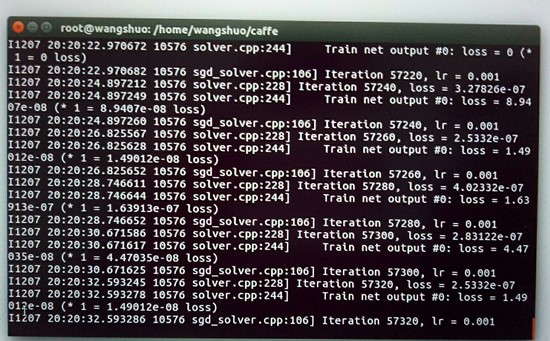
Caffe学习笔记3
Caffe学习笔记3
本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权
欢迎关注我的博客:http://blog.csdn.net/hit2015spring和http://www.cnblogs.com/xujianqing
http://caffe.berkeleyvision.org/gathered/examples/feature_extraction.html
这篇博客主要是用imagenet的一个网络模型来对自己的图片进行训练和测试
图片下载网址:
参考文章:
http://caffe.berkeleyvision.org/gathered/examples/imagenet.html
1、准备数据,生成样本标签
在caffe/data 文件夹下新建文件夹myself
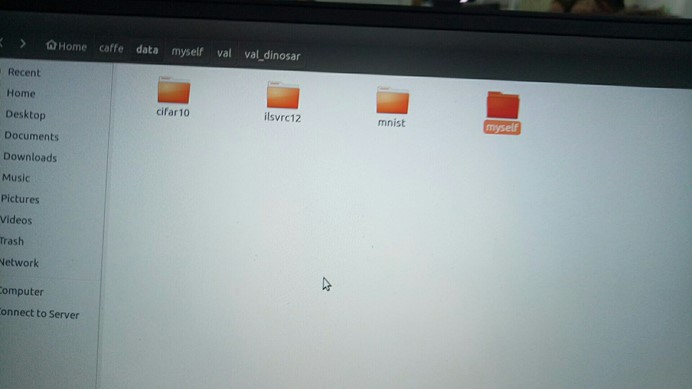
这篇文章主要是帮助你怎么准备你的数据集,怎么训练你自己的模型尺度,在这个笔记中主要是对自己网上下载的车,马,恐龙,花,进行训练和测试,训练2类各80张,测试各20张,放在/data/myself 目录下的train和val文件夹下,这些图片分类好了
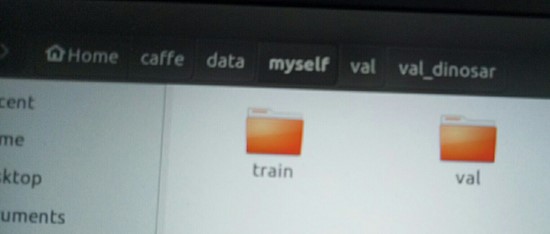



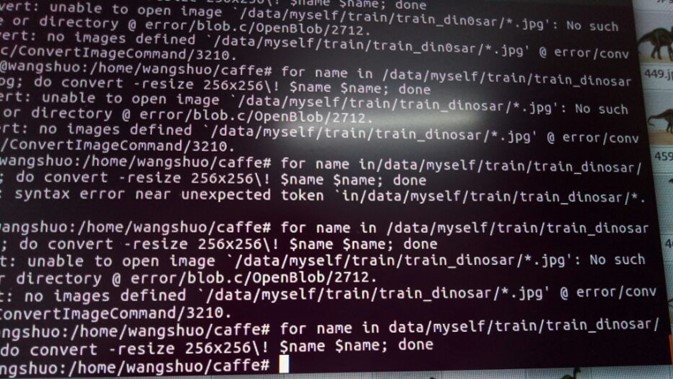
这里面的图像的大小全部为 的,可以在终端用命令行,调整图像大小,训练和测试的图像均为
的,可以在终端用命令行,调整图像大小,训练和测试的图像均为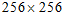
for name in data/myself/val/val_dinosar/*.JPEG; do
convert -resize 256x256\! $name $name
done
给这些图片制作索引标签,生成训练和测试的txt文件,用批量处理工具对这些图片进行处理:在data/myself/ 文件夹下面建立一个label.py的python脚本文件

#<pre name="code"class="python"> #coding:utf-8 ''''' Created on Jul 29, 2016 @author: sgg ''' "<span style=""font-family:Arial;font-size:18px;"">" "<span style=""font-size:18px;"">" "<span style=""font-size:18px;"">" import os def IsSubString(SubStrList,Str): flag=True for substr in SubStrList: if not(substr in Str): flag=False return flag #扫面文件 def GetFileList(FindPath,FlagStr=[]): FileList=[] FileNames=os.listdir(FindPath) if len(FileNames)>0: for fn in FileNames: if len(FlagStr)>0: if IsSubString(FlagStr,fn): fullfilename=os.path.join(FindPath,fn) FileList.append(fullfilename) else: fullfilename=os.path.join(FindPath,fn) FileList.append(fullfilename) if len(FileList)>0: FileList.sort() return FileList train_txt=open('train.txt','w') #制作标签数据,如果是狗的,标签设置为0,如果是猫的标签为1 imgfile=GetFileList('train/train_dinosar')#将数据集放在与.py文件相同目录下 for img in imgfile: str1=img+' '+'4'+'\n' #用空格代替转义字符 \t train_txt.writelines(str1) imgfile=GetFileList('train/train_ele') for img in imgfile: str2=img+' '+'3'+'\n' train_txt.writelines(str2) #imgfile=GetFileList('train/train_flower')#将数据集放在与.py文件相同目录下 #for img in imgfile: # str3=img+' '+'2'+'\n' #用空格代替转义字符 \t # train_txt.writelines(str3) #imgfile=GetFileList('train/train_horse') #for img in imgfile: # str4=img+' '+'1'+'\n' # train_txt.writelines(str4) #imgfile=GetFileList('train/train_truck') #for img in imgfile: # str5=img+' '+'0'+'\n' # train_txt.writelines(str5) train_txt.close() #测试集文件列表 test_txt=open('val.txt','w') #制作标签数据,如果是男的,标签设置为0,如果是女的标签为1 imgfile=GetFileList('val/val_dinosar')#将数据集放在与.py文件相同目录下 for img in imgfile: str6=img+' '+'4'+'\n' test_txt.writelines(str6) imgfile=GetFileList('val/val_ele') for img in imgfile: str7=img+' '+'3'+'\n' test_txt.writelines(str7) #imgfile=GetFileList('val/val_flower')#将数据集放在与.py文件相同目录下 #for img in imgfile: # str8=img+' '+'2'+'\n' # test_txt.writelines(str8) #imgfile=GetFileList('val/val_horse') #for img in imgfile: # str9=img+' '+'1'+'\n' # test_txt.writelines(str9) #imgfile=GetFileList('val/val_truck') #for img in imgfile: # str10=img+' '+'0'+'\n' # test_txt.writelines(str10) test_txt.close() print("成功生成文件列表")
在终端运行该脚本
python label.py
可以在data/myself/ 文件夹下生成两个txt文件,train.txt和val.txt


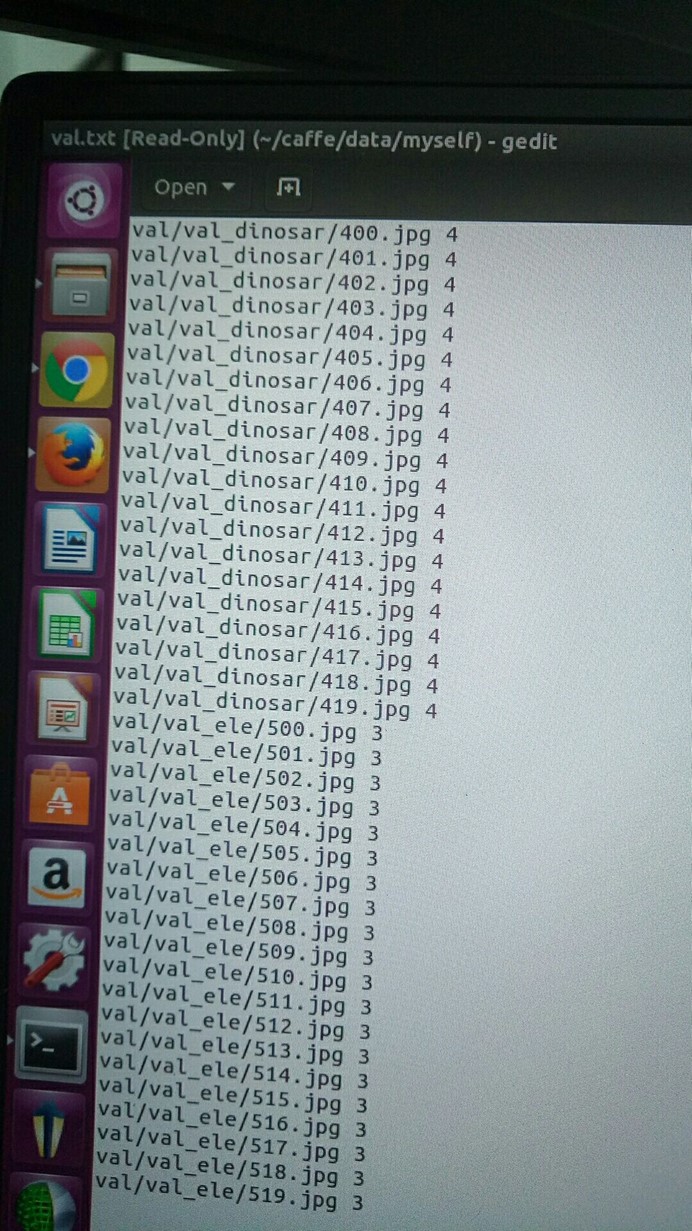
2、生成lmdb文件
在caffe/ 文件夹下新建myself文件夹,
从/home/xxx/caffe/examples/imagenet下复制create_imagenet.sh文件到caffe/myself
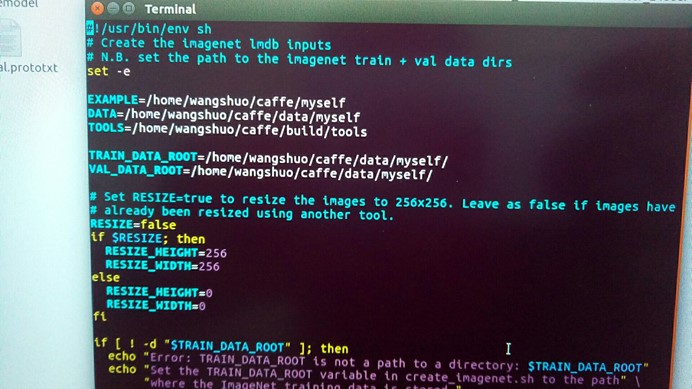
其中:
EXAMPLE =/home/wangshuo/caffe/myself
表示生成的LMDB文件存放的位置
DATA=/home/wangshuo/caffe/data/myself
表示数据标签存放的位置
TRAIN_DATA_ROOT=/home/wangshuo/caffe/data/myself/
VAL_DATA_ROOT=/home/wangshuo/caffe/data/myself/
表示训练和测试数据的位置,注意这里只填到myself这一级的目录。
GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_width=$RESIZE_WIDTH \ --shuffle \ $TRAIN_DATA_ROOT \ $DATA/train.txt \ $EXAMPLE/ilsvrc12_train_lmdb echo "Creating val lmdb..." GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_width=$RESIZE_WIDTH \ --shuffle \ $VAL_DATA_ROOT \ $DATA/val.txt \ $EXAMPLE/ilsvrc12_val_lmdb
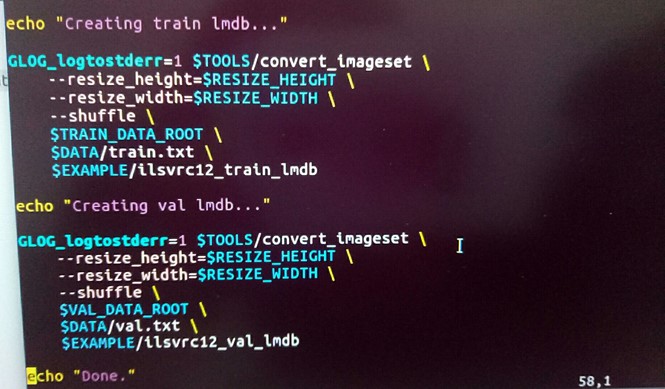
EXAMPLE/ilsvrc12_val_lmdb
表示生成文件名为ilsvrc12_train_lmdb 和ilsvrc12_val_lmdb
在caffe根目录下运行create_imagenet.sh
./myself/create_imagenet.sh
在caffe/myself文件夹下生成lmdb文件
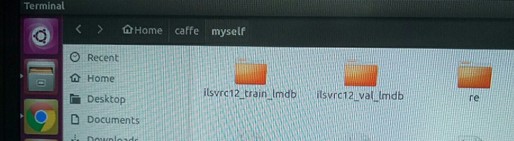
3、生成均值文件
从caffe/ examples/imagenet/ 拷贝make_imagenet_mean.sh文件到caffe/myself 文件夹下
修改该文件
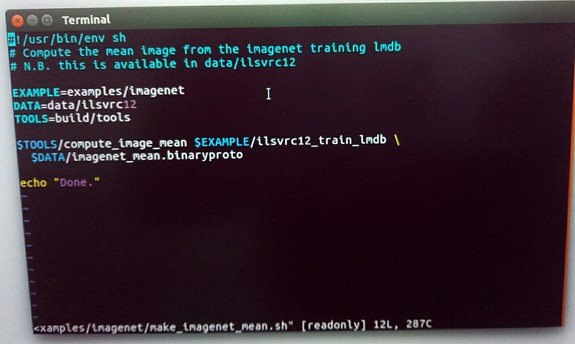
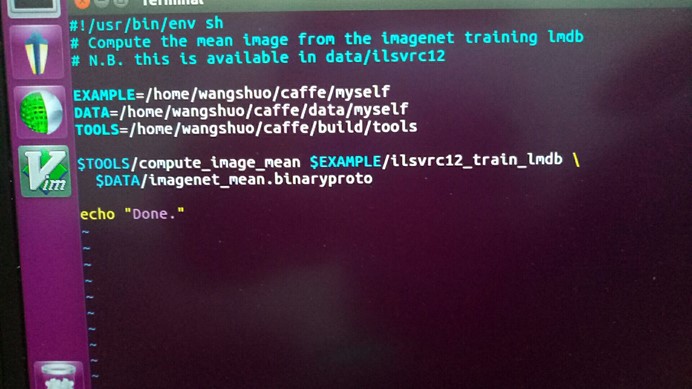
EXAMPLE=/home/wangshuo/caffe/myself##上面生成的lmdb文件目录
DATA=/home/wangshuo/caffe/data/myself###生成文件所要存放的目录
TOOLS=/home/wangshuo/caffe/build/tools
在caffe根目录下运行该文件
./myself/make_imagenet_mean.sh
在caffe/data/myself 下生成imagenet_mean.binaryproto文件
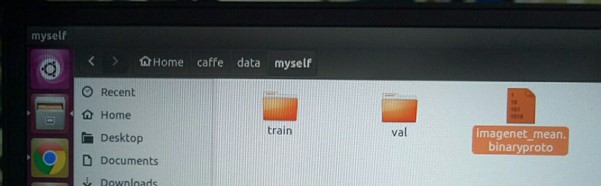
4、模型定义
复制models/bvlc_reference_caffenet/train_val.prototxt到caffe/myself文件夹,并修改路径
|
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" source: "examples/imagenet/ilsvrc12_train_lmdb" mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" source: "examples/imagenet/ilsvrc12_val_lmdb" |
|
mean_file: "data/myself/imagenet_mean.binaryproto" source: "myself/ilsvrc12_train_lmdb" mean_file: "data/myself/imagenet_mean.binaryproto" source: "myself/ilsvrc12_val_lmdb" |

这里还有一个bitch_size的参数,该参数如果过大,会提示GPU内存不够,在这里我设置为8
复制models/bvlc_reference_caffenet/solver.prototxt到caffe/myself
文件夹下,并修改文件路径
net: "myself/train_val.prototxt" ##模型所在目录 snapshot_prefix: "myself/caffenet_train"##生成的模型参数
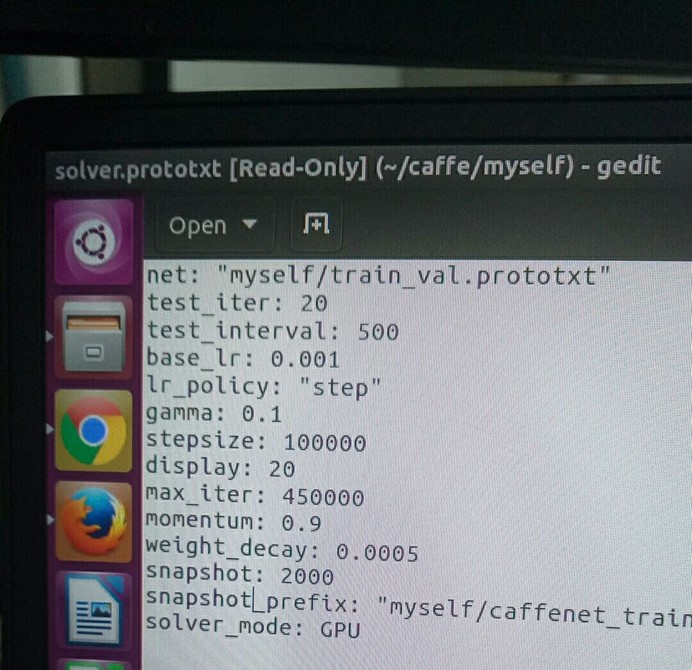
test_iter: 1000 是指测试的批次,我们就 20 张照片,设置20就可以了。
test_interval: 1000 是指每 1000 次迭代测试一次,我们改成 500 次测试一次。
base_lr: 0.01 是基础学习率,因为数据量小, 0.01 就会下降太快了,因此改成 0.001
lr_policy: "step"学习率变化
gamma: 0.1 学习率变化的比率
stepsize: 100000 每 100000 次迭代减少学习率
display: 20 每 20 层显示一次
max_iter: 450000 最大迭代次数,
momentum: 0.9 学习的参数,不用变
weight_decay: 0.0005 学习的参数,不用变
snapshot: 10000 每迭代 10000 次显示状态,这里改为 2000 次
solver_mode: GPU 末尾加一行,代表用 GPU 进行
5、训练
在caffe根目录下运行
|
./build/tools/caffe time --model=myself/train_val.prototxt |