
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
传送门:
摘要
1.实现了高精确度的多类目标检测任务同时通过调整和结合最近的技术创新达到最小化计算cost的目标
2.使用" CNN feature extraction + region proposal + RoI classification"的结构,主要对feature extraction(特征提取)进行重新设计。因为,region proposal部分计算量不太大而且classification部分可以使用通用的技术(例如:truncated SVD)进行有效的压缩。
3.设计原则:less channels with more layers 和 采用一些building blocks(包括:串级的ReLU、Inception和HyperNet)
4.设计的网络deep and thin,在batch normalization、residual connections和基于plateau detection的learning rate的调整的帮助下进行训练。
5.结果:VOC2007——83.8%mAP;VOC2012——82.5%mAP,46ms/image在NVIDIA Titan X GPU;计算量是ResNet-101的12.3%(理论上)
1 介绍
准确率很高的检测算法有heavy computational cost,现在压缩和量化技术的发展对减小网络的计算量很重要。这篇文章展示了我们用于目标检测的一个轻量级的特征提取的网络结构——PVANET,它达到了实时的目标检测性能而没有损失准确率(与现在先进的系统比较):
- Computational cost:输入1065*640大小的图像在特征提取时需要7.9GMAC(ResNet-101:80.5GMAC)
- Runtime performance:750ms/image (1.3FPS) 在 Intel i7-6700K CPU (单核);46ms/image (21.7FPS) on NVIDIA Titan X GPU
- Accuracy: 83.8% mAP on VOC-2007; 82.5% mAP on VOC-2012 (2nd place)
设计的关键:less channels with more layers 和 采用一些building blocks(其中有的未证实对检测任务有效)
1.串级的ReLU(C.ReLU——Concatenated rectified linear unit)被用在我们的CNNs的初期阶段来减少一半的计算数量而不损失精度。
2.Inception被用在剩下的生成feature的子网络中。一个Inception module产生不同大小的感受野(receptive fields)的输出激活值,所以增加前一层感受野大小的变化。我们观察叠加的Inception modules可以比线性链式的CNNs更有效的捕捉大范围的大小变化的目标。
3.采用multi-scale representation的思想(像HyperNet中)结合多个中间的输出,所以,这使得可以同时考虑多个level的细节和非线性。
我们展示设计的网络deep and thin,在batch normalization、residual connections和基于plateau detection的learning rate的调整的帮助下进行有效地训练
网络的简单的描述——2;PVANET的细节总结——3;实验,训练和测试的细节——4
2 网络设计的细节
2.1 C.ReLU:Earlier building blocks in feature generation
C.ReLU来源于CNNs中间激活模式引发的。输出节点倾向于是"配对的",一个节点激活是另一个节点的相反面。根据这个观察,C.ReLU减少一半输出通道(output channels)的数量,通过简单的连接相同的输出和negation使其变成双倍,即达到原来输出的数量,这使得2倍的速度提升而没有损失精度。
C.ReLU的实现:
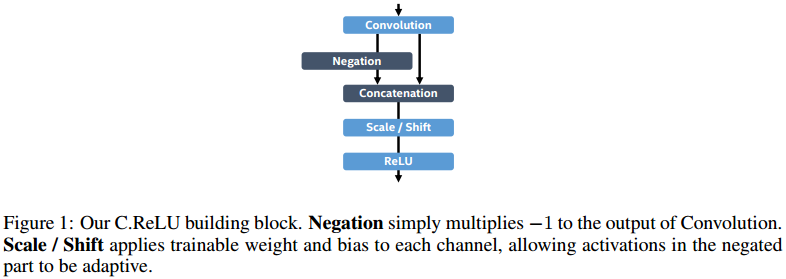
与原始的C.ReLU相比,我们增加了scaling and shifting(缩放和移动)在concatenation(串联)之后,这允许每个channel(通道)的斜率和激活阈值与其相反的channel不同。
2.2 Inception:Remaining building blocks in feature generation
Inception没有广泛的使用在现存的网络中,也没有验证其有效性。我们发现Inception是用于捕获输入图像中小目标和大目标的最具有cost-effective(成本效益)的building blocks之一。为了学习捕获大目标的视觉模式,CNNs的输出特征应该对应于足够大的感受野,这可以很容易的通过叠加 3*3或者更大的核(kernel)卷积实现。在另外一方面,为了捕获小尺寸的物体,输出特征应该对应于足够小的感受野来精确定位小的感兴趣region。

上面所示的Inception可满足以上需求。最后面的1*1的conv扮演了关键的角色,它可以保留上一层的感受野(receptive field)。只是增加输入模式的非线性,它减慢了一些输出特征的感受野的增长,使得可以精确地捕获小尺寸的目标。
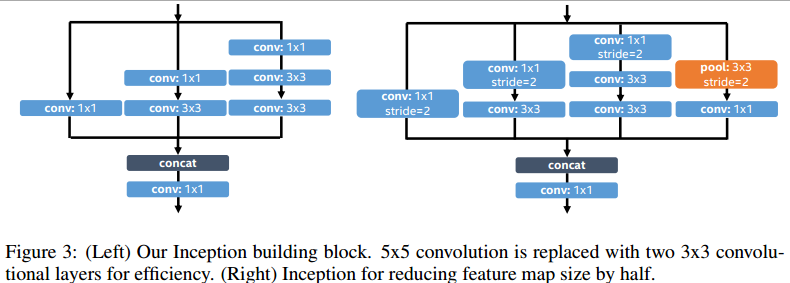
上图说明了实现的Inception。5*5的conv用2个顺序的3*3的conv代替。
2.3 HyperNet:Concatenation of multi-scale intermediate outputs(连接多尺度的中间输出)
多尺度表示和它们的结合在许多dl任务中被证明是有效的。细粒度细节与高度概括的语义信息的结合有助于随后的region proposal网络和分类网络检测不同尺度的目标。然而,因为直接连接所有的abstraction layers也许产生有很多计算需要求的冗余信息(redundant information),我们需要仔细设计不同 abstraction layers和layers的数量。如果选择的层对于object proposal和分类太早的话,当我们考虑增加计算复杂度的话帮助很小。
我们的设计选择不同于ION和HyperNet。We choose the middle-sized layer as a reference scale (= 2x), and concatenate the 4x-scaled layer and the last layer with down-scaling (pooling) and up-scaling (linear interpolation), respectively.
2.4 深度网络训练
随着网络深度的增加,训练会更加的麻烦。我们采用residual structures解决此问题。
与原residual不同,
1.我们将residual连接到Inception layers以稳定网络框架的后半部分,
2.我们在所有的ReLU 激活层(activation layers)前添加Batch normalization layers。mini-batch样本统计用于pre-training阶段,并且随后moving-averaged统计作为固定的尺度和移动的参数。
3.学习率策略对成功地训练网络也很重要。我们的策略是:基于plateau detection动态地控制学习率。我们采用移动平均数(moving average)损失并且如果在某次的迭代周期期间其改进低于一个阀值,则将其确定为on-plateau(高原)。无论何时plateau被检测到,学习率减少一个常数因子。在实验中,我们的学习率策略对准确率有一个显著的结果。
3 Faster R-CNN with our feature extraction network
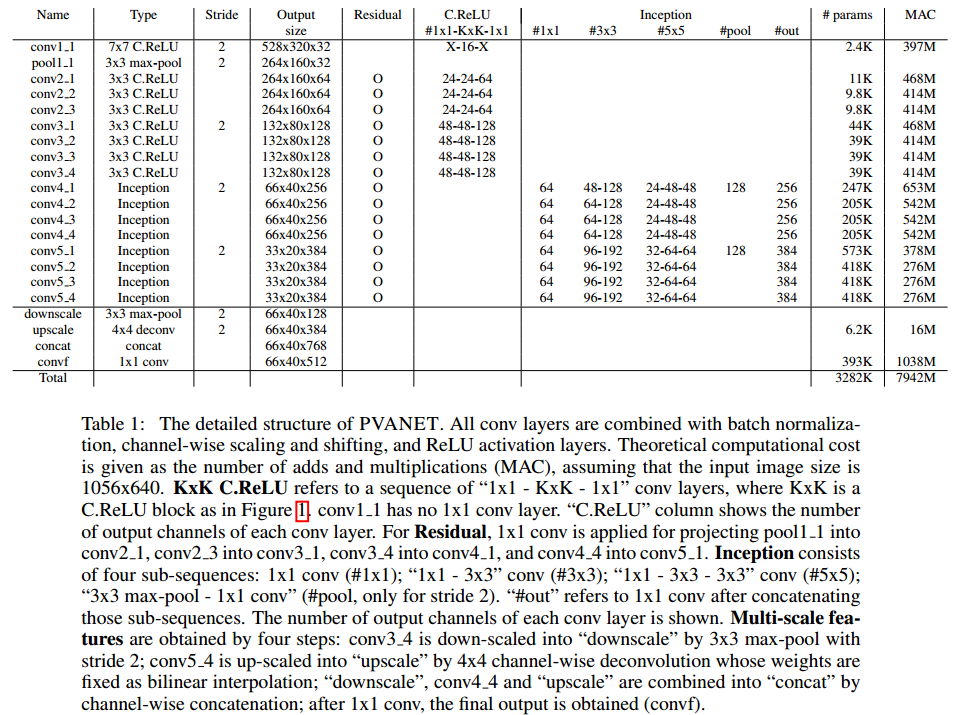
表一显示了PVANET的整个结构。在初期(conv1_1,...,conv3_4),C.ReLU用在卷积层来减少一半K*K conv的计算消耗。1*1conv layers添加在K*K conv的前面和后面,目的是减少输入的大小然后分别表示的能力。
三个中间输出conv3_4(with down-scaling)、conv4_4和conv5_4(with up-scaling)结合到512-channel多尺度输出特征(convf),之后被送到Faster R-CNN模型:
•计算的有效性。仅convf的前128通道被送到the region proposal network(RPN)。我们的RPN是一系列"3*3conv(384channels- 1x1 conv(25x(2+4) = 150 channels)"层来生成regions of interest(RoIs)。
•R-CNN采用convf中的全部512 channels。对于每一个RoI,RoI pooling 生成 6*6*512 tensor(张量),之后通过一系列的"4096-4096-(21+84)"的输出节点的FC layers。
4 Experimental results
4.1 Training and testing
PVANET 用1000类别的 ILSVRC2012 训练图像进行预训练。所有的图像被调整到256*256大小,之后随机裁剪成192*192的patches被作为网络的输入。学习率的初值设为0.1,之后只要检测到plateau时就以因子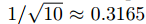 减少。若学习率小于1e-4就终止预训练,这个过程大约需要2M次迭代。
减少。若学习率小于1e-4就终止预训练,这个过程大约需要2M次迭代。
减少。若学习率小于1e-4就终止预训练,这个过程大约需要2M次迭代。 之后,PVANET在联合的数据集(MS COCO trainval,VOC2007 trainval 和 VOC2012 trainval)训练。之后用VOC2007 trainval 和 VOC2012 trainval进行fine-tuning(微调)也是需要的,因为在MS COCO和VOC竞赛的类别定义是稍有不同。训练数据被随机的调整大小,图像较短的边的长度在416和864之间。
对于PASCAL VOC评价,每个输入图像调整大小使其短的一边为640。所有有关Faster R-CNN的参数被设置在原始的work中,除了在极大值抑制(NMS:non-maximum suppression)(=12000)前的proposal boxes的数量和NMS的阈值(=0.4)。所有的评估在单核的Intel i7-6700K CPU和 NVIDIA Titan X GPU 上完成。
4.2 VOC2007
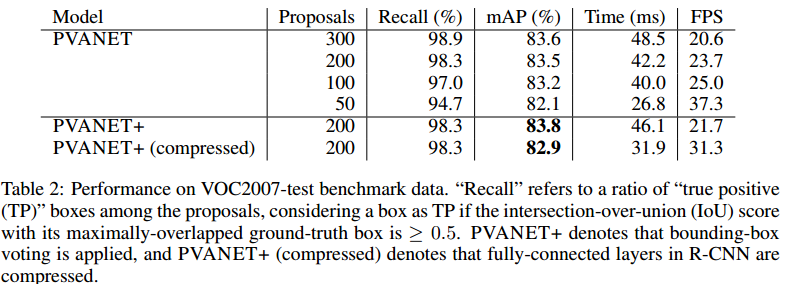
Table2展示了我们的模型在不同配置下的准确率。由于Inception和多尺度feature,我们的RPN产生的initial proposals非常的准确。因为结果表示超过200个proposals没有对检测的准确率起到显著的帮助,我们在剩下的实验中把proposals 的数量固定在200个。我们也测量了当迭代回归不使用时用带有bounding-box voting的性能。
Faster R-CNN包含的FC layer,它容易压缩并且准确率没有显著的下降。我们通过the truncated singular value decomposition (SVD)把"4096-4096"的FC layer压缩成"512-4096-412-4096",之后进行一些微调。这个压缩的网络达到了82.9%mAP(-0.9%)而且运行达到了31.3FPS(+9.6FPS)
4.3 VOC2012
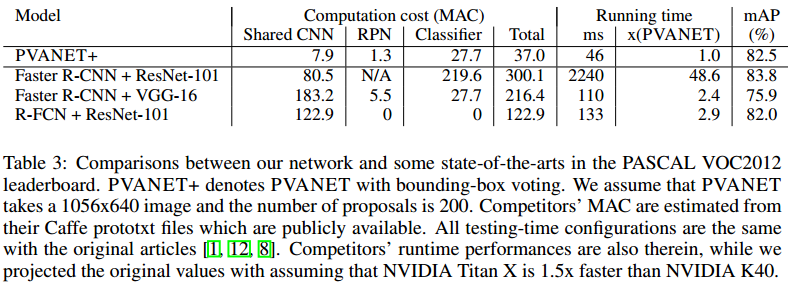
Table3总结了PVANET+和一些先进的网络在PASCAL VOC2012排行榜上的比较。我们PVANET+达到了82.5%mAP,位列排行榜的第二名,超过其他竞争者除了"Faster R-CNN + ResNet-101"。然而第一名使用的ResNet-101比PVANET大很多同时一些耗时的技术,例如global contexts(全局上下文)和多尺度测试,导致至少比我们慢40倍。在Table3,won,我们也比较computation cost。在所有超过80%mAP的网络中,PVANET是唯一一个运行时间小于50ms的。考虑精度和计算cost,PVANET+是排行榜中最有效的网络。

