

在成功登陆之后,我们可以进行下一波操作了~
接下来,我们的目的是通过输入关键字,找到相关用户,并收集用户的一些基本信息
环境
tools
1、chrome及其developer tools
2、python3.6
3、pycharm
Python3.6中使用的库
1 import urllib.error 2 import urllib.request 3 import urllib.parse 4 import urllib 5 import re 6 import json 7 import pandas as pd 8 import time 9 import logging 10 import random 11 from lxml import etree
关键词搜索
我们首先在微博首页输入关键词,进入搜索页面
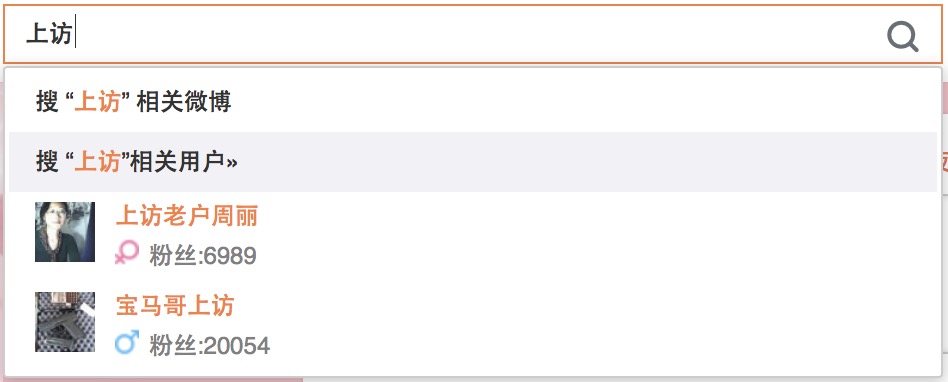
搜索后,我们发现网址为http://s.weibo.com/user/%25E4%25B8%258A%25E8%25AE%25BF&Refer=weibo_user
很显然,前面的“http://s.weibo.com/user/”网页基础地址,“%25E4%25B8%258A%25E8%25AE%25BF”看起来很像关键词的一种编码形式,最后的一段内容我们先放一边,点击进入下一页继续观察规律
进入第二页后,我们发现网址变为http://s.weibo.com/user/%25E4%25B8%258A%25E8%25AE%25BF&page=2
这时,我们需要猜想,如果将“page=”之后的数字改为1,是否会跳转回首页:
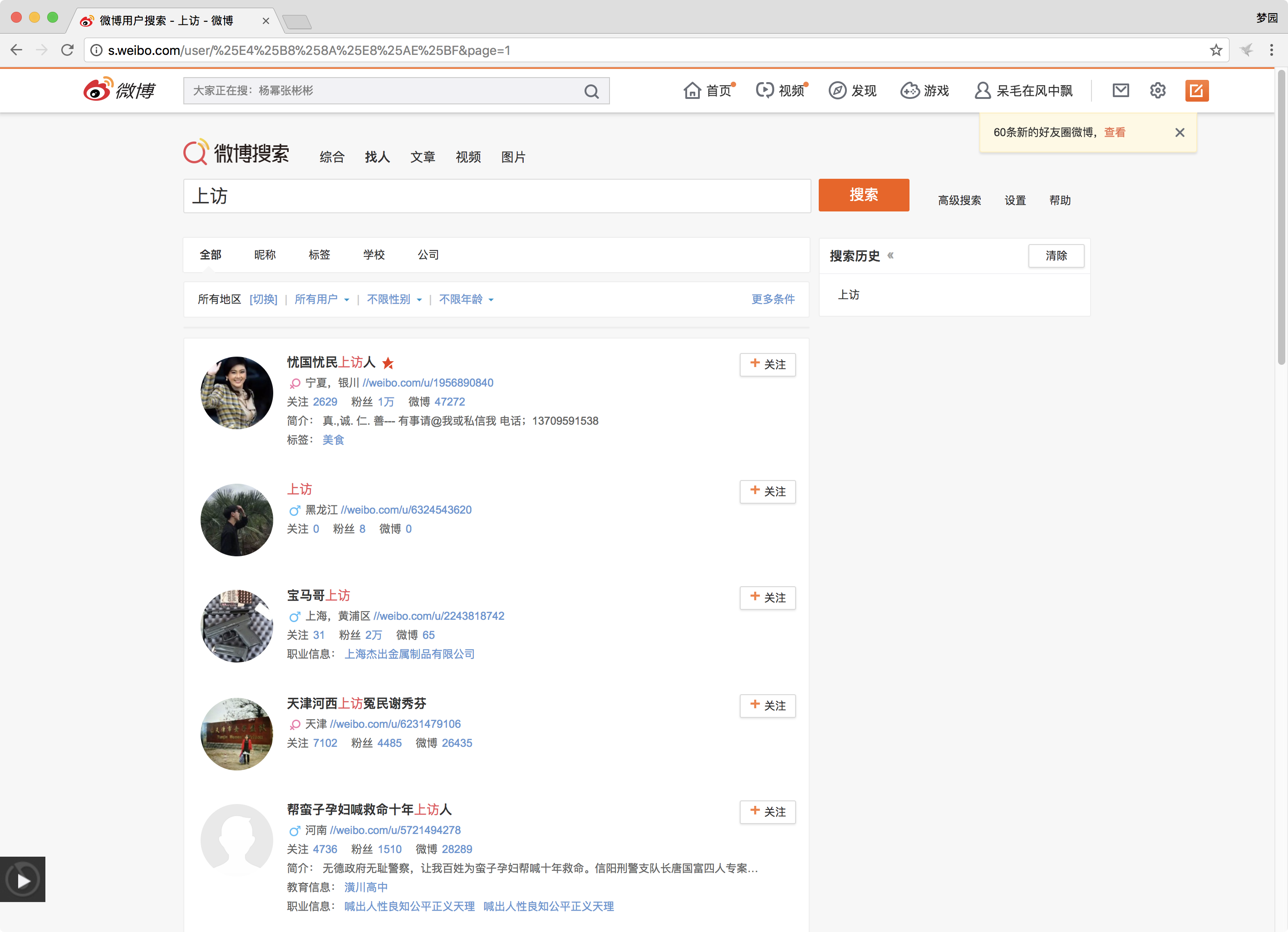
成功了,这样我们就可以将url分为三部分。
现在,我们需要对中间编码部分进行解析,发现它经过两次url编码。
因此,最后搜索页的url连接如下:
1 import urllib.request 2 3 keyword = '上访' 4 once = urllib.request.quote(keyword) 5 pagecode = urllib.request.quote(once) 6 7 i = 1 # 页数 8 url = 'http://s.weibo.com/user/' + pagecode + '&page=' + str(i)
用户基本信息提取
接下来,我要对用户的一些基本信息进行爬取。
经过观察,初步确定了搜索页面所能爬取到的用户信息字段:
- 微博ID——_id
- 微博名——name
- 地区——location
- 性别——gender
- 微博地址——weibo_addr
- 关注——follow
- 粉丝——fans
- 微博数——weibo_num
- 简介——intro
- 职业——职业信息
- 教育——教育信息
- 标签——标签
(其中,红色字段是必有的。)
我们将先对【必有字段】进行爬取,再研究如何爬取【非必有字段】。
首先我们先观察网页源码,定位到用户主体部分【可以用Chrome自带的developer tools中的element进行定位】
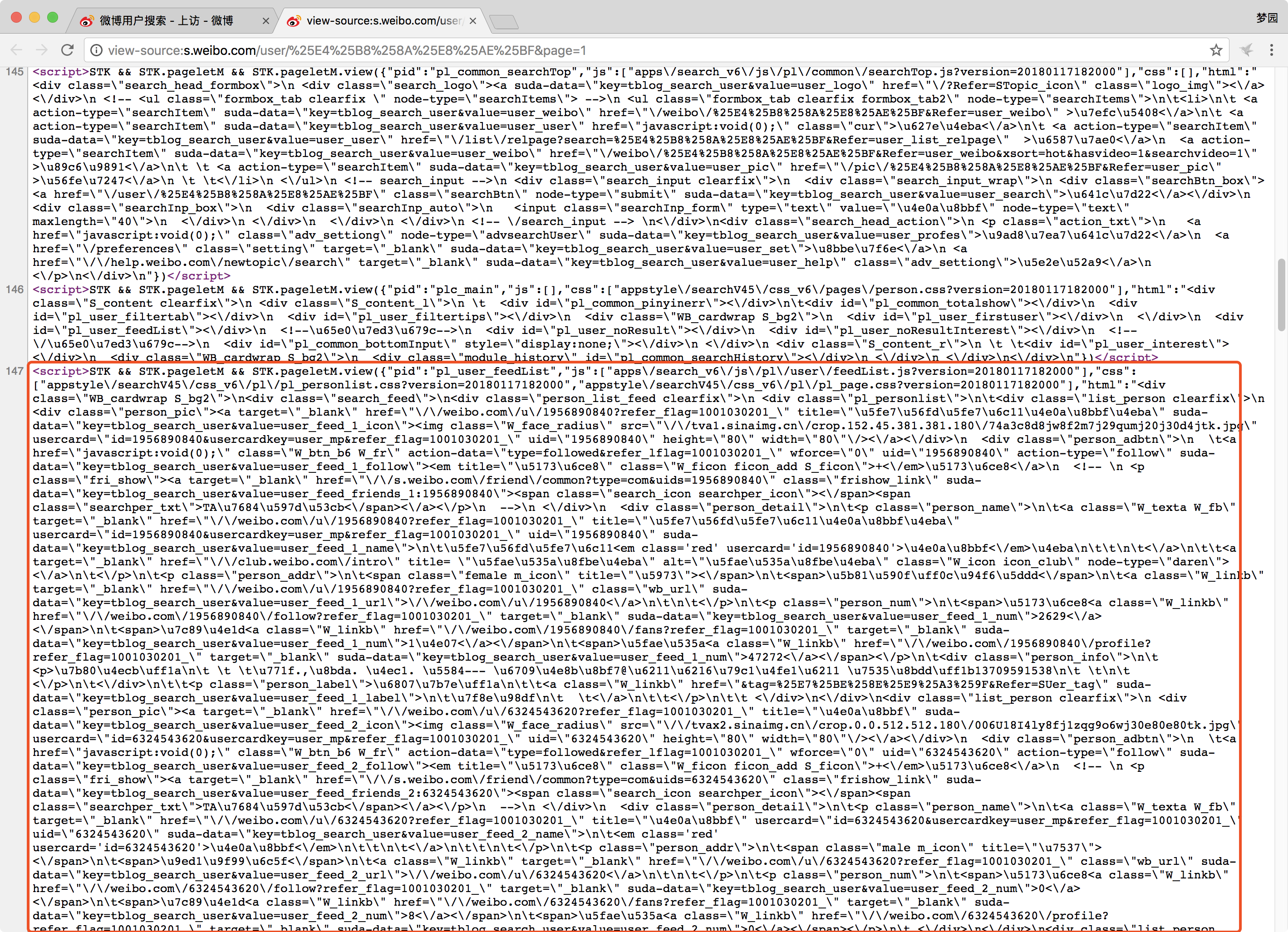
于是我们发现,开头为“<script>STK && STK.pageletM && STK.pageletM.view({"pid":"pl_user_feedList"”,我们可以通过正则表达式,寻找出该内容
此外,仔细观察还能发现()里面的内容为json格式。
万岁~~
这样对我们提取所需的html内容十分的有帮助~~
1 data = urllib.request.urlopen(url,timeout=30).read().decode('utf-8') 2 3 lines = data.splitlines() 4 for line in lines: 5 if not line.startswith('<script>STK && STK.pageletM && STK.pageletM.view({"pid":"pl_user_feedList","js":'): 6 continue 7 8 json_pattern = re.compile('\((.*)\)') 9 # 利用正则取出json 10 json_data = json_pattern.search(line).group(1) 11 # 将json包装成字典并提取出html内容 12 html = json.loads(json_data)['html']
然后开始正式的网页内容解析,先对【必有字段】进行解析。
这里,我们依旧需要借助Chrome上的developer tools
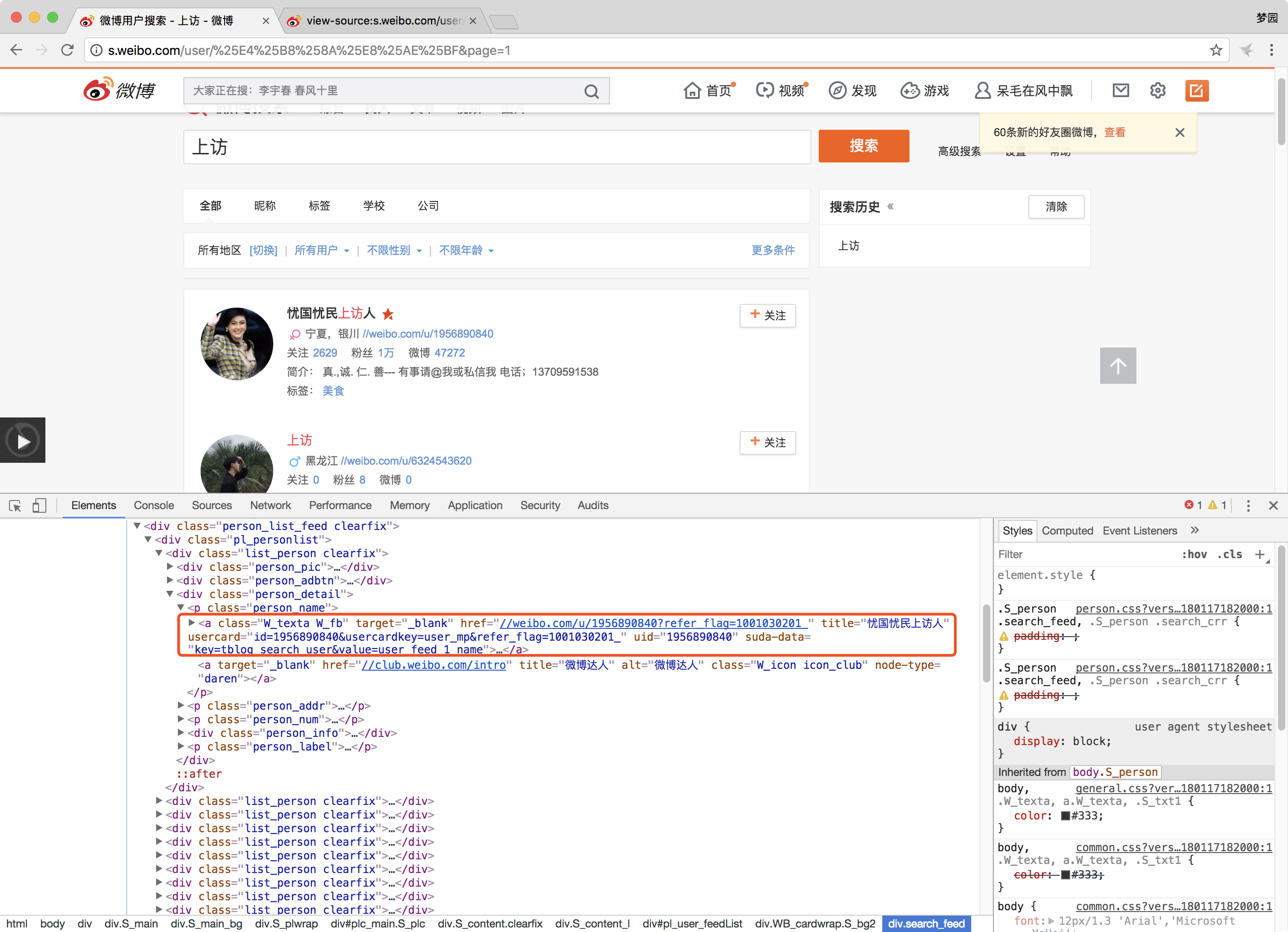
通过elements,我们定位到微博名对应的html内容,我们可以利用lxml中的etree和xpath获取title名。
同理,我们也可以得到其他必有字段,最后我们讲所有内容存储成一个dict,每个key对应的value则为一个list:
1 page = etree.HTML(html) 2 info_user['name'] = page.xpath('//a[@class="W_texta W_fb"]/@title') 3 info_user['_id'] = page.xpath('//a[@class="W_btn_b6 W_fr"]/@uid') 4 info_user['weibo_addr'] = page.xpath('//a[@class="W_texta W_fb"]/@href') 5 info_user['gender'] = page.xpath('//p[@class="person_addr"]/span[1]/@title') 6 info_user['location'] = page.xpath('//p[@class="person_addr"]/span[2]/text()') 7 info_user['follow'] = page.xpath('//p[@class="person_num"]/span[1]/a/text()') 8 info_user['fans'] = page.xpath('//p[@class="person_num"]/span[2]/a/text()') 9 info_user['weibo_num'] = page.xpath('//p[@class="person_num"]/span[3]/a/text()')
最后是对【非必有字段】的爬取
该类字段爬取的思代码逻辑是这样的
利用lxml包中的etree抓取子树(class="person_detail")
再对子树下的枝干进行遍历,判断是否存在简介(class="person_info")和标签(class="person_label"),分别进行不同的处理
值得注意的是,部分标签下的内容不止一个,因此我们必须对标签内容进行一次判断和遍历。
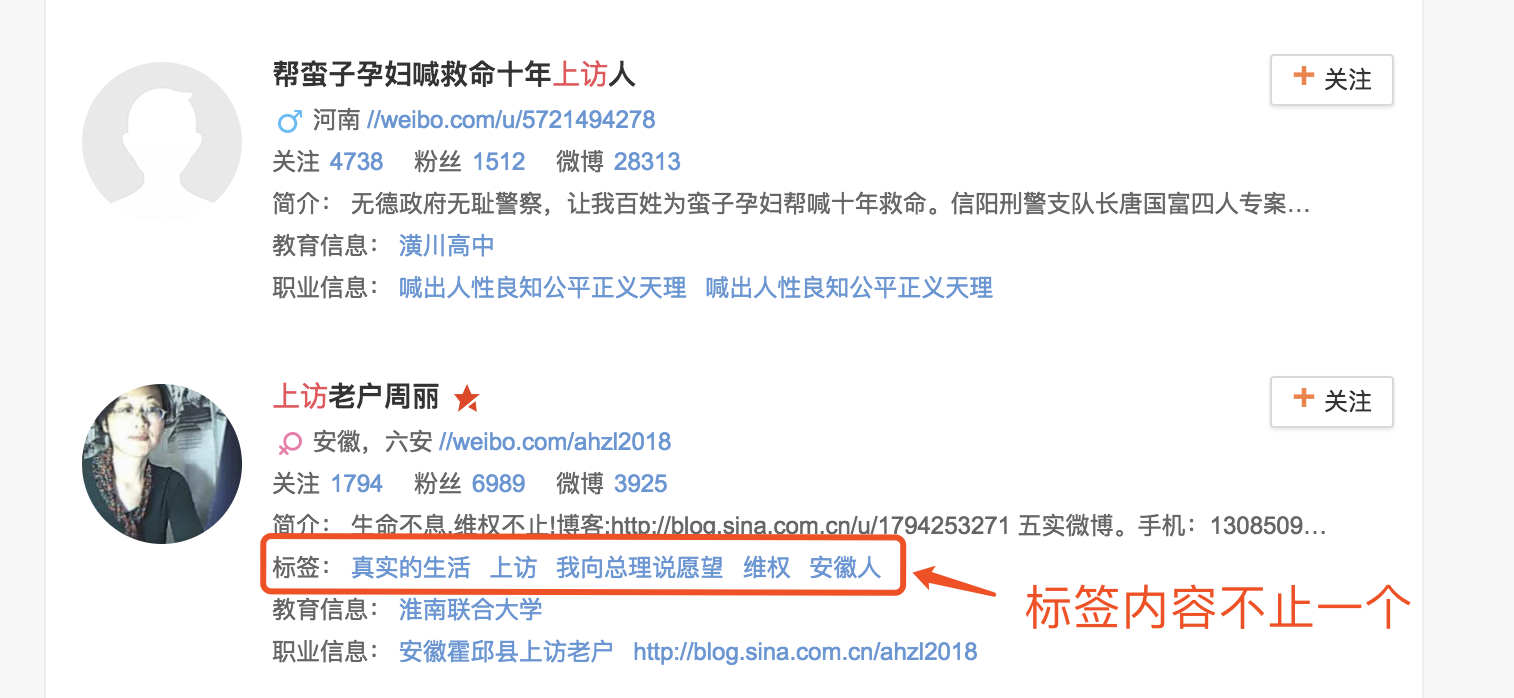
由于简介和标签分别处于两个枝干,因此可以编辑两个不同的函数进行提取:
1 # 提取简介信息 2 def info(self, p, path): 3 ''' 4 extract introduction of users 5 :param p: input an etree 6 :param path: input xpath which must be a string 7 :return: a string 8 ''' 9 if type(path) == str: 10 info = p.xpath(path) 11 if len(info) == 0: 12 sub_info = '' 13 else: 14 sub_info = info[0] 15 16 return sub_info 17 else: 18 print('please enter the path as a string') 19 20 # 提取标签信息:标签、教育信息、工作信息 21 def labels(self, p, path, key): 22 ''' 23 extract labels, such as hobbits, education, job, of users 24 :param p: input an etree 25 :param path: input xpath which must be a string 26 :param key: keywords of labels 27 :return: a string 28 ''' 29 label = p.xpath(path) 30 if len(label) == 0: 31 sub_label = '' 32 else: 33 for l in label: 34 label_name = re.compile('(.*?):').findall(l.xpath('./text()')[0]) 35 if label_name[0] == key: 36 # 读取出标签信息下的所有标签内容 37 all_label = l.xpath('./a/text()') 38 l = '' 39 for i in all_label: 40 l = re.compile('\n\t(.*?)\n\t').findall(i)[0] + ',' + l 41 sub_label = l 42 else: 43 sub_label = '' 44 45 return sub_label
构造完函数后,可以提取所有用户的信息啦~
需要注意的是,返回的内容是单个子树下的一个string,遍历当前页的所有用户的信息,则需要做成list:
1 info_user['intro'] = [] 2 info_user['标签'] = [] 3 info_user['职业信息'] = [] 4 info_user['教育信息'] = [] 5 others = page.xpath('//div[@class="person_detail"]') 6 for p in others: 7 path1 = './div/p/text()' 8 info_user['intro'].append(self.info(p, path1)) 9 path2 = './p[@class="person_label"]' 10 info_user['标签'].append(self.labels(p, path2, '标签')) 11 info_user['职业信息'].append(self.labels(p, path2, '职业信息')) 12 info_user['教育信息'].append(self.labels(p, path2, '教育信息'))
遍历所有页面
在成功实践了用户基本信息的爬取之后,需要遍历所有的网页
这里,我们可以用很傻瓜的方法,自己观察一共有几页,然后编一个for循环
然鹅!!!博主我绝对不会干这种蠢事的!!!必须要有一个更加装x的方式来遍历才行!
于是,继续依赖developer tools,找到点击下一页对应的元素,我们发现了一个神奇的东西——class="page next S_txt1_S_line1"
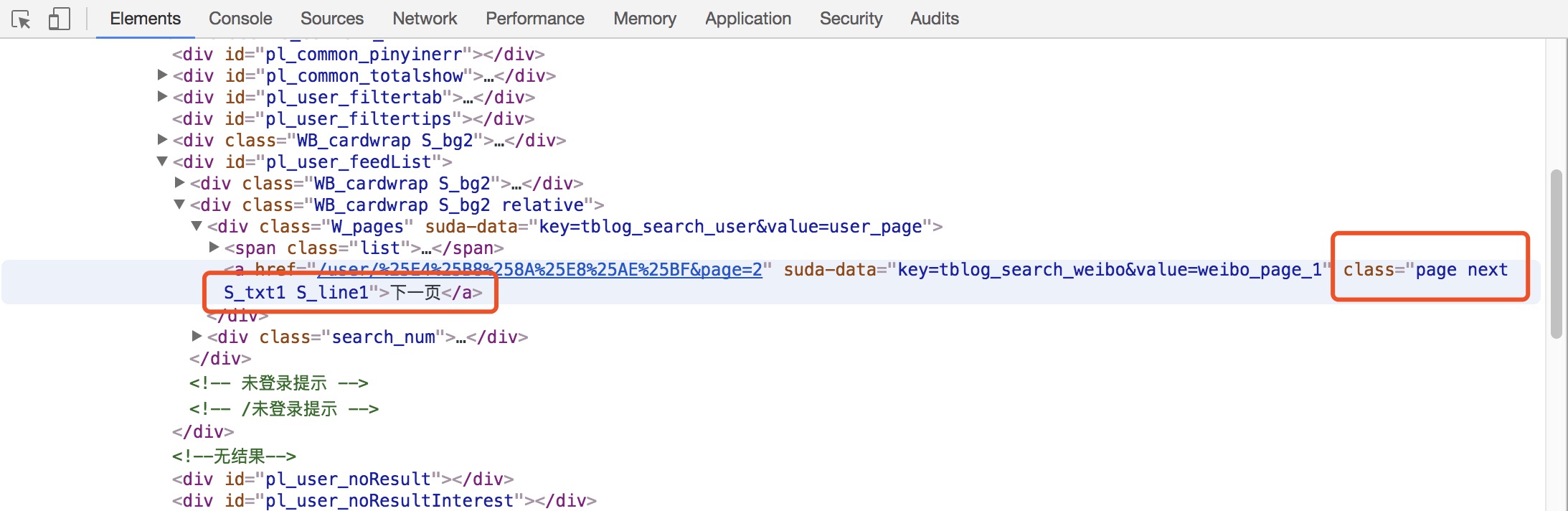
这不就是绝佳的定位是否存在下一页的神器么!!!
于是,最佳代码逻辑诞生啦~~
通过判断能否提取出该内容来决定是否进入还需进入下一页i += 1
1 i = 1 2 Flag = True 3 while Flag: 4 # 构建url 5 url = 'http://s.weibo.com/user/' + pagecode + '&page=' + str(i) 6 try: 7 # 超时设置 8 data = urllib.request.urlopen(url,timeout=30).read().decode('utf-8') 9 except Exception as e: 10 print('出现异常 -->'+str(e)) 11 12 ………… 13 14 next_page = page.xpath('//a[@class="page next S_txt1 S_line1"]/@href')[0] 15 if len(next_page) == 0 : 16 Flag = False 17 else: 18 page_num = re.compile('page=(\d*)').findall(next_page)[0] 19 i = int(page_num)
撒花~~~代码的整体逻辑就这么完善啦~~~
最后,我们需要解决的就是反爬的问题了,博主在这方面还没有深入研究过
不过主要思路还是有的:
- 每次遍历设置一个time.sleep()
- 设置好详细的头文件
- 寻找代理IP
最后完整版代码就不贴上来啦~~如果有疑问可以在下面回复多多交流~
撒花完结~~

