/intl/zh-CN/edu/parallel/mapreduce-tutorial.html
3.3 一个异常的解决方法:http://varyall.iteye.com/blog/744773
3.4 开发环境建立:http://hadoop.apache.org/common/docs/current/single_node_setup.html




