

LCS最长公共子序列(最优线性时间O(n))
这篇日志主要为了记录这几天的学习成果。
最长公共子序列根据要不要求子序列连续分两种情况。
只考虑两个串的情况,假设两个串长度均为n.
一,子序列不要求连续。
(1)动态规划(O(n*n))
(转自:http://www.cnblogs.com/xudong-bupt/archive/2013/03/15/2959039.html)
动态规划采用二维数组来标识中间计算结果,避免重复的计算来提高效率。
1)最长公共子序列的长度的动态规划方程
设有字符串a[0...n],b[0...m],下面就是递推公式。字符串a对应的是二维数组num的行,字符串b对应的是二维数组num的列。
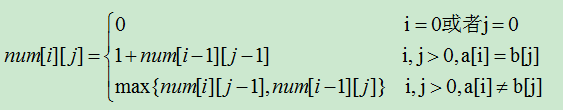
另外,采用二维数组flag来记录下标i和j的走向。数字"1"表示,斜向下;数字"2"表示,水平向右;数字"3"表示,竖直向下。这样便于以后的求解最长公共子序列。
代码:


1 #include<stdio.h> 2 #include<string.h> 3 4 char a[500],b[500]; 5 char num[501][501]; ///记录中间结果的数组 6 char flag[501][501]; ///标记数组,用于标识下标的走向,构造出公共子序列 7 void LCS(); ///动态规划求解 8 void getLCS(); ///采用倒推方式求最长公共子序列 9 10 int main() 11 { 12 int i; 13 strcpy(a,"ABCBDAB"); 14 strcpy(b,"BDCABA"); 15 memset(num,0,sizeof(num)); 16 memset(flag,0,sizeof(flag)); 17 LCS(); 18 printf("%d\n",num[strlen(a)][strlen(b)]); 19 getLCS(); 20 return 0; 21 } 22 23 void LCS() 24 { 25 int i,j; 26 for(i=1;i<=strlen(a);i++) 27 { 28 for(j=1;j<=strlen(b);j++) 29 { 30 if(a[i-1]==b[j-1]) ///注意这里的下标是i-1与j-1 31 { 32 num[i][j]=num[i-1][j-1]+1; 33 flag[i][j]=1; ///斜向下标记 34 } 35 else if(num[i][j-1]>num[i-1][j]) 36 { 37 num[i][j]=num[i][j-1]; 38 flag[i][j]=2; ///向右标记 39 } 40 else 41 { 42 num[i][j]=num[i-1][j]; 43 flag[i][j]=3; ///向下标记 44 } 45 } 46 } 47 } 48 49 void getLCS() 50 { 51 52 char res[500]; 53 int i=strlen(a); 54 int j=strlen(b); 55 int k=0; ///用于保存结果的数组标志位 56 while(i>0 && j>0) 57 { 58 if(flag[i][j]==1) ///如果是斜向下标记 59 { 60 res[k]=a[i-1]; 61 k++; 62 i--; 63 j--; 64 } 65 else if(flag[i][j]==2) ///如果是斜向右标记 66 j--; 67 else if(flag[i][j]==3) ///如果是斜向下标记 68 i--; 69 } 70 71 for(i=k-1;i>=0;i--) 72 printf("%c",res[i]); 73 }
(2)转化为最长递增子序列问题,O( n*log(n) )
(转自:http://karsbin.blog.51cto.com/1156716/966387)
注意到num[i][j]仅在A[i]==B[j]处才增加,对于不相等的地方对最终值是没有影响的。故而枚举相等点处可以对上述动态规划算法进行优化。
举例说明:
A:abdba
B:dbaaba
则 1:先顺序扫描A串,取其在B串的所有位置:
2:a(2,3,5) b(1,4) d(0)。
3:用每个字母的反序列替换,则最终的最长严格递增子序列的长度即为解。
替换结果:532 41 0 41 532
最大长度为3.
对于一个满足最长严格递增子序列的序列,该序列必对应一个匹配的子串。
反序是为了在递增子串中,每个字母对应的序列最多只有一个被选出。
反证法可知不存在更大的公共子串,因为如果存在,则求得的最长递增子序列不是最长的,矛盾。
最长递增子序列可在O(NLogN)的时间内算出。
二,子序列要求连续
(1) 暴力枚举(O(n^4))
方法: 枚举B串所有子串,对比确定该子串是否为A串的某一子串,返回最长子串的长度。
复杂度分析: B串子串个数为O(n^2), 确定子串是否为A 串的一部分,为O(n^2),故而总的复杂度为O(n^4)
(2) KMP优化匹配过程( O(n^3) )
在算法一中用KMP优化子串与A串的匹配过程,可以将匹配过程优化为线性时间O(n),故而总的复杂度为O(n^3).
(3) 引入KMP( O(n^2) )
方法: 将B串的所有后缀串(n个),与A串做KMP匹配,返回匹配过程中最长配对长度。 时间复杂度为O(n^2)
(4) 后缀数组解法(O(n*log(n)) )
(转自:https://www.byvoid.com/blog/lcs-suffix-array)
关于后缀数组的构建方法以及Height数组的性质,本文不再具体介绍,可以参阅IOI国家集训队2004年论文《后缀数组》(许智磊)和IOI国家集训队2009年论文《后缀数组——处理字符串的有力工具》(罗穗骞)。后缀数组可以在线性时间建立起来,DC3.
回顾一下后缀数组,SA[i]表示排名第i的后缀的位置,Height[i]表示后缀SA[i]和SA[i-1]的最长公共前缀(Longest Common Prefix,LCP),简记为Height[i]=LCP(SA[i],SA[i-1])。连续的一段后缀SA[i..j]的最长公共前缀,就是H[i-1..j]的最小值,即LCP(SA[i..j])=Min(H[i-1..j])。
求N个串的最长公共子串,可以转化为求一些后缀的最长公共前缀的最大值,这些后缀应分属于N个串。具体方法如下:
设N个串分别为S1,S2,S3,...,SN,首先建立一个串S,把这N个串用不同的分隔符连接起来。S=S1[P1]S2[P2]S3...SN-1[PN-1]SN,P1,P2,...PN-1应为不同的N-1个不在字符集中的字符,作为分隔符(后面会解释为什么)。
接下来,求出字符串S的后缀数组和Height数组,可以用倍增算法,或DC3算法。
然后二分枚举答案A,假设N个串可以有长度为A的公共字串,并对A的可行性进行验证。如果验证A可行,A'(A'<A)也一定可行,尝试增大A,反之尝试缩小A。最终可以取得A的最大可行值,就是这N个串的最长公共子串的长度。可以证明,尝试次数是O(logL)的。
于是问题就集中到了,如何验证给定的长度A是否为可行解。方法是,找出在Height数组中找出连续的一段Height[i..j],使得i<=k<=j均满足Height[k]>=A,并且i-1<=k<=j中,SA[k]分属于原有N个串S1..SN。如果能找到这样的一段,那么A就是可行解,否则A不是可行解。
具体查找i..j时,可以先从前到后枚举i的位置,如果发现Height[i]>=A,则开始从i向后枚举j的位置,直到找到了Height[j+1]<A,判断[i..j]这个区间内SA是否分属于S1..SN。如果满足,则A为可行解,然后直接返回,否则令i=j+1继续向后枚举。S中每个字符被访问了O(1)次,S的长度为NL+N-1,所以验证的时间复杂度为O(NL)。
到这里,我们就可以理解为什么分隔符P1..PN-1必须是不同的N-1个不在字符集中的字符了,因为这样才能保证S的后缀的公共前缀不会跨出一个原有串的范围。
后缀数组是一种处理字符串的强大的数据结构,配合LCP函数与Height数组的性质,后缀数组更是如虎添翼。利用后缀数组,容易地求出了多个串的LCS,而且时空复杂度也相当优秀了。虽然比起后缀树的解法有所不如,但其简明的思路和容易编程的特点却在实际的应用中并不输于后缀树。
(4) 后缀数(O(n) )
将A#B$作为字符串压入后缀树,找到最深的非叶节点,且该节点的叶节点既有#也有$(无#)。由于后缀树可以在线性时间建立,而且遍历后缀树需要线性时间(该后缀树中节点数目不大于 2(|A|+|B|)),故而总的时间为线性。

