

Java对文件的读、写随机访问,RandomAccessFile类的使用分析
在网上看了一些关于java中的RandomAccessFile类的介绍,又经过查看Java API和自己编的测试程序,总算是对RandomAccessFile的使用有了一定的了解。自己做了以下比较详细的总结吧。
1.RandomAccessFile类的简单介绍
该类的实例支持对文件的随机读取和写入。随机存取文件的行为类似存储在文件系统中的一个大型字节数组。存在指向该隐含数组的光标或索引,称为文件指针。读取操作从文件指针开始读取字节,并随着对字节的读取而前移此文件指针。如果随机存取文件以读取/写入模式创建,则写入操作也可用;写入操作从文件指针开始写入字节,并随着对字节的写入而前移此文件指针。该文件指针可以通过 getFilePointer 方法读取,并通过 seek 方法设置。
通常,如果此类中的所有读取例程在读取所需数量的字节之前已到达文件末尾,则抛出 EOFException。如果由于某些原因无法读取任何字节,而不是在读取所需数量的字节之前已到达文件末尾,则抛出 IOException。需要特别指出的是,如果流已被关闭,则可能抛出 IOException。
2.一个文件读取错误例子引出的思考
import java.io.RandomAccessFile; public class RandomAccessFile_test { public static void main(String args[]) throws Exception{ RandomAccessFile access=new RandomAccessFile("c:\\a.txt","rw"); //文件a.txt中只有一个整数1234 System.out.println("文件长度为:"+access.length()); System.out.println("读出的数据位:"+access.readInt()); access.close(); } }
执行输出: 文件长度为:4
读出的数据位:825373492
分析:这是因为RandomAccessFile类的实例都是根据要读取的数据类型来读取指定大小的数据块到变量。int类型占4个字节,因此readInt()函数会从文件开头读取四个字节,每个字节都当做ASCII码。读到的四个ASCII码字节是‘1’,‘2’,‘3’,‘4’,对应十六进制为31H,32H,33H,34H,即31323334H=825373492D。
3.随机读写文件的存储图示
3.1数据存放
(1)用RandomAccessFile类写入的数据一般都是按照ASCII字符的形式保存在文件中的,即以字节的形式,字节是计算机存储设备编址的最小单元。
(2)Java中各数据类型所占的字节数,如图表所示:
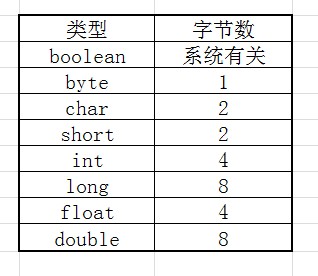
(3)如下图就是依次写入int,byte,double,int,byte,short,short数据时,在文件中的存放。文件指针会随着数据的写入按照写入后移。
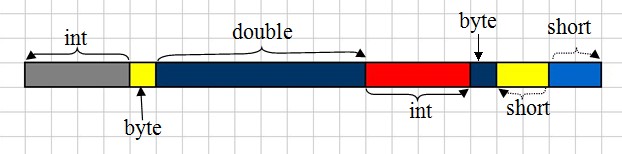
3.2数据读取
(1)如用readInt()方法读取一个int数据。文件指针会从当前位置向后读取去四个字节的数据,将取到的数据在强制转换为int类型返回即可,同时文件指针也自动的向后移动了相应的四个位置。
(2)如果先用readByte()方法读取一个byte数据,读取后文件指针移动了一个位置(还在int原本的四个字节中),这样再用readInt()方法读取一个int数据就会出现乱码。
(3)也就是说用RandomAccessFile类来操作文件,应该知道数据事先是如何存放的,之后用相应的读取就能顺序的读出,而不会出现乱码。
4.特殊的数据读取
4.1字符串读readUTF()和字符串写writeUTF(String str)
这2个方法都带有“UTF”,是因为写入数据时按照utf-8编码写入,读取时也是utf-8。
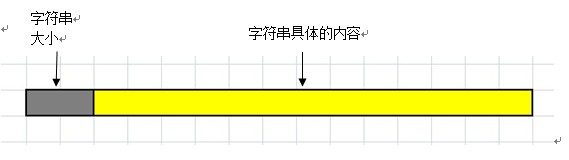
每次写入的字符串的长度是不一定的。因为Java API给出了读取与写入字符串是成对的,因此需要标记每次写入的字符串的长度。每次写入字符串时,会分配2个字节来保存,要写入的字符串的大小,也就是一次写入字符串的大小应该不能大于65536个字节。每次读取的字符串时,先从文件指针的位置开始读取2个字节,分析得到要读取字符串的长度,之后在进行读取。如下图所示:
程序举例:写入2次字符串。
import java.io.RandomAccessFile; public class Char_Byte{ public static void main(String args[]) throws Exception{ RandomAccessFile access=new RandomAccessFile("C:\\a.txt","rw"); //“读写”方式建立类的实例 access.writeUTF("你好"); //以utf-8格式写入数据 access.writeUTF("朋友"); //以utf-8格式写入数据 access.close(); } }
查看生成文件: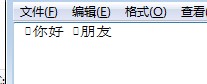 ,可以看到在汉字的前面有一些字符,其实就是2个字节的标记字符串长度的ASCII编码。
,可以看到在汉字的前面有一些字符,其实就是2个字节的标记字符串长度的ASCII编码。
4.2读取一行readLine()
(1)Java API中只有读取一行readLine()方法,然而没有写入一行writeLine()的方法。
(2)在Windows下的行结束符号是“\r\n”。执行readLine()方法,从当前的文件指针开始读取,直到遇到“\r\n”或者文件结束为止。
(3)此方法不支持完整的 Unicode 字符集。所以用writeUTF(String str)写入的中文需要相应的readUTF()读取,以免出现乱码。汉字的UTF-8编码占3个字节,而GBK占用2个字节,汉字的Unicode编码占2字节。
(4)在写文件时,为了可以更换使用readLine(),需要自己写入行结束符号是“\r\n”。
程序举例:写入2次字符串,以行结束符号隔开。
import java.io.RandomAccessFile; public class Char_Byte{ public static void main(String args[]) throws Exception{ RandomAccessFile access=new RandomAccessFile("C:\\a.txt","rw"); //“读写”方式建立类的实例 access.writeBytes("Hello world!!!"); //写入数据 access.writeBytes("\r\n");//写入行结束符号 access.writeUTF("he he"); //以utf-8格式写入数据 access.close(); access=new RandomAccessFile("C:\\a.txt","rw"); String context=access.readLine(); //读取数据 access.close(); System.out.println(context); } }
程序输出:Hello world!!!
5.总结
(1)RandomAccessFile类可以进行文件的随机读写,就好比对一个大型的数组的操作,对于大文件来说速度是比较慢的。
(2)RandomAccessFile类的实例是根据给定的数据类型大小写入和读取数据,因此用writeXXX()写入的数据,最好用相应的readXXX()来读取。
(3)RandomAccessFile类的实例写入也是按照字节顺序的写入,生成文件的。要读取这样的文件就必须知道是如何生成的,否则很可能出现读取出乱码。
参考:
1.Java API文档


