SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有。望各位支持!
本系列上一篇博文链接:SQL SERVER大话存储结构(1)_数据页类型及页面指令分析
1 行记录如何存储
这里引入两个概念:堆跟聚集索引表。本部分参考MSDN。
1.1 堆表
堆表,没有聚集索引的表格,可以创建一个或者多个非聚集索引。没有按照某个规则进行存储,一般来说,按照行记录入表的顺序,但是由于性能要求,可能会在不同区域移动入库数据。像一堆沙子一样,没有明确的组织顺序。
堆的 sys.partitions 中具有一行,对于堆使用的每个分区,都有 index_id = 0。默认情况下,一个堆有一个分区。 当堆有多个分区时,每个分区有一个堆结构,其中包含该特定分区的数据。例如,如果一个堆有四个分区,则有四个堆结构,每个分区有一个堆结构。
根据堆中的数据类型,每个堆结构将有一个或多个分配单元来存储和管理特定分区的数据。每个堆中每个分区至少有一个 IN_ROW_DATA 分配单元。如果堆包含大型对象 (LOB) 列,则该堆的每个分区还将有一个 LOB_DATA 分配单元。如果堆包含超过 8,060 字节的行大小限制的变量长度列,则它的每个分区中还会有一个 ROW_OVERFLOW_DATA 分配单元。
sys.system_internals_allocation_units系统视图中的列 first_iam_page 指向 IAM 页链中的第一个 IAM 页,该 IAM 页链可管理分配给特定分区中的堆的空间。 SQL Server 使用 IAM 页在堆之间移动。堆内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是记录在 IAM 页内的信息。
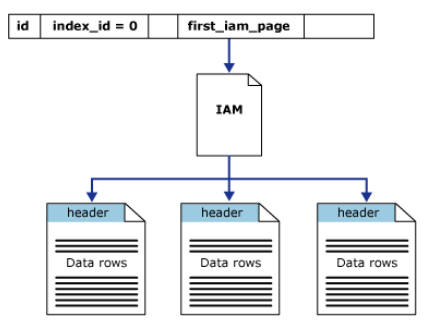
拥有聚集索引的表格,称为聚集索引表,每个表格按照其聚集索引的排序规则进行存储,但是这里注意一点,在一个页面中,并非 行记录 按照 其聚集索引排序规则,而是 行偏移量 按照其排序规则存储。
1.2 聚集索引表格
在 SQL Server 中,索引是按 B 树结构进行组织的。 索引 B 树中的每一页称为一个索引节点。 B 树的顶端节点称为根节点。 索引中的底层节点称为叶节点。 根节点与叶节点之间的任何索引级别统称为中间级。 在聚集索引中,叶节点包含基础表的数据页。 根节点和中间级节点包含存有索引行的索引页。 每个索引行包含一个键值和一个指针,该指针指向 B 树上的某一中间级页或叶级索引中的某个数据行。 每级索引中的页均被链接在双向链接列表中。
聚集索引在 sys.partitions 中有一行,其中,索引使用的每个分区的 index_id = 1。 默认情况下,聚集索引有单个分区。 当聚集索引有多个分区时,每个分区都有一个包含该特定分区相关数据的 B 树结构。 例如,如果聚集索引有四个分区,就有四个 B 树结构,每个分区中有一个 B 树结构。
根据聚集索引中的数据类型,每个聚集索引结构将有一个或多个分配单元,将在这些单元中存储和管理特定分区的相关数据。 每个聚集索引的每个分区中至少有一个 IN_ROW_DATA 分配单元。 如果聚集索引包含大型对象 (LOB) 列,则它的每个分区中还会有一个 LOB_DATA 分配单元。 如果聚集索引包含的变量长度列超过 8,060 字节的行大小限制,则它的每个分区中还会有一个 ROW_OVERFLOW_DATA 分配单元。
数据链内的页和行将按聚集索引键值进行排序。 所有插入操作都在所插入行中的键值与现有行中的排序顺序相匹配时执行。
下图显式了聚集索引单个分区中的结构。
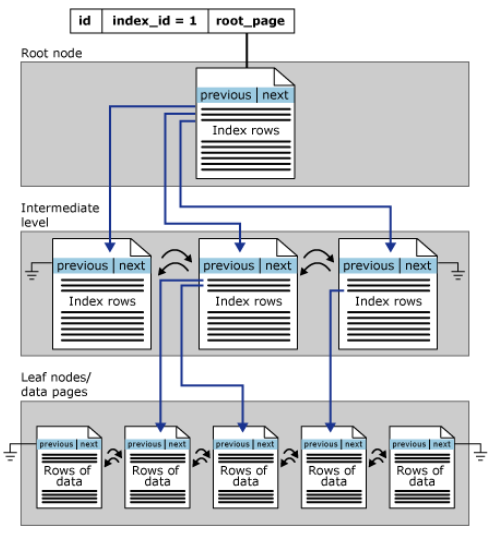
由此,可以看出,堆表不存在特定的存储顺序,一般按照INSERT的顺序存储,但是有时因为性能需求,也会四处存放数据;而聚集索引表的数据行按照聚集键的排序情况存储,叶子节点即为行记录。
2 非聚集索引结构
无论是堆表还是聚集索引表格,都可以创建非聚集索引。非聚集索引页也是B-TREE结构,但是,有几点不同:非聚集索引不影响基础表的存储顺序,其叶子节点是有索引页组成而非数据页组成。
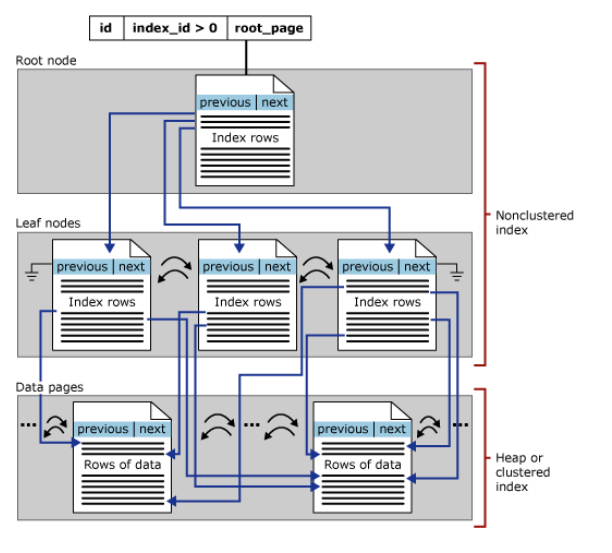
当需要通过非聚集索引寻找行记录时,先是在非聚集索引所在的B-TREE树查找,找到相应的叶子节点后,在根据该键值上的相应 行定位器 去查找其所指向的 行记录位置。
那么,行定位器是怎么样的呢?
这个还需要去分析 非聚集索引的键值内容,才可以清晰了解,详见下文的分析案例。
3 非聚集索引键值内容
创建3个表格:堆表、聚集索引非唯一表及聚集索引唯一表,并且创建非聚集索引,同时INSERT 部分数据。
--创建堆表
create table tb_heap(id int ,name varchar(100),age int)
--创建聚集索引(非唯一)表
create table tb_clu_no_unique(id int identity(1,1) ,name varchar(100),age int)
create CLUSTERED index ix_clu_id on tb_clu_no_unique(id)
--创建聚集索引且键值唯一表
create table tb_pk(id int primary key identity(1,1) ,name varchar(100),age int)
--创建非聚集索引
create index ix_tb_pk_name on tb_pk(name)
create index ix_tb_heap_name on tb_heap(name)
create index ix_tb_clu_no_unique_name on tb_clu_no_unique(name)
--造数据
insert into tb_pk(name,age) select name,cast(rand()*100 as int) from master.dbo.spt_values where name is not null
insert into tb_clu_no_unique(name,age) select name,age from tb_pk
insert into tb_heap(id,name,age) select id,name,age from tb_pk
3.1 堆表上的非聚集索引
#会话窗口查看ind,需要打开 3604跟踪
dbcc traceon(3604)
dbcc ind('dbpage','tb_heap',2)

可以得出这些结论:
- pageid=238是IAM页,判断依据是:IAMFID=NULL;
- tb_heap上的非聚集索引ix_tb_heap_name的B tree结构有2层,判断依据是:IndexLevel最大值为1;
- B-tree树中,根页为 pageid=239,叶子节点的最左节点叶是 235
依据IndexLevel、NextPagePid及PrevPagePid,可以画出 ix_tb_heap_name 的数据结构如下(画图工具崩了,用自带画图小工具话的,这图丑出天际):
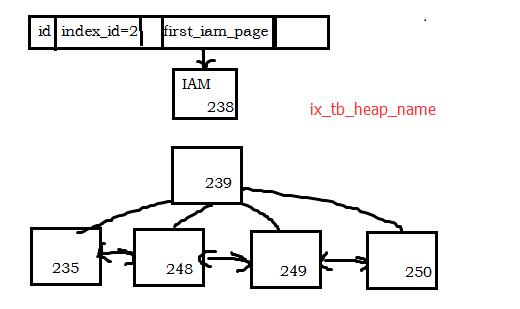
选取pageid=235,来分析非聚集索引页上的结构。
dbcc traceon(3604)
dbcc page('dbpage',1,235,3)
查看 ` 消息` ,可以看到,这个是索引页,目前上面存储260行索引键值,该页空闲空间12个字节,空闲空间从第7660字节开始。

查看 `结果` ,如下:
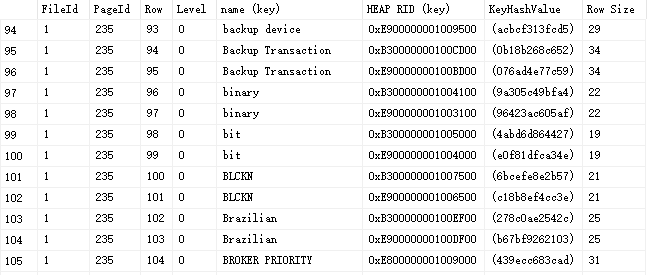
可以看到在这个页面上,每一行的行记录情况,可以看到 非聚集索引的键值有2部分:name 跟 HEAD RID,name因为是非聚集索引的列,所以理应存储,RID是什么呢?
RID除了可以从dbcc page中查询,也可以通过伪列查询:%%physloc%%。
select *,%%physloc%% as RID from tb_heap
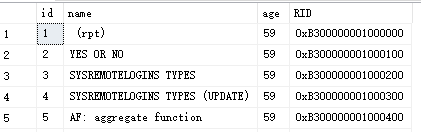
RID实际上是用来 唯一标识 堆表中的每一行数据,占8个字节,按以下格式标识行:{ file id }:{ page id }:{ slot id},文件号:数据页号:槽位,从存储的角度唯一表示了一行数据。
但是从dbcc的结果看,这是一个16进制的数值,该如何转化呢?
转换规则:分为8个字节->前4bytes为page id->中间2bytes为file id->最后2bytes为slot id->反序排列->取10进制
用 中的RID来实验下如何反解析。
中的RID来实验下如何反解析。
中的RID来实验下如何反解析。--1 分为8个字节
E9 00 00 00 01 00 95 00
--2 前4bytes为page id
E9 00 00 00
--3 中间2bytes为file id
01 00
--4 最后2bytes为slot id
95 00
--5 反序排列并取10进制
pageid,反序后为 00 00 00 E9,十进制为16*14+9=233
fileid,反序后为 00 01,十进制为 1
slotid,反序后为 00 95,十进制为 149
则可以推算出,name='backup device'中,有一行行数据存储在 第一个文件中的第233页面的149槽位
dbcc page('dbpage',1,233,3)
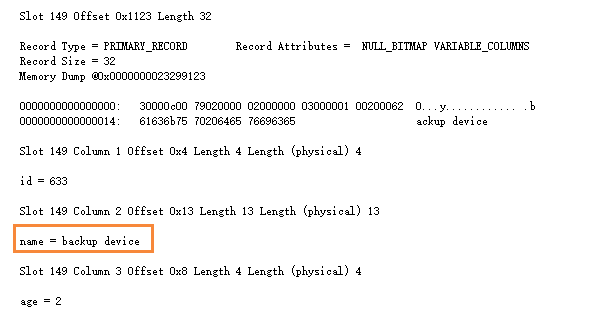
由此,可以推出:在堆表中,非聚集索引的键值包含两部分:索引列 以及 RID,RID用于查找索引键值对应的行记录。
3.2 聚集索引表(唯一)的非聚集索引
#会话窗口查看ind,需要打开 3604跟踪
dbcc traceon(3604)
dbcc ind('dbpage','tb_pk',2)

根据2.1的推论,一样可以得出这些结论:
- pageid=121是IAM页,判断依据是:IAMFID=NULL;
- tb_pk上的非聚集索引ix_tb_pk_name的B tree结构有2层,判断依据是:IndexLevel最大值为1;
- B-tree树中,根页为 pageid=126,叶子节点的最左节点叶是 120。
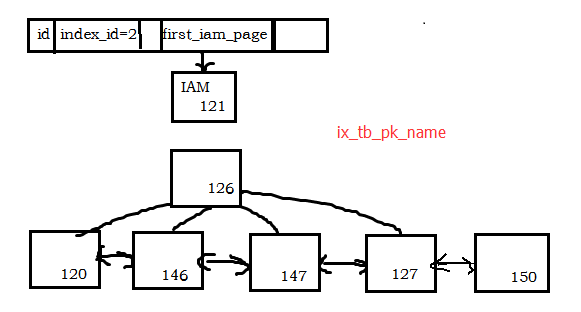
依据IndexLevel、NextPagePid及PrevPagePid,可以画出 ix_tb_pk_name 的数据结构如下:
选取pageid=120,来分析非聚集索引页上的结构。
dbcc traceon(3604)
dbcc page('dbpage',1,120,3)
查看 ` 消息` ,可以看到,这个是索引页,目前上面存储296行索引键值,该页空闲空间86个字节,空闲空间从第7514字节开始。
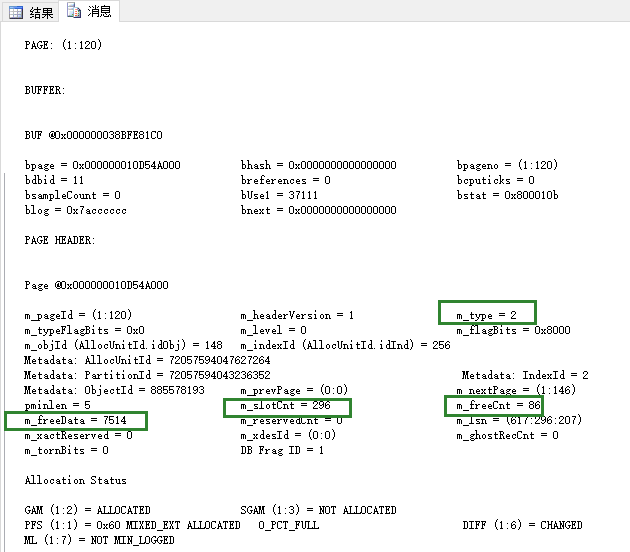
查看 ` 结果` ,可发现,在 聚集索引且唯一的表格里边,非聚集索引有2部分:键值列+主键列。这个相对比较好理解,因为在建立了聚集唯一索引的表格里边,其聚集索引键值可以唯一标识每一行的行记录,所以,在非聚集索引上,只需要包含这两部分。

3.3 聚集索引表(非唯一)的非聚集索引
#会话窗口查看ind,需要打开 3604跟踪
dbcc traceon(3604)
dbcc ind('dbpage','tb_clu_no_unique',2)

根据2.1的推论,一样可以得出这些结论:
- pageid=172是IAM页,判断依据是:IAMFID=NULL;
- tb_pk上的非聚集索引tb_clu_no_unique的B tree结构有2层,判断依据是:IndexLevel最大值为1;
- B-tree树中,根页为 pageid=174,叶子节点的最左节点叶是 171
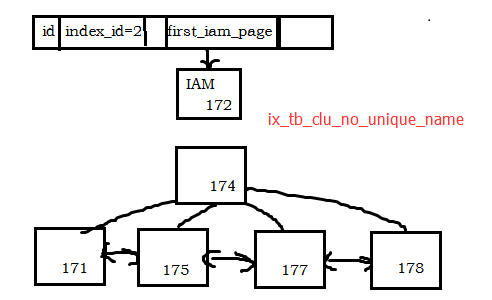
选取pageid=171,来分析非聚集索引页上的结构。
dbcc traceon(3604)
dbcc page('dbpage',1,171,3)
查看 ` 消息` ,可以看到,这个是索引页,目前上面存储298行索引键值,该页空闲空间4个字节,空闲空间从第7592字节开始。
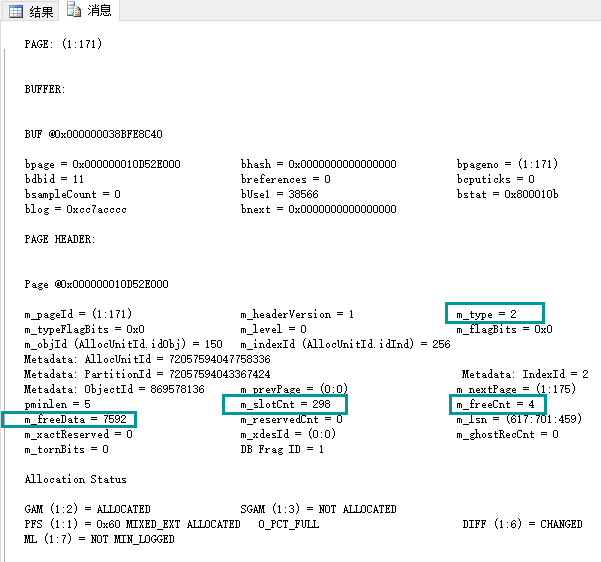
查看 ` 结果` ,注意列后面括号'(key)',这个表明为键值对组成部分,这里,发现有之前没有看到的键值列 UNIQUIFIER列。
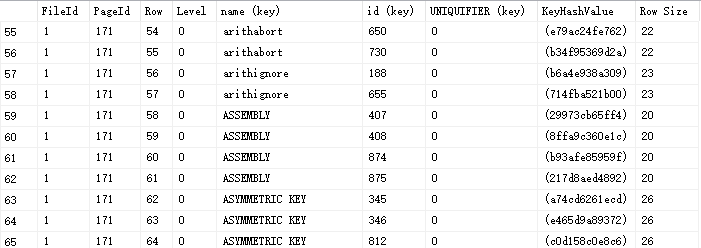
那么,UNIQUIFIER列,这一列是用来做什么的呢?
这里,为了更好的理解UNIQUIFIER列,需要新建一个新表,INSERT少量重复聚集索引键值的行记录。
create table tb_clu_no_unique_2(id int ,name varchar(100),age int)
create CLUSTERED index ix_clu_i_2 on tb_clu_no_unique_2(id)
CREATE INDEX IX_tb_clu_no_unique_2_NAME ON tb_clu_no_unique_2(NAME)
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 1,'A',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 1,'B',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'C',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'D',3;
INSERT INTO tb_clu_no_unique_2(ID,NAME,AGE) SELECT 2,'E',3;
DBCC TRACEON(3604)
DBCC IND('dbpage','tb_clu_no_unique_2',2)
DBCC PAGE('dbpage',1,306,3)
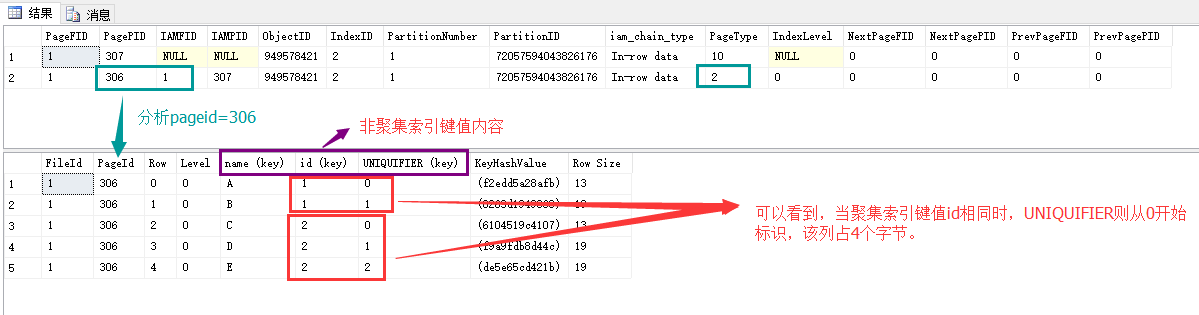
可发现,在 聚集索引且非唯一的表格里边,非聚集索引有3部分:键值列+主键列+UNIQUIFIER列。建立了聚集非唯一索引,表的存储顺序按照聚集索引顺序,但是仅靠聚集索引无法唯一标识每一行的行记录,所以,需要添加 UNIQUIFIER列来唯一标识。
总结:
- 堆表 的 非聚集索引 键值内容:索引列+RID
- 聚集且唯一索引表 的非聚集索引 键值内容:索引列+主键列
- 聚集且非唯一索引表 的非聚集索引 键值内容:索引列+主键列+UNIQUIFIER列
4 非聚集索引如何查找页
根据第二部分,可以很清楚每类型的非聚集索引的组成部分。
在堆表中,非聚集索引根据其键值内的RID列,直接进行物理查找,从fileid找到pageid,在找到slotid来定位到行记录,这个也就是所谓的书签查找,根据RID查找。
在聚集且唯一的索引表中,非聚集索引根据其键值内部的 聚集索引列,找到聚集索引的B-TREE,根据 B-TREE 树找到聚集索引的键值,键值下的叶子节点则为行记录。
在聚集其非唯一索引表中,非聚集索引根据其键值内部的 聚集索引列,找到聚集索引的B-TREE,根据 B-TREE 树找到聚集索引的键值,这里会有些不一样了,根据找到的键值,键值下的叶子节点可能会有多行记录,这个时候,就需要uniquifier来识别行记录。
参考文档:
《SQL Server性能调优实战》
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有。望各位支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号