
爬虫实战【2】Python博客园-获取某个博主所有文章的URL列表
Python博客园-获取某个博主所有文章的URL列表
首先,我们来分析一下,在博主的首页里,每个文章的标题在网页源码中是什么样子的。
【插入图片,文章标题1】
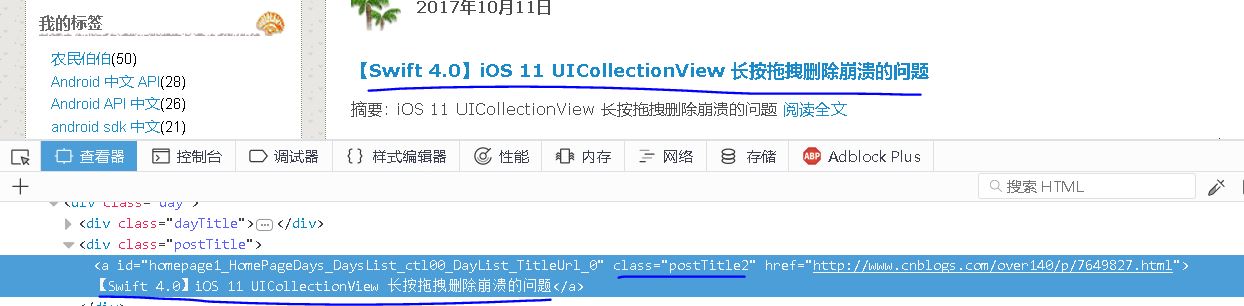
【插入图片,文章标题2】

通过这两个图片我们可以看出,博文标题所在的标签为,并且具有class属性为"postTitle2",其href属性就指向这篇博文的地址。
如下面代码所示:
<a id="homepage1_HomePageDays_DaysList_ctl01_DayList_TitleUrl_0" class="postTitle2"
href="http://www.cnblogs.com/over140/p/5462580.html">【Swift 2.2】iOS开发笔记(三)</a>
那么,我们的思路就可以是这样的:
找到所有展示博文标题的a标签,获取a标签的href属性,那么就可以得到所有文章的url列表。
但是目前存在一个问题,所有的博文标题没有在同一个页面中展示出来。
【插入图片,18页】

可以看出,农民伯伯的文章一共有18页,每一页中存在一些文章标题和摘要,那么我们就要遍历这18页,来获取所有的博文标题。
如何得到这18页的url呢?
【插入图片,每页url】

通过分析每一页的url,我们确定只有page=后面的页码是改变的,从1-18,得到这18个url的话,就能得到所有文章的标题了。
http://www.cnblogs.com/over140/default.html?page=2
实测代码如下,还是使用正则表达式,将所有的博文url都匹配了出来。
相比上篇文章,做了一些改进,获取html源码的代码,我定义成了一个方法,这样调用起来方便多了。
关于正则表达式如何匹配处URL的内容,请查看我之前的爬虫入门文章,关于正则进行了简单的讲解,应该够我们应对一般情况了。
import urllib.request
import re
#该作者的博文一共有多少页
pageNo=18
#后面需要添加页码
url='http://www.cnblogs.com/over140/default.html?page='
def get_html(url):
'''
返回对应url的网页源码,经过解码的内容
:param url:
:return:
'''
req = urllib.request.Request(url)
resp = urllib.request.urlopen(req)
html_page = resp.read().decode('utf-8')
return html_page
def get_Urls(url,pageNo):
'''
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
'''
total_urls=[]
for i in range(1,pageNo+1):
url_1=url+str(i)
html=get_html(url_1)
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
urls=re.findall(title_pattern,html)
for url_ in urls:
total_urls.append(url_)
#print(total_urls.__len__())
return total_urls
还是对上面的get_Urls方法做一些讲解吧。
total_urls是我们定义的存储所有url的列表,这个对象作为结果返回;
#这句话,是生成这18页中,每一页的url地址
url_1=url+str(i)
#如前所述,获取指定url下的网页源码,用于后面的解析
html=get_html(url_1)
#首先创建正则表达式,注意中间的括号,这个分组里面的内容才是我们想要的
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
urls=re.findall(title_pattern,html)
我觉得差不多了。既然我们都已经获取到所有文章的url列表了,而不一步到位,将所有的文章都保存下来呢。
首先展示代码,talk is cheap, show you the code。
import urllib.request
import re
from bs4 import BeautifulSoup
#该作者的博文一共有多少页
pageNo=18
#这是要访问的某一篇文章的地址
url_single='http://www.cnblogs.com/over140/p/4440137.html'
#后面需要添加页码
url='http://www.cnblogs.com/over140/default.html?page='
#博主大大的名字
author='over140'
def get_html(url):
'''
返回对应url的网页源码,经过解码的内容
:param url:
:return:
'''
req = urllib.request.Request(url)
resp = urllib.request.urlopen(req)
html_page = resp.read().decode('utf-8')
return html_page
def get_title(url):
'''
获取对应url下文章的标题
:param url:
:return:
'''
html_page = get_html(url)
title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)'
title_match = re.search(title_pattern, html_page)
title = title_match.group(2)
return title
def get_Body(url):
'''
获取对应url的文章的正文内容
:param url:
:return:
'''
html_page = get_html(url)
soup = BeautifulSoup(html_page, 'html.parser')
div = soup.find(id="cnblogs_post_body")
return div.get_text()
def save_file(url):
'''
根据url,将文章保存到本地
:param url:
:return:
'''
title=get_title(url)
body=get_Body(url)
filename=author+'-'+title+'.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write(body)
def get_Urls(url,pageNo):
'''
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
'''
total_urls=[]
for i in range(1,pageNo+1):
url_1=url+str(i)
html=get_html(url_1)
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
urls=re.findall(title_pattern,html)
for url_ in urls:
total_urls.append(url_)
print(total_urls)
return total_urls
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
save_file(url_)
if __name__=='__main__':
save_files(url,pageNo)
大家有没有觉得上面的代码,比昨天的看起来要好的多了,直观好懂。
因为我将很多零碎的语句都转换成了方法,通过调用来重复使用代码,省了很多力气。
接下来,我尝试运行这段代码,但是很快就报错了。
【插入图片,报错信息1,文件名问题】
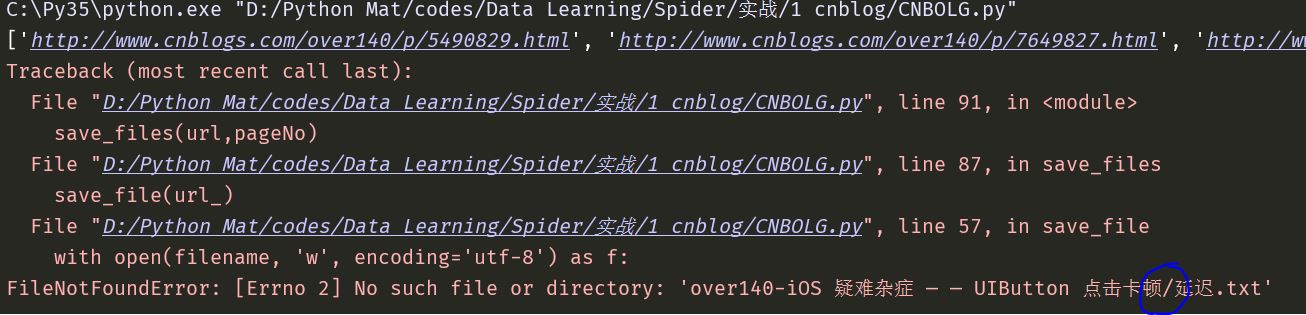
原因是生成的filename中,存在/这种天理不容的字符。
想办法解决呗,这时肯定要对filename进行调整了。
if '/' in filename:
filename=filename.replace('/','+')
if '\\' in filename:
filename=filename.replace('\\','+')
这种错误尽量解决就可以啦,但是很多情况下还会有个别错误超出我们的预期,那么更直接的办法是在save_files里面做文章,
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
try:
save_file(url_)
except:
pass
如果保存单个文件出错,那么就随他去吧,pass掉就好了。
实测上述代码可以完整运行了。
但是我们得到的内容只有文本,这种方法适合去爬一些小说啊,评论之类的内容。
如果想得到博文中的图片、代码、音频视频等内容,还需要换一种方法。
不要急,我们慢慢就会讲到的。


