xpath加PHP对网站相关数据的截取
首先了解一串代码
<?php
$url = '![]() http://www.baidu.com';
http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_FILE, fopen('php://stdout', 'w'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($ch, CURLOPT_URL, $url);
$html = curl_exec($ch);
curl_close($ch);
// create document object model
$dom = new DOMDocument();
// load html into document object model
@$dom->loadHTML($html);
// create domxpath instance
$xPath = new DOMXPath($dom);
// get all elements with a particular id and then loop through and print the href attribute
$elements = $xPath->query('//*[@id="lg"]/img/@src');
foreach ($elements as $e) {
echo ($e->nodeValue);
}
$ch = curl_init();
curl_setopt($ch, CURLOPT_FILE, fopen('php://stdout', 'w'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($ch, CURLOPT_URL, $url);
$html = curl_exec($ch);
curl_close($ch);
// create document object model
$dom = new DOMDocument();
// load html into document object model
@$dom->loadHTML($html);
// create domxpath instance
$xPath = new DOMXPath($dom);
// get all elements with a particular id and then loop through and print the href attribute
$elements = $xPath->query('//*[@id="lg"]/img/@src');
foreach ($elements as $e) {
echo ($e->nodeValue);
}
?>
在PHP中是可以直接运行输出的,简单的学习一下xpath语法规则即可看懂'//*[@id="lg"]/img/@src'这串的含义,不过这并不是重要的,谷歌浏览器自带xpath,语法规则可以自动生成,另外还可以装一个XPath Helper插件,具体可以看截图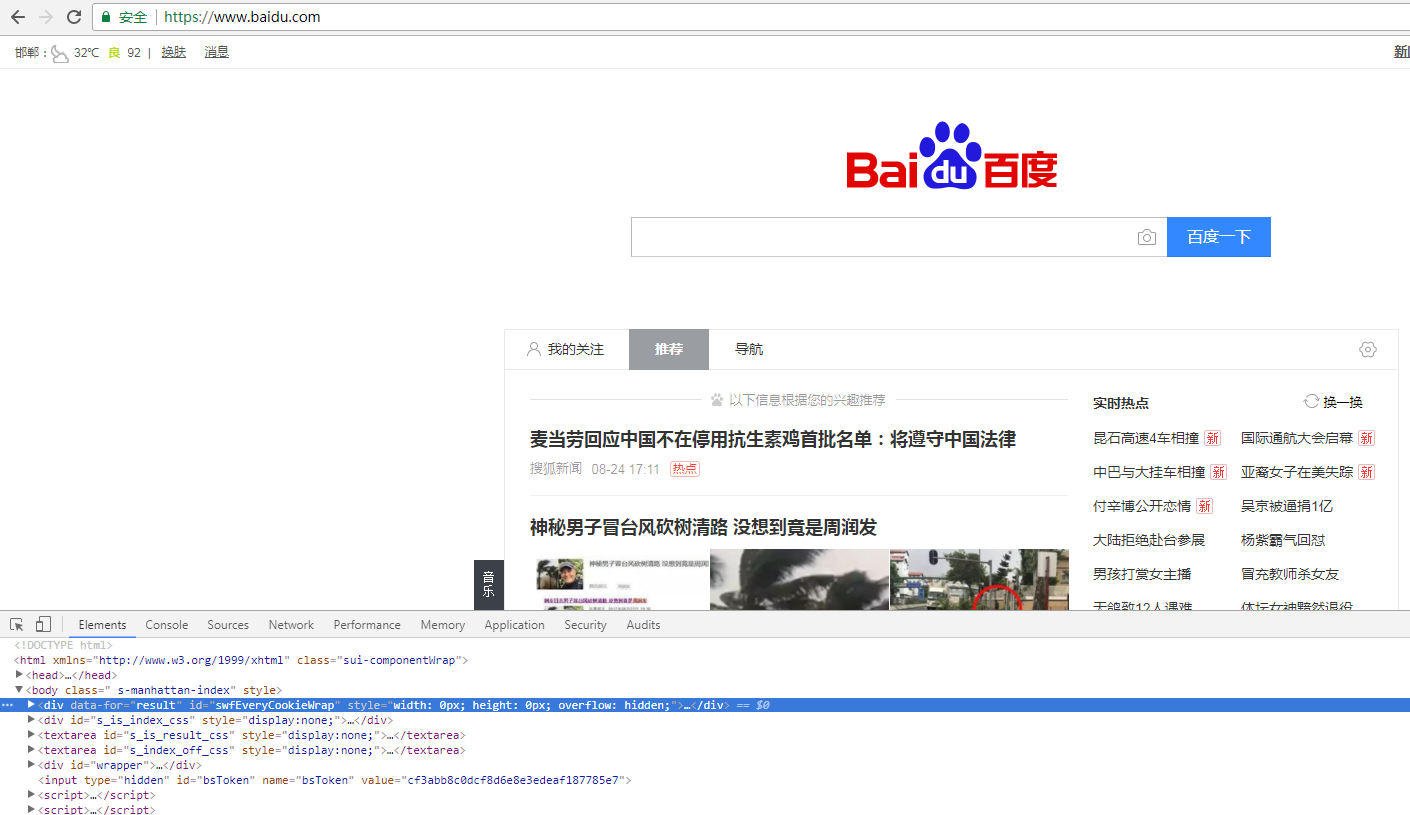
1.打开百度按F12,如图显示的这样。

2.点击左侧的箭头图标。