


[python]爬代理ip v2.0(未完待续)
爬代理ip
所有的代码都放到了我的github上面,
HTTP代理常识
HTTP代理按匿名度可分为透明代理、匿名代理和高度匿名代理。
特别感谢:勤奋的小孩 在评论中指出我文章中的错误。
REMOTE_ADDR
HTTP_VIA
HTTP_X_FORWARDED_FOR
你写的这三个,第一个是网络层的信息,不属于HTTP的头部,后两个在HTTP头部的名称也是不含“HTTP_”的
wiki中关于代理的解释也出现了这个错误:
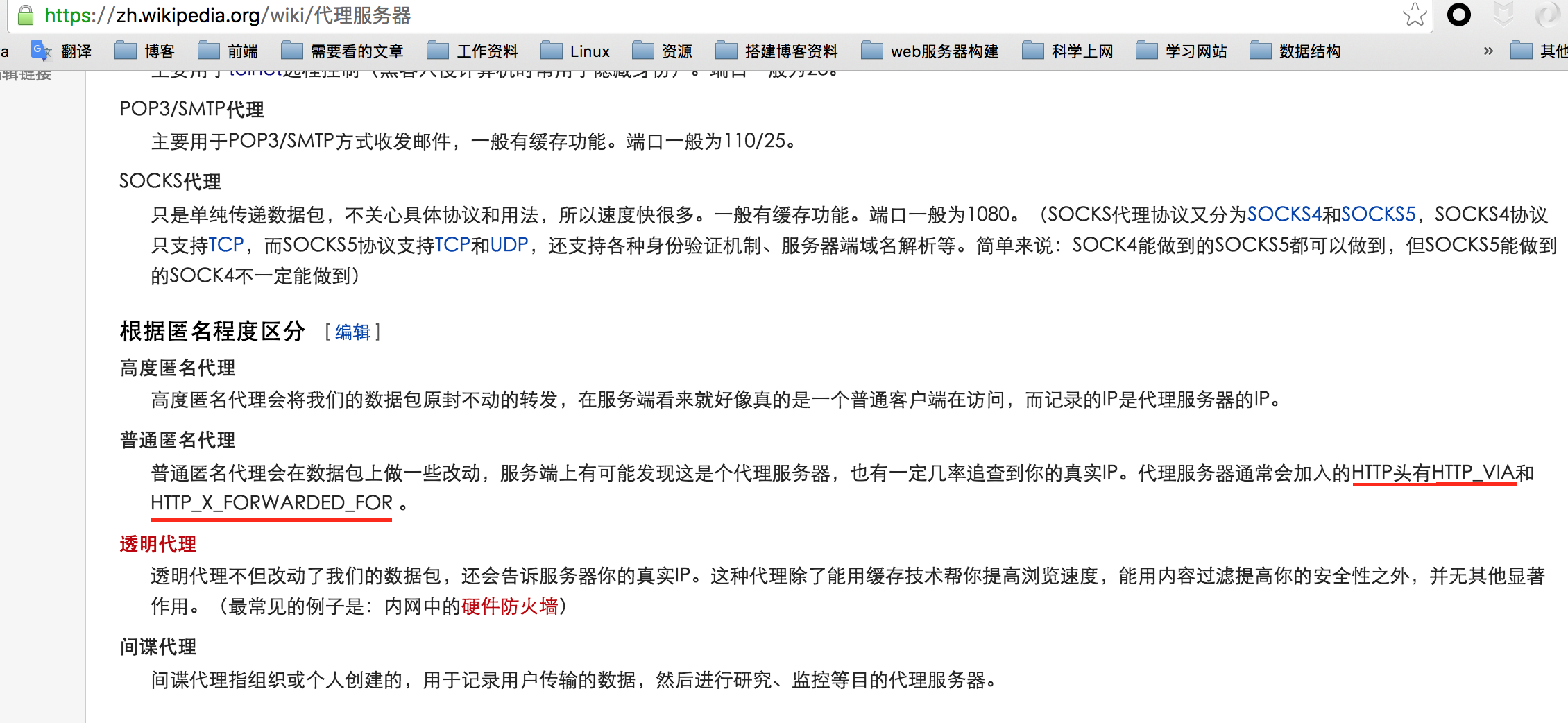
因为我挂的代理,无法修改wiki上的这个错误,希望可以修改的同学可以编辑修改之,方便以后查阅的同学。
代理请求的示例,参考:
GET / HTTP/1.1
Host: [scrubbed server host]:8080
Connection: keep-alive
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-ms-application, application/vnd.ms-xpsdocument, application/xaml+xml, application/x-ms-xbap, */*
Accept-Language: ru
UA-CPU: x86
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; SLCC1; .NET CLR 2.0.50727; .NET CLR 3.0.04506)
X-Forwarded-For: [scrubbed client's real IP address]
Via: 1.1 proxy11 (NetCache NetApp/5.6.1D24)
1.使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
透明代理访问对方服务器所带的HTTP头信息如下:
VIA = 代理服务器IP
X_FORWARDED_FOR = 你的真实IP
透明代理还是将你的真实IP发送给了对方服务器,因此无法达到隐藏身份的目的。
2.使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
匿名代理访问对方服务器所带的HTTP头信息如下:
VIA = 代理服务器IP
X_FORWARDED_FOR = 代理服务器IP
匿名代理隐藏了你的真实IP,但是向访问对象透露了你是使用代理服务器访问他们的。
3.使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
高匿名代理访问对方服务器所带的HTTP头信息如下:
VIA 不显示
X_FORWARDED_FOR 不显示
高匿名代理隐藏了你的真实IP,同时访问对象也不知道你使用了代理,因此隐蔽度最高。
概述
起因:我这次是准备爬取‘高匿的ip’,做一个ip库,方便后面的爬虫。这是因为,很多网站或者api接口,都设置了‘访问间隔时间’(一个ip有访问次数的限制,超过次数就需要进入‘冷却CD’)。所以,用我的真实ip,无法高效、快速的爬取内容。
因为工作中使用tornado框架,它带一个很好用的HTTPClient的库,所以这次我就直接用它来完成,爬代理ip的工作。我写了一个Spider类,用于爬url的内容。Content用于存储内容。
class Spider(object):
"""
爬取
"""
def __init__(self, url, **kwargs):
# 实例化HTTPRequest对象,用于伪造浏览器的请求
self.request = HTTPRequest(url, **dict(CLIENT_CONFIG, **kwargs))
def get(self, **kwargs):
return HTTPClient().fetch(self.request, **kwargs)
def post(self):
self.request.method = 'POST'
return HTTPClient().fetch(self.request)
class Content(object):
"""
存储内容到数据库
"""
def __init__(self):
self.url = None
self.content = None
def get_content(self, url, content):
self.url = url
self.content = content
def save(self):
create_time = datetime.datetime.now()
data = models.Data(url=self.url, content=self.content, create_time=create_time)
data.insert()
爬目标网站
目标网站:国内高匿代理ip,在爬虫v1.0中,当时爬的太顺利了,直接爬就行了,根本不用设置HTTP头。
1. 所以在爬这次的目标网站的时候,就遇到了错误。最后,因为需要设置头为长连接,否则会返回Timeout。所以爬虫v2.0,我就建立了一个配置文件,里面设置好了相关的头信息。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#
# Author : XueWeiHan
# E-mail : 595666367@qq.com
# Date : 16/4/22 下午6:39
# Desc : 客户端请求的常用数据
CLIENT_CONFIG = {
'headers': {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/'
'49.0.2623.110 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0'
'.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
}
2. 目前为止,爬虫的配置已经做好了,下面就是具体的爬取内容的逻辑了。代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#
# Author : XueWeiHan
# E-mail : 595666367@qq.com
# Date : 16/4/23 上午10:40
# Desc : 获取ip
from spider import Spider, Content
s = Spider('http://www.xicidaili.com/nn/')
print s.get().code # 输出为:200
# 表示成功获取到url内容,下面开始分析内容,提取内容
3. 接下来和爬虫v1.0一样,分析网站的内容,这次我是使用的'BeautifulSoup'库。使用这个库,就相当于js中的jquery。使用它的选择器,获取页面元素变的便利BeautifulSoup官方文档
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#
# Author : XueWeiHan
# E-mail : 595666367@qq.com
# Date : 16/4/23 上午10:40
# Desc : 获取代理ips
from bs4 import BeautifulSoup
from spider import Spider
def get_ip_info(html_response):
""" 清理内容得到IP信息 """
ips_list = []
soup = BeautifulSoup(html_response.body, "html.parser")
ip_list_table = soup.find(id='ip_list')
for ip_info in ip_list_table.find_all('tr'):
ip_detail = ip_info.find_all('td')
if ip_detail:
ips_list.append(dict(ip=list(ip_detail)[2].string,
port=list(ip_detail)[3].string))
return ips_list
s = Spider('http://www.xicidaili.com/nn/')
response = s.get()
ips = get_ip_info(response)
import pprint
pprint.pprint(ips)
#输出如下:
[{'ip': u'110.73.1.204', 'port': u'8123'},
{'ip': u'171.39.0.98', 'port': u'8123'},
....
{'ip': u'113.85.116.223', 'port': u'9999'}]
4. ip都已经获取到了,下面就是把它存起来了。我修改了Content类,提供了存到文件中的方法。代码如下:
class Content(object):
"""
存储内容到数据库
"""
def __init__(self, model=None):
self.model = model
def save(self, kwargs):
if self.model:
data = self.model(**kwargs)
data.insert()
else:
print 'no model'
@staticmethod
def save_to_file(all_content, str_split=':', path='./data.txt'):
"""
把数据存到文件中
:param all_content: 需要是list类型
:param str_split: 分割符号
:param path: 文件位置,默认为当前脚本运行的位置,文件名:data.txt
"""
with open(path, 'w') as fb:
print '开始写入文件'
for content in all_content:
content_str = ''
for k, v in content.items():
content_str += v + str_split
fb.write(content_str+'\n')
print '写入文件完成'
TODO
未完待续,电脑要没电了,还没带电源。。。。
作者:削微寒
扫描左侧的二维码可以联系到我

本作品采用署名-非商业性使用-禁止演绎 4.0 国际 进行许可。
