

java 集合系列目录:
Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例
Java 集合系列 04 LinkedList详细介绍(源码解析)和使用示例
Java 集合系列 05 Vector详细介绍(源码解析)和使用示例
Java 集合系列 06 Stack详细介绍(源码解析)和使用示例
Java 集合系列 07 List总结(LinkedList, ArrayList等使用场景和性能分析)
Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
Java 集合系列 11 hashmap 和 hashtable 的区别
概要
5.1 TreeMap的Entry相关函数
5.2 TreeMap的key相关函数
5.3 TreeMap的values()函数
5.4 TreeMap的entrySet()函数
5.5 TreeMap实现的Cloneable接口
5.6 TreeMap实现的Serializable接口
5.7 TreeMap实现的NavigableMap接口
第1部分 红黑树简介
TreeMap的实现是红黑树算法的实现,所以要了解TreeMap就必须对红黑树有一定的了解,其实这篇博文的名字叫做:根据红黑树的算法来分析TreeMap的实现,但是为了与Java提高篇系列博文保持一致还是叫做TreeMap比较好。通过这篇博文你可以获得如下知识点:
1、红黑树的基本概念。
2、红黑树增加节点、删除节点的实现过程。
3、红黑树左旋转、右旋转的复杂过程。
4、Java 中TreeMap是如何通过put、deleteEntry两个来实现红黑树增加、删除节点的。
下面先简单普及红黑树知识。
红黑树又称红-黑二叉树,它首先是一颗二叉树,它具体二叉树所有的特性。同时红黑树更是一颗自平衡的排序二叉树。
我们知道一颗基本的二叉树他们都需要满足一个基本性质--即树中的任何节点的值大于它的左子节点,且小于它的右子节点。按照这个基本性质使得树的检索效率大大提高。我们知道在生成二叉树的过程是非常容易失衡的,最坏的情况就是一边倒(只有右/左子树),这样势必会导致二叉树的检索效率大大降低(O(n)),所以为了维持二叉树的平衡,大牛们提出了各种实现的算法,如:AVL,SBT,伸展树,TREAP ,红黑树等等。
平衡二叉树必须具备如下特性:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。

红黑树顾名思义就是节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持着二叉树的平衡。对于一棵有效的红黑树二叉树而言我们必须增加如下规则:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这棵树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。所以红黑树它是复杂而高效的,其检索效率O(log n)。下图为一颗典型的红黑二叉树。

对于红黑二叉树而言它主要包括三大基本操作:左旋、右旋、着色。


左旋 右旋
(图片来自:http://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html)
注:由于本文主要是讲解Java中TreeMap,所以并没有对红黑树进行非常深入的了解和研究,如果诸位想对其进行更加深入的研究提供几篇较好的博文:
1、红黑树系列集锦
3、红黑树
第2部分 TreeMap数据结构
TreeMap的定义如下:
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable
TreeMap与Map关系如下图:

从图中可以看出:
(01) TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
(02) TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、 parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
TreeMap继承AbstractMap,实现NavigableMap、Cloneable、Serializable三个接口。其中AbstractMap表明TreeMap为一个Map即支持key-value的集合, NavigableMap(更多)则意味着它支持一系列的导航方法,具备针对给定搜索目标返回最接近匹配项的导航方法 。
TreeMap中同时也包含了如下几个重要的属性:
//比较器,因为TreeMap是有序的,通过comparator接口我们可以对TreeMap的内部排序进行精密的控制 private final Comparator<? super K> comparator; //TreeMap红-黑节点,为TreeMap的内部类 private transient Entry<K,V> root = null; //容器大小 private transient int size = 0; //TreeMap修改次数 private transient int modCount = 0; //红黑树的节点颜色--红色 private static final boolean RED = false; //红黑树的节点颜色--黑色 private static final boolean BLACK = true;
对于叶子节点Entry是TreeMap的内部类,它有几个重要的属性:
//键 K key; //值 V value; //左孩子 Entry<K,V> left = null; //右孩子 Entry<K,V> right = null; //父亲 Entry<K,V> parent; //颜色 boolean color = BLACK;
在下面两节我将重点讲解treeMap的put()、delete()方法。通过这两个方法我们会了解红黑树增加、删除节点的核心算法。

第3部分 TreeMap put()方法
在了解TreeMap的put()方法之前,我们先了解红黑树增加节点的算法。
红黑树在新增节点过程中比较复杂,复杂归复杂它同样必须要依据上面提到的五点规范,同时由于规则1、2、3基本都会满足,下面我们主要讨论规则4、5。假设我们这里有一棵最简单的树,我们规定新增的节点为N、它的父节点为P、P的兄弟节点为U、P的父节点为G。
对于新节点的插入有如下三个关键地方:
1、插入新节点总是红色节点 。
2、如果插入节点的父节点是黑色, 能维持性质 。
3、如果插入节点的父节点是红色, 破坏了性质. 故插入算法就是通过重新着色或旋转, 来维持性质 。
为了保证下面的阐述更加清晰和根据便于参考,我这里将红黑树的五点规定再贴一遍:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
一、被插入的节点是根节点。
若新插入的节点N没有父节点,则直接当做根据节点插入即可,同时将颜色设置为黑色。(如图一(1))
二、被插入的节点的父节点是黑色。
这种情况新节点N同样是直接插入,同时颜色为红色,由于根据规则四它会存在两个黑色的叶子节点,值为null。同时由于新增节点N为红色,所以通过它的子节点的路径依然会保存着相同的黑色节点数,同样满足规则5。(如图一(2))

三、被插入的节点的父节点是红色。
穷举下一下几类,就可以画出下面的情况:
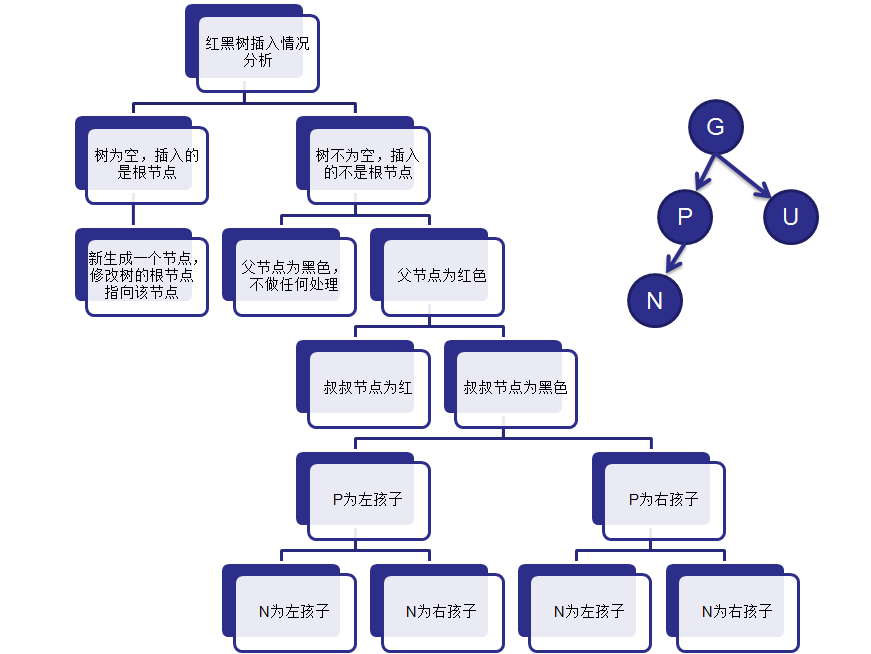
对于上述五种情况,列表给出每种的解决方法:
| 叔叔为红 | x父=黑; | |
| x叔=黑; | ||
| x祖=红; | ||
| x祖为新节点; | ||
| 叔叔为黑 | P为左,X为左 | 设x父为黑; |
| 设x祖为红; | ||
| 以x祖右旋; | ||
| P为左,X为右 | x=x的父; | |
| 以x左旋; | ||
| 设x父为黑; | ||
| 设x祖为红; | ||
| 以x祖右旋; | ||
| P为右,X为右 | x的父=黑; | |
| X的祖= 红; | ||
| 左旋(X的祖); | ||
| P为右,X为左 | x=x的父; | |
| 右旋(X); | ||
| x的父=黑; | ||
| X的祖= 红; | ||
| 左旋(X的祖); | ||
上面展示了红黑树新增节点的五种情况,这五种情况涵盖了所有的新增可能,不管这棵红黑树多么复杂,都可以根据这五种情况来进行生成。下面就来分析Java中的TreeMap是如何来实现红黑树的。
下面图表示:

在TreeMap的put()的实现方法中主要分为两个步骤,第一:构建排序二叉树,第二:平衡二叉树。
对于排序二叉树的创建,其添加节点的过程如下:
1、以根节点为初始节点进行检索。
2、与当前节点进行比对,若新增节点值较大,则以当前节点的右子节点作为新的当前节点。否则以当前节点的左子节点作为新的当前节点。
3、循环递归2步骤知道检索出合适的叶子节点为止。
4、将新增节点与3步骤中找到的节点进行比对,如果新增节点较大,则添加为右子节点;否则添加为左子节点。
按照这个步骤我们就可以将一个新增节点添加到排序二叉树中合适的位置。如下:
1 public V put(K key, V value) { 2 //用t表示二叉树的当前节点 3 Entry<K,V> t = root; 4 //t为null表示一个空树,即TreeMap中没有任何元素,直接插入 5 if (t == null) { 6 compare(key, key); // type (and possibly null) check 7 8 //将新的key-value键值对创建为一个Entry节点,并将该节点赋予给root 9 root = new Entry<>(key, value, null); 10 //容器的size = 1,表示TreeMap集合中存在一个元素 11 size = 1; 12 //修改次数 + 1 13 modCount++; 14 return null; 15 } 16 //cmp表示key排序的返回结果 17 int cmp; 18 Entry<K,V> parent; //父节点 19 // split comparator and comparable paths 20 //指定的排序算法 21 Comparator<? super K> cpr = comparator; 22 //如果cpr不为空,则采用既定的排序算法进行创建TreeMap集合 23 if (cpr != null) { 24 do { 25 parent = t;//parent指向上次循环后的t 26 //比较新增节点的key和当前节点key的大小 27 cmp = cpr.compare(key, t.key); 28 //cmp返回值小于0,表示新增节点的key小于当前节点的key,则以当前节点的左子节点作为新的当前节点 29 if (cmp < 0) 30 t = t.left; 31 //cmp返回值大于0,表示新增节点的key大于当前节点的key,则以当前节点的右子节点作为新的当前节点 32 else if (cmp > 0) 33 t = t.right; 34 //cmp返回值等于0,表示两个key值相等,则新值覆盖旧值,并返回新值 35 else 36 return t.setValue(value); 37 } while (t != null); 38 } 39 //如果cpr为空,则采用默认的排序算法进行创建TreeMap集合 40 else { 41 //key值为空抛出异常 42 if (key == null) 43 throw new NullPointerException(); 44 //下面处理过程和上面一样 45 Comparable<? super K> k = (Comparable<? super K>) key; 46 do { 47 parent = t; 48 cmp = k.compareTo(t.key); 49 if (cmp < 0) 50 t = t.left; 51 else if (cmp > 0) 52 t = t.right; 53 else 54 return t.setValue(value); 55 } while (t != null); 56 } 57 //将新增节点当做parent的子节点 58 Entry<K,V> e = new Entry<>(key, value, parent); 59 //如果新增节点的key小于parent的key,则当做左子节点 60 if (cmp < 0) 61 parent.left = e; 62 //如果新增节点的key大于parent的key,则当做右子节点 63 else 64 parent.right = e; 65 /** 66 * 上面已经完成了排序二叉树的的构建,将新增节点插入该树中的合适位置 67 * 下面fixAfterInsertion()方法就是对这棵树进行调整、平衡,具体过程参考上面的五种情况 68 */ 69 fixAfterInsertion(e); 70 //TreeMap元素数量 + 1 71 size++; 72 //TreeMap容器修改次数 + 1 73 modCount++; 74 return null; 75 }
上面代码中do{}代码块是实现排序二叉树的核心算法,通过该算法我们可以确认新增节点在该树的正确位置。找到正确位置后将插入即可,这样做了其实还没有完成,因为我知道TreeMap的底层实现是红黑树,红黑树是一棵平衡排序二叉树,普通的排序二叉树可能会出现失衡的情况,所以下一步就是要进行调整。fixAfterInsertion(e); 调整的过程务必会涉及到红黑树的左旋、右旋、着色三个基本操作。代码如下:
1 private void fixAfterInsertion(Entry<K,V> x) { 2 //新增节点的颜色为红色 3 x.color = RED; 4 5 while (x != null && x != root && x.parent.color == RED) { 6 //如果X的父节点(P)是其祖父节点(G)的左节点 7 if (parentOf(x) == leftOf(parentOf(parentOf(x)))) { 8 //获取X的叔节点y(U) 9 Entry<K,V> y = rightOf(parentOf(parentOf(x))); 10 //如果X的叔节点(U) 为红色(case1) 11 if (colorOf(y) == RED) { 12 //将“父节点”设为黑色。 13 setColor(parentOf(x), BLACK); 14 //将“叔叔节点”设为黑色。 15 setColor(y, BLACK); 16 //将“祖父节点”设为红色。 17 setColor(parentOf(parentOf(x)), RED); 18 //将“祖父节点”设为“当前节点”(红色节点) 19 x = parentOf(parentOf(x)); 20 } else {//如果X的叔节点(U) 为黑色 21 //如果X节点为其父节点(P)的右子树,则进行左旋转 22 if (x == rightOf(parentOf(x))) { 23 //将X的父节点作为X 24 x = parentOf(x); 25 //左旋转 26 rotateLeft(x); 27 } 28 //将X的父节点(P)设置为黑色 29 setColor(parentOf(x), BLACK); 30 //将X的祖父节点(G)设置红色 31 setColor(parentOf(parentOf(x)), RED); 32 //以X的祖父节点(G)为中心右旋转 33 rotateRight(parentOf(parentOf(x))); 34 } 35 } else {//如果X的父节点(P)是其父节点的父节点(G)的右节点 36 //获取X的叔节点y(U) 37 Entry<K,V> y = leftOf(parentOf(parentOf(x))); 38 //如果X的叔节点(U) 为红色 39 if (colorOf(y) == RED) { 40 //将X的父节点(P)设置为黑色 41 setColor(parentOf(x), BLACK); 42 //将X的叔节点(U)设置为黑色 43 setColor(y, BLACK); 44 //将X的祖父节点(G)设置红色 45 setColor(parentOf(parentOf(x)), RED); 46 //x设为x的祖父节点 47 x = parentOf(parentOf(x)); 48 } else {//如果X的叔节点(U为黑色 49 //如果X节点为其父节点(P)的左子树 50 if (x == leftOf(parentOf(x))) { 51 //将X的父节点作为X 52 x = parentOf(x); 53 //右旋转 54 rotateRight(x); 55 } 56 //将X的父节点(P)设置为黑色 57 setColor(parentOf(x), BLACK); 58 //将X的祖父节点(G)设置红色 59 setColor(parentOf(parentOf(x)), RED); 60 //以X的祖父点(G)为中心左旋转 61 rotateLeft(parentOf(parentOf(x))); 62 } 63 } 64 } 65 //将根节点G强制设置为黑色 66 root.color = BLACK; 67 }
对这段代码的研究我们发现,其处理过程完全符合红黑树新增节点的处理过程。所以在看这段代码的过程一定要对红黑树的新增节点过程有了解。在这个代码中还包含几个重要的操作。左旋(rotateLeft())、右旋(rotateRight())、着色(setColor())。
左旋:rotateLeft()
1 private void rotateLeft(Entry<K,V> p) { 2 if (p != null) { 3 //获取P的右子节点,其实这里就相当于新增节点N 4 Entry<K,V> r = p.right; 5 //将R的左子树设置为P的右子树 6 p.right = r.left; 7 //若R的左子树不为空,则将P设置为R左子树的父亲 8 if (r.left != null) 9 r.left.parent = p; 10 //将P的父亲设置R的父亲 11 r.parent = p.parent; 12 //如果P的父亲为空,则将R设置为跟节点 13 if (p.parent == null) 14 root = r; 15 //如果P为其父节点(G)的左子树,则将R设置为P父节点(G)左子树 16 else if (p.parent.left == p) 17 p.parent.left = r; 18 //否则R设置为P的父节点(G)的右子树 19 else 20 p.parent.right = r; 21 //将P设置为R的左子树 22 r.left = p; 23 //将R设置为P的父节点 24 p.parent = r; 25 } 26 }
右旋:rotateRight()
1 private void rotateRight(Entry<K,V> p) { 2 if (p != null) { 3 //将L设置为P的左子树 4 Entry<K,V> l = p.left; 5 //将L的右子树设置为P的左子树 6 p.left = l.right; 7 //若L的右子树不为空,则将P设置L的右子树的父节点 8 if (l.right != null) l.right.parent = p; 9 //将P的父节点设置为L的父节点 10 l.parent = p.parent; 11 //如果P的父节点为空,则将L设置根节点 12 if (p.parent == null) 13 root = l; 14 //若P为其父节点的右子树,则将L设置为P的父节点的右子树 15 else if (p.parent.right == p) 16 p.parent.right = l; 17 //否则将L设置为P的父节点的左子树 18 else p.parent.left = l; 19 //将P设置为L的右子树 20 l.right = p; 21 //将L设置为P的父节点 22 p.parent = l; 23 } 24 }
左旋、右旋的示意图如下:


(左旋) (右旋)
(图片来自:http://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html)
着色:setColor()
着色就是改变该节点的颜色,在红黑树中,它是依靠节点的颜色来维持平衡的。
private static <K,V> void setColor(Entry<K,V> p, boolean c) { if (p != null) p.color = c; }
第4部分 TreeMap delete()方法
红黑树删除节点
针对于红黑树的增加节点而言,删除显得更加复杂,使原本就复杂的红黑树变得更加复杂。同时删除节点和增加节点一样,同样是找到删除的节点,删除之后调整红黑树。但是这里的删除节点并不是直接删除,而是通过走了“弯路”通过一种捷径来删除的:找到被删除的节点D的子节点F,用F来替代D,不是直接删除D,因为D被F替代了,直接删除F即可。所以这里就将删除父节点D的事情转变为了删除子节点F的事情,这样处理就将复杂的删除事件简单化了。子节点F的规则是:如果有右分支,则是右分支最左边,否则,是左分支最右边的。

红-黑二叉树删除节点,最大的麻烦是要保持 各分支黑色节点数目相等。 因为是删除,所以不用担心存在颜色冲突问题——插入才会引起颜色冲突。
红黑树删除节点同样会分成几种情况,这里是按照待删除节点有几个儿子的情况来进行分类:
1、没有儿子,即为叶结点。直接把父结点的对应儿子指针设为NULL,删除儿子结点就OK了。
2、只有一个儿子。那么把父结点的相应儿子指针指向儿子的独生子,删除儿子结点也OK了。
3、有两个儿子。这种情况比较复杂,但还是比较简单。上面提到过用子节点C替代代替待删除节点D,然后删除子节点C即可。
下面就论各种删除情况来进行图例讲解,请时刻牢记红黑树的5点规定:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
删除节点比较复杂,那么在这里我们就约定一下规则:
1、下面要讲解的删除节点一定是实际要删除节点的后继节点(N),如前面提到的C。
2、下面提到的删除节点的树都是如下结构,该结构所选取的节点是待删除节点的右树的最左边子节点。这里我们规定真实删除节点为N、父节点为P、兄弟节点为W兄弟节点的两个子节点为X1、X2。如下图(2.1)。

现在我们就上面提到的三种情况进行分析、处理。
情况一、无子节点(红色节点)
这种情况对该节点直接删除即可,不会影响树的结构。因为该节点为叶子节点它不可能存在子节点-----如子节点为黑,则违反黑节点数原则(规定5),为红,则违反“颜色”原则(规定4)。 如上图(2.2)。
情况二、有一个子节点
这种情况处理也是非常简单的,用子节点替代待删除节点,然后删除子节点即可。如上图(2.3)
情况三、有两个子节点
这种情况可能会稍微有点儿复杂。它需要找到一个替代待删除节点(N)来替代它,然后删除N即可。它主要分为四种情况。
1、N的兄弟节点W为红色
2、N的兄弟w是黑色的,且w的俩个孩子都是黑色的。
3、N的兄弟w是黑色的,w的左孩子是红色,w的右孩子是黑色。
4、N的兄弟w是黑色的,且w的右孩子时红色的。
情况3.1、N的兄弟节点W为红色
W为红色,那么其子节点X1、X2必定全部为黑色,父节点P也为黑色。
处理策略是:(01) 将x的兄弟节点W设为“黑色”。(02) 将x的父节点P设为“红色”。(03) 对x的父节点P进行左旋。(04) 左旋后,重新设置x的兄弟节点。(即:将X的父节点的右孩子设为新的兄弟节点W)

情况3.2、N的兄弟w是黑色的,且w的俩个孩子都是黑色的。
处理策略是:(01) 将x的兄弟节点设为“红色”。(02) 设置“x的父节点”为“新的x节点”。

情况3.3、N的兄弟w是黑色的,w的左孩子是红色,w的右孩子是黑色。
针对这种情况是将节点W和其左子节点进行颜色交换,然后对W进行右旋转处理
处理策略是:
(01) 将x兄弟节点的左孩子X1设为“黑色”。(02) 将x兄弟节点W设为“红色”。(03) 对x的兄弟节点W进行右旋。(04) 右旋后,重新设置x的兄弟节点。(即:将X的父节点的右孩子设为新的兄弟节点)

情况3.4、N的兄弟w是黑色的,且w的右孩子时红色的。
交换W和父节点P的颜色,同时对P进行左旋转操作。这样就把左边缺失的黑色节点给补回来了。同时将W的右子节点X2置黑。这样左右都达到了平衡。

处理策略是:
(01) 将x父节点P颜色赋值给 x的兄弟节点W。(02) 将x父节点P设为“黑色”。(03) 将x兄弟节点的右子节X2设为“黑色”。(04) 对x的父节点P进行左旋。(05) 设置“x”为“根节点”。
上述各种操作完成,最后都要把X设为黑色。
下面列表给出每种情况以及解决方法:
| 现象说明 | 处理策略 | |
| Case 1 | x的兄弟节点是红色。(此时x的父节点和x的兄弟节点的子节点都是黑节点)。 | (01) 将x的兄弟节点设为“黑色”。 |
| (02) 将x的父节点设为“红色”。 | ||
| (03) 对x的父节点进行左旋。 | ||
| (04) 左旋后,重新设置x的兄弟节点。 | ||
| Case 2 | x的兄弟节点是黑色,x的兄弟节点的两个孩子都是黑色。 | (01) 将x的兄弟节点设为“红色”。 |
| (02) 设置“x的父节点”为“新的x节点”。 | ||
| Case 3 | x的兄弟节点是黑色;x的兄弟节点的左孩子是红色,右孩子是黑色的。 | (01) 将x兄弟节点的左孩子设为“黑色”。 |
| (02) 将x兄弟节点设为“红色”。 | ||
| (03) 对x的兄弟节点进行右旋。 | ||
| (04) 右旋后,重新设置x的兄弟节点。 | ||
| Case 4 | x的兄弟节点是黑色;x的兄弟节点的右孩子是红色的,x的兄弟节点的左孩子任意颜色。 | (01) 将x父节点颜色 赋值给 x的兄弟节点。 |
| (02) 将x父节点设为“黑色”。 | ||
| (03) 将x兄弟节点的右子节设为“黑色”。 | ||
| (04) 对x的父节点进行左旋。 | ||
| (05) 设置“x”为“根节点”。 |
1 /** 2 * Delete node p, and then rebalance the tree. 3 */ 4 private void deleteEntry(Entry<K,V> p) { 5 modCount++; 6 size--; 7 8 /* 9 * 被删除节点的左子树和右子树都不为空,那么就用 p节点的中序后继节点代替 p 节点 10 * successor(P)方法为寻找P的替代节点。规则是右分支最左边,或者 左分支最右边的节点 11 * 12 */ 13 if (p.left != null && p.right != null) { 14 Entry<K,V> s = successor(p); 15 p.key = s.key; 16 p.value = s.value; 17 p = s; 18 } // p has 2 children 19 20 //replacement为替代节点,如果P的左子树存在那么就用左子树替代,否则用右子树替代 21 Entry<K,V> replacement = (p.left != null ? p.left : p.right); 22 23 //如果替代节点不为空 24 if (replacement != null) { 25 // Link replacement to parent 26 /* 27 *replacement来替代P节点 28 */ 29 //若P没有父节点,则跟节点直接变成replacement 30 replacement.parent = p.parent; 31 if (p.parent == null) 32 root = replacement; 33 //如果P为左节点,则用replacement来替代为左节点 34 else if (p == p.parent.left) 35 p.parent.left = replacement; 36 //如果P为右节点,则用replacement来替代为右节点 37 else 38 p.parent.right = replacement; 39 40 // Null out links so they are OK to use by fixAfterDeletion. 41 p.left = p.right = p.parent = null; 42 43 /* 44 * 若P为红色直接删除,红黑树保持平衡 45 * 但是若P为黑色,则需要调整红黑树使其保持平衡 46 */ 47 // Fix replacement 48 if (p.color == BLACK) 49 fixAfterDeletion(replacement); 50 } else if (p.parent == null) { // return if we are the only node. p没有父节点,表示为P根节点,直接删除即可 51 root = null; 52 } else { // No children. Use self as phantom replacement and unlink. 53 if (p.color == BLACK) 54 fixAfterDeletion(p); 55 56 //删除P节点 57 if (p.parent != null) { 58 if (p == p.parent.left) 59 p.parent.left = null; 60 else if (p == p.parent.right) 61 p.parent.right = null; 62 p.parent = null; 63 } 64 } 65 }
寻找替代节点replacement,其实现方法为successor(),即寻找中序后继节点。如下:
1 /** 2 * Returns the successor of the specified Entry, or null if no such. 3 */ 4 static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { 5 if (t == null) 6 return null; 7 else if (t.right != null) { 8 Entry<K,V> p = t.right; 9 while (p.left != null) 10 p = p.left; 11 return p; 12 } else { 13 Entry<K,V> p = t.parent; 14 Entry<K,V> ch = t; 15 while (p != null && ch == p.right) { 16 ch = p; 17 p = p.parent; 18 } 19 return p; 20 } 21 }
删除完节点后,就要根据情况来对红黑树进行复杂的调整:fixAfterDeletion()。
1 private void fixAfterDeletion(Entry<K,V> x) { 2 // 删除节点需要一直迭代,知道 直到 x 不是根节点,且 x 的颜色是黑色 3 while (x != root && colorOf(x) == BLACK) { 4 //若X节点为左节点 5 if (x == leftOf(parentOf(x))) { 6 //获取其兄弟节点 7 Entry<K,V> sib = rightOf(parentOf(x)); 8 9 //如果兄弟节点为红色----(情况3.1) 10 if (colorOf(sib) == RED) { 11 setColor(sib, BLACK); 12 setColor(parentOf(x), RED); 13 rotateLeft(parentOf(x)); 14 sib = rightOf(parentOf(x)); 15 } 16 17 //兄弟节点为黑色 18 //兄弟节点的左右子节点都是黑色----(情况3.2) 19 if (colorOf(leftOf(sib)) == BLACK && 20 colorOf(rightOf(sib)) == BLACK) { 21 setColor(sib, RED); 22 x = parentOf(x); 23 } else { 24 //兄弟节点的只有右子节点为黑色,左子节点为红色----(情况3.3) 25 if (colorOf(rightOf(sib)) == BLACK) { 26 setColor(leftOf(sib), BLACK); 27 setColor(sib, RED); 28 rotateRight(sib); 29 sib = rightOf(parentOf(x)); 30 } 31 //兄弟节点的右子节点是红色----(情况3.4) 32 setColor(sib, colorOf(parentOf(x))); 33 setColor(parentOf(x), BLACK); 34 setColor(rightOf(sib), BLACK); 35 rotateLeft(parentOf(x)); 36 x = root; 37 } 38 } else { // 对称的,X节点为右节点与其为做节点处理过程差不多,这里就不在累述了 39 Entry<K,V> sib = leftOf(parentOf(x)); 40 41 if (colorOf(sib) == RED) { 42 setColor(sib, BLACK); 43 setColor(parentOf(x), RED); 44 rotateRight(parentOf(x)); 45 sib = leftOf(parentOf(x)); 46 } 47 48 if (colorOf(rightOf(sib)) == BLACK && 49 colorOf(leftOf(sib)) == BLACK) { 50 setColor(sib, RED); 51 x = parentOf(x); 52 } else { 53 if (colorOf(leftOf(sib)) == BLACK) { 54 setColor(rightOf(sib), BLACK); 55 setColor(sib, RED); 56 rotateLeft(sib); 57 sib = leftOf(parentOf(x)); 58 } 59 setColor(sib, colorOf(parentOf(x))); 60 setColor(parentOf(x), BLACK); 61 setColor(leftOf(sib), BLACK); 62 rotateRight(parentOf(x)); 63 x = root; 64 } 65 } 66 } 67 68 setColor(x, BLACK); 69 }
第5部分 TreeMap的相关函数
TreeMap的 firstEntry()、 lastEntry()、 lowerEntry()、 higherEntry()、 floorEntry()、 ceilingEntry()、 pollFirstEntry() 、 pollLastEntry() 原理都是类似的;下面以firstEntry()来进行详细说明
我们先看看firstEntry()和getFirstEntry()的代码:
1 public final Map.Entry<K,V> firstEntry() { 2 return exportEntry(subLowest()); 3 } 4 5 final Entry<K,V> getFirstEntry() { 6 Entry<K,V> p = root; 7 if (p != null) 8 while (p.left != null) 9 p = p.left; 10 return p; 11 }
从中,我们可以看出 firstEntry() 和 getFirstEntry() 都是用于获取第一个节点。
但是,firstEntry() 是对外接口; getFirstEntry() 是内部接口。而且,firstEntry() 是通过 getFirstEntry() 来实现的。那为什么外界不能直接调用 getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
这么做的目的是:防止用户修改返回的Entry。getFirstEntry()返回的Entry是可以被修改的,但是经过firstEntry()返回的Entry不能被修改,只可以读取Entry的key值和value值。下面我们看看到底是如何实现的。
(01) getFirstEntry()返回的是Entry节点,而Entry是红黑树的节点,然后可以调用Entry的getKey()、getValue()来获取key和value值,以及调用setValue()来修改value的值。
(02) firstEntry()返回的是exportEntry(getFirstEntry())。
1 /** 2 * Return SimpleImmutableEntry for entry, or null if null 3 */ 4 static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) { 5 return (e == null) ? null : 6 new AbstractMap.SimpleImmutableEntry<>(e); 7 }
实际上,exportEntry() 是新建一个AbstractMap.SimpleImmutableEntry类型的对象,并返回。
SimpleImmutableEntry的实现在AbstractMap.java中,下面我们看看AbstractMap.SimpleImmutableEntry是如何实现的,代码如下:
1 public static class SimpleImmutableEntry<K,V> 2 implements Entry<K,V>, java.io.Serializable 3 { 4 private static final long serialVersionUID = 7138329143949025153L; 5 6 private final K key; 7 private final V value; 8 9 public SimpleImmutableEntry(K key, V value) { 10 this.key = key; 11 this.value = value; 12 } 13 14 public SimpleImmutableEntry(Entry<? extends K, ? extends V> entry) { 15 this.key = entry.getKey(); 16 this.value = entry.getValue(); 17 } 18 19 public K getKey() { 20 return key; 21 } 22 23 public V getValue() { 24 return value; 25 } 26 27 public V setValue(V value) { 28 throw new UnsupportedOperationException(); 29 } 30 31 public boolean equals(Object o) { 32 if (!(o instanceof Map.Entry)) 33 return false; 34 Map.Entry e = (Map.Entry)o; 35 return eq(key, e.getKey()) && eq(value, e.getValue()); 36 } 37 38 public int hashCode() { 39 return (key == null ? 0 : key.hashCode()) ^ 40 (value == null ? 0 : value.hashCode()); 41 } 42 43 public String toString() { 44 return key + "=" + value; 45 } 46 47 }
从中,我们可以看出SimpleImmutableEntry实际上是简化的key-value节点。
它只提供了getKey()、getValue()方法类获取节点的值;但不能修改value的值,因为调用 setValue() 会抛出异常UnsupportedOperationException();
再回到我们之前的问题:那为什么外界不能直接调用 getFirstEntry(),而需要多此一举的调用 firstEntry() 呢?
现在我们清晰的了解到:
(01) firstEntry()是对外接口,而getFirstEntry()是内部接口。
(02) 对firstEntry()返回的Entry对象只能进行getKey()、getValue()等读取操作;而对getFirstEntry()返回的对象除了可以进行读取操作之后,还可以通过setValue()修改值。
TreeMap的firstKey()、lastKey()、lowerKey()、higherKey()、floorKey()、ceilingKey()原理都是类似的;下面以ceilingKey()来进行详细说明
ceilingKey(K key)的作用是“返回大于/等于key的最小的键值对所对应的KEY,没有的话返回null”,它的代码如下:
public K ceilingKey(K key) { return keyOrNull(getCeilingEntry(key)); }
ceilingKey()是通过getCeilingEntry()实现的。其中keyOrNull()的代码很简单,它是获取节点的key,没有的话,返回null。
static <K,V> K keyOrNull(TreeMap.Entry<K,V> e) { return (e == null) ? null : e.key; }
getCeilingEntry(K key)的作用是“返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。”。它的实现代码如下:
1 final Entry<K,V> getCeilingEntry(K key) { 2 Entry<K,V> p = root; 3 while (p != null) { 4 int cmp = compare(key, p.key); 5 // 情况一:若“p的key” > key。 6 // 若 p 存在左孩子,则设 p=“p的左孩子”; 7 // 否则,返回p 8 if (cmp < 0) { 9 if (p.left != null) 10 p = p.left; 11 else 12 return p; 13 } else if (cmp > 0) {// 情况二:若“p的key” < key。 14 // 若 p 存在右孩子,则设 p=“p的右孩子” 15 if (p.right != null) { 16 p = p.right; 17 } else { 18 // 若 p 不存在右孩子,则找出 p 的后继节点,并返回 19 Entry<K,V> parent = p.parent; 20 Entry<K,V> ch = p; 21 while (parent != null && ch == parent.right) { 22 ch = parent; 23 parent = parent.parent; 24 } 25 return parent; 26 } 27 } else // 情况三:若“p的key” = key。 28 return p; 29 } 30 return null; 31 }
values() 返回“TreeMap中值的集合”
values()的实现代码如下:
public Collection<V> values() { Collection<V> vs = values; return (vs != null) ? vs : (values = new Values()); }
说明:values()是通过 new Values() 来实现 “返回TreeMap中值的集合”。
那么Values()是如何实现的呢? 没错!由于返回的是值的集合,那么Values()肯定返回一个集合;而Values()正好是集合类Value的构造函数。Values继承于AbstractCollection,它的代码如下:
1 class Values extends AbstractCollection<V> { 2 // 返回迭代器 3 public Iterator<V> iterator() { 4 return new ValueIterator(getFirstEntry()); 5 } 6 7 // 返回个数 8 public int size() { 9 return TreeMap.this.size(); 10 } 11 12 // "TreeMap的值的集合"中是否包含"对象o" 13 public boolean contains(Object o) { 14 return TreeMap.this.containsValue(o); 15 } 16 17 // 删除"TreeMap的值的集合"中的"对象o" 18 public boolean remove(Object o) { 19 for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) { 20 if (valEquals(e.getValue(), o)) { 21 deleteEntry(e); 22 return true; 23 } 24 } 25 return false; 26 } 27 28 // 清空删除"TreeMap的值的集合" 29 public void clear() { 30 TreeMap.this.clear(); 31 } 32 }
说明:从中,我们可以知道Values类就是一个集合。而 AbstractCollection 已经实现了除 size() 和 iterator() 之外的其它函数,因此只需要在Values类中实现这两个函数即可。
size() 的实现非常简单,Values集合中元素的个数=该TreeMap的元素个数。(TreeMap每一个元素都有一个值嘛!)
iterator() 则返回一个迭代器,用于遍历Values。下面,我们一起可以看看iterator()的实现:
public Iterator<V> iterator() { return new ValueIterator(getFirstEntry()); }
说明: iterator() 是通过ValueIterator() 返回迭代器的,ValueIterator是一个类。代码如下:
final class ValueIterator extends PrivateEntryIterator<V> { ValueIterator(Entry<K,V> first) { super(first); } public V next() { return nextEntry().value; } }
说明:ValueIterator的代码很简单,它的主要实现应该在它的父类PrivateEntryIterator中。下面我们一起看看PrivateEntryIterator的代码:
1 abstract class PrivateEntryIterator<T> implements Iterator<T> { 2 // 下一节点 3 Entry<K,V> next; 4 // 上一次返回的节点 5 Entry<K,V> lastReturned; 6 int expectedModCount; 7 8 PrivateEntryIterator(Entry<K,V> first) { 9 expectedModCount = modCount; 10 lastReturned = null; 11 next = first; 12 } 13 14 // 是否存在下一个节点 15 public final boolean hasNext() { 16 return next != null; 17 } 18 19 // 返回下一个节点 20 final Entry<K,V> nextEntry() { 21 Entry<K,V> e = next; 22 if (e == null) 23 throw new NoSuchElementException(); 24 if (modCount != expectedModCount) 25 throw new ConcurrentModificationException(); 26 next = successor(e); 27 lastReturned = e; 28 return e; 29 } 30 31 // 返回上一节点 32 final Entry<K,V> prevEntry() { 33 Entry<K,V> e = next; 34 if (e == null) 35 throw new NoSuchElementException(); 36 if (modCount != expectedModCount) 37 throw new ConcurrentModificationException(); 38 next = predecessor(e); 39 lastReturned = e; 40 return e; 41 } 42 43 // 删除当前节点 44 public void remove() { 45 if (lastReturned == null) 46 throw new IllegalStateException(); 47 if (modCount != expectedModCount) 48 throw new ConcurrentModificationException(); 49 // deleted entries are replaced by their successors 50 if (lastReturned.left != null && lastReturned.right != null) 51 next = lastReturned; 52 deleteEntry(lastReturned); 53 expectedModCount = modCount; 54 lastReturned = null; 55 } 56 }
说明:PrivateEntryIterator是一个抽象类,它的实现很简单,只只实现了Iterator的remove()和hasNext()接口,没有实现next()接口。
而我们在ValueIterator中已经实现的next()接口。
至此,我们就了解了iterator()的完整实现了。
有关迭代器的其他内容请参加设计模式 3 —— 迭代器和组合模式
5.4 TreeMap的entrySet()函数
entrySet() 返回“键值对集合”。顾名思义,它返回的是一个集合,集合的元素是“键值对”。
下面,我们看看它是如何实现的?entrySet() 的实现代码如下:
public Set<Map.Entry<K,V>> entrySet() { EntrySet es = entrySet; return (es != null) ? es : (entrySet = new EntrySet()); }
说明:entrySet()返回的是一个EntrySet对象。
下面我们看看EntrySet的代码:
1 // EntrySet是“TreeMap的所有键值对组成的集合”, 2 // EntrySet集合的单位是单个“键值对”。 3 class EntrySet extends AbstractSet<Map.Entry<K,V>> { 4 public Iterator<Map.Entry<K,V>> iterator() { 5 return new EntryIterator(getFirstEntry()); 6 } 7 8 // EntrySet中是否包含“键值对Object” 9 public boolean contains(Object o) { 10 if (!(o instanceof Map.Entry)) 11 return false; 12 Map.Entry<K,V> entry = (Map.Entry<K,V>) o; 13 V value = entry.getValue(); 14 Entry<K,V> p = getEntry(entry.getKey()); 15 return p != null && valEquals(p.getValue(), value); 16 } 17 18 // 删除EntrySet中的“键值对Object” 19 public boolean remove(Object o) { 20 if (!(o instanceof Map.Entry)) 21 return false; 22 Map.Entry<K,V> entry = (Map.Entry<K,V>) o; 23 V value = entry.getValue(); 24 Entry<K,V> p = getEntry(entry.getKey()); 25 if (p != null && valEquals(p.getValue(), value)) { 26 deleteEntry(p); 27 return true; 28 } 29 return false; 30 } 31 32 // 返回EntrySet中元素个数 33 public int size() { 34 return TreeMap.this.size(); 35 } 36 37 public void clear() { 38 TreeMap.this.clear(); 39 } 40 }
说明:
EntrySet是“TreeMap的所有键值对组成的集合”,而且它单位是单个“键值对”。
EntrySet是一个集合,它继承于AbstractSet。而AbstractSet实现了除size() 和 iterator() 之外的其它函数,因此,我们重点了解一下EntrySet的size() 和 iterator() 函数
size() 的实现非常简单,AbstractSet集合中元素的个数=该TreeMap的元素个数。
iterator() 则返回一个迭代器,用于遍历AbstractSet。从上面的源码中,我们可以发现iterator() 是通过EntryIterator实现的;下面我们看看EntryIterator的源码:
final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> { EntryIterator(Entry<K,V> first) { super(first); } public Map.Entry<K,V> next() { return nextEntry(); } }
说明:和Values类一样,EntryIterator也继承于PrivateEntryIterator类。
TreeMap实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个TreeMap对象并返回。
1 // 克隆一个TreeMap,并返回Object对象 2 public Object clone() { 3 TreeMap<K,V> clone = null; 4 try { 5 clone = (TreeMap<K,V>) super.clone(); 6 } catch (CloneNotSupportedException e) { 7 throw new InternalError(); 8 } 9 10 // Put clone into "virgin" state (except for comparator) 11 clone.root = null; 12 clone.size = 0; 13 clone.modCount = 0; 14 clone.entrySet = null; 15 clone.navigableKeySet = null; 16 clone.descendingMap = null; 17 18 // Initialize clone with our mappings 19 try { 20 clone.buildFromSorted(size, entrySet().iterator(), null, null); 21 } catch (java.io.IOException cannotHappen) { 22 } catch (ClassNotFoundException cannotHappen) { 23 } 24 25 return clone; 26 }
TreeMap实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数是writeObject(),它的作用是将TreeMap的“容量,所有的Entry”都写入到输出流中。
而串行读取函数是readObject(),它的作用是将TreeMap的“容量、所有的Entry”依次读出。
readObject() 和 writeObject() 正好是一对,通过它们,能实现TreeMap的串行传输。
1 // java.io.Serializable的写入函数 2 // 将TreeMap的“容量,所有的Entry”都写入到输出流中 3 private void writeObject(java.io.ObjectOutputStream s) 4 throws java.io.IOException { 5 // Write out the Comparator and any hidden stuff 6 s.defaultWriteObject(); 7 8 // Write out size (number of Mappings) 9 s.writeInt(size); 10 11 // Write out keys and values (alternating) 12 for (Iterator<Map.Entry<K,V>> i = entrySet().iterator(); i.hasNext(); ) { 13 Map.Entry<K,V> e = i.next(); 14 s.writeObject(e.getKey()); 15 s.writeObject(e.getValue()); 16 } 17 }
1 // java.io.Serializable的读取函数:根据写入方式读出 2 // 先将TreeMap的“容量、所有的Entry”依次读出 3 private void readObject(final java.io.ObjectInputStream s) 4 throws java.io.IOException, ClassNotFoundException { 5 // Read in the Comparator and any hidden stuff 6 s.defaultReadObject(); 7 8 // Read in size 9 int size = s.readInt(); 10 11 buildFromSorted(size, null, s, null); 12 }
举例讲解一个descendingMap()
descendingMap() 的作用是返回当前TreeMap的反向的TreeMap。所谓反向,就是排序顺序和原始的顺序相反。
我们已经知道TreeMap是一颗红黑树,而红黑树是有序的。
TreeMap的排序方式是通过比较器,在创建TreeMap的时候,若指定了比较器,则使用该比较器;否则,就使用Java的默认比较器。
而获取TreeMap的反向TreeMap的原理就是将比较器反向即可!
理解了descendingMap()的反向原理之后,再讲解一下descendingMap()的代码。
// 获取TreeMap的降序Map public NavigableMap<K, V> descendingMap() { NavigableMap<K, V> km = descendingMap; return (km != null) ? km : (descendingMap = new DescendingSubMap(this, true, null, true, true, null, true)); }
从中,我们看出descendingMap()实际上是返回DescendingSubMap类的对象。下面,看看DescendingSubMap的源码:
1 static final class DescendingSubMap<K,V> extends NavigableSubMap<K,V> { 2 private static final long serialVersionUID = 912986545866120460L; 3 DescendingSubMap(TreeMap<K,V> m, 4 boolean fromStart, K lo, boolean loInclusive, 5 boolean toEnd, K hi, boolean hiInclusive) { 6 super(m, fromStart, lo, loInclusive, toEnd, hi, hiInclusive); 7 } 8 9 // 反转的比较器:是将原始比较器反转得到的。 10 private final Comparator<? super K> reverseComparator = 11 Collections.reverseOrder(m.comparator); 12 13 // 获取反转比较器 14 public Comparator<? super K> comparator() { 15 return reverseComparator; 16 } 17 18 // 获取“子Map”。 19 // 范围是从fromKey 到 toKey;fromInclusive是是否包含fromKey的标记,toInclusive是是否包含toKey的标记 20 public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, 21 K toKey, boolean toInclusive) { 22 if (!inRange(fromKey, fromInclusive)) 23 throw new IllegalArgumentException("fromKey out of range"); 24 if (!inRange(toKey, toInclusive)) 25 throw new IllegalArgumentException("toKey out of range"); 26 return new DescendingSubMap(m, 27 false, toKey, toInclusive, 28 false, fromKey, fromInclusive); 29 } 30 31 // 获取“Map的头部”。 32 // 范围从第一个节点 到 toKey, inclusive是是否包含toKey的标记 33 public NavigableMap<K,V> headMap(K toKey, boolean inclusive) { 34 if (!inRange(toKey, inclusive)) 35 throw new IllegalArgumentException("toKey out of range"); 36 return new DescendingSubMap(m, 37 false, toKey, inclusive, 38 toEnd, hi, hiInclusive); 39 } 40 41 // 获取“Map的尾部”。 42 // 范围是从 fromKey 到 最后一个节点,inclusive是是否包含fromKey的标记 43 public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive){ 44 if (!inRange(fromKey, inclusive)) 45 throw new IllegalArgumentException("fromKey out of range"); 46 return new DescendingSubMap(m, 47 fromStart, lo, loInclusive, 48 false, fromKey, inclusive); 49 } 50 51 // 获取对应的降序Map 52 public NavigableMap<K,V> descendingMap() { 53 NavigableMap<K,V> mv = descendingMapView; 54 return (mv != null) ? mv : 55 (descendingMapView = 56 new AscendingSubMap(m, 57 fromStart, lo, loInclusive, 58 toEnd, hi, hiInclusive)); 59 } 60 61 // 返回“升序Key迭代器” 62 Iterator<K> keyIterator() { 63 return new DescendingSubMapKeyIterator(absHighest(), absLowFence()); 64 } 65 66 // 返回“降序Key迭代器” 67 Iterator<K> descendingKeyIterator() { 68 return new SubMapKeyIterator(absLowest(), absHighFence()); 69 } 70 71 // “降序EntrySet集合”类 72 // 实现了iterator() 73 final class DescendingEntrySetView extends EntrySetView { 74 public Iterator<Map.Entry<K,V>> iterator() { 75 return new DescendingSubMapEntryIterator(absHighest(), absLowFence()); 76 } 77 } 78 79 // 返回“降序EntrySet集合” 80 public Set<Map.Entry<K,V>> entrySet() { 81 EntrySetView es = entrySetView; 82 return (es != null) ? es : new DescendingEntrySetView(); 83 } 84 85 TreeMap.Entry<K,V> subLowest() { return absHighest(); } 86 TreeMap.Entry<K,V> subHighest() { return absLowest(); } 87 TreeMap.Entry<K,V> subCeiling(K key) { return absFloor(key); } 88 TreeMap.Entry<K,V> subHigher(K key) { return absLower(key); } 89 TreeMap.Entry<K,V> subFloor(K key) { return absCeiling(key); } 90 TreeMap.Entry<K,V> subLower(K key) { return absHigher(key); } 91 }
从中,我们看出DescendingSubMap是降序的SubMap,它的实现机制是将“SubMap的比较器反转”。
它继承于NavigableSubMap。而NavigableSubMap是一个继承于AbstractMap的抽象类;它包括2个子类——"(升序)AscendingSubMap"和"(降序)DescendingSubMap"。NavigableSubMap为它的两个子类实现了许多公共API。
下面看看NavigableSubMap的源码。
1 static abstract class NavigableSubMap<K,V> extends AbstractMap<K,V> 2 implements NavigableMap<K,V>, java.io.Serializable { 3 // TreeMap的拷贝 4 final TreeMap<K,V> m; 5 // lo是“子Map范围的最小值”,hi是“子Map范围的最大值”; 6 // loInclusive是“是否包含lo的标记”,hiInclusive是“是否包含hi的标记” 7 // fromStart是“表示是否从第一个节点开始计算”, 8 // toEnd是“表示是否计算到最后一个节点 ” 9 final K lo, hi; 10 final boolean fromStart, toEnd; 11 final boolean loInclusive, hiInclusive; 12 13 // 构造函数 14 NavigableSubMap(TreeMap<K,V> m, 15 boolean fromStart, K lo, boolean loInclusive, 16 boolean toEnd, K hi, boolean hiInclusive) { 17 if (!fromStart && !toEnd) { 18 if (m.compare(lo, hi) > 0) 19 throw new IllegalArgumentException("fromKey > toKey"); 20 } else { 21 if (!fromStart) // type check 22 m.compare(lo, lo); 23 if (!toEnd) 24 m.compare(hi, hi); 25 } 26 27 this.m = m; 28 this.fromStart = fromStart; 29 this.lo = lo; 30 this.loInclusive = loInclusive; 31 this.toEnd = toEnd; 32 this.hi = hi; 33 this.hiInclusive = hiInclusive; 34 } 35 36 // 判断key是否太小 37 final boolean tooLow(Object key) { 38 // 若该SubMap不包括“起始节点”, 39 // 并且,“key小于最小键(lo)”或者“key等于最小键(lo),但最小键却没包括在该SubMap内” 40 // 则判断key太小。其余情况都不是太小! 41 if (!fromStart) { 42 int c = m.compare(key, lo); 43 if (c < 0 || (c == 0 && !loInclusive)) 44 return true; 45 } 46 return false; 47 } 48 49 // 判断key是否太大 50 final boolean tooHigh(Object key) { 51 // 若该SubMap不包括“结束节点”, 52 // 并且,“key大于最大键(hi)”或者“key等于最大键(hi),但最大键却没包括在该SubMap内” 53 // 则判断key太大。其余情况都不是太大! 54 if (!toEnd) { 55 int c = m.compare(key, hi); 56 if (c > 0 || (c == 0 && !hiInclusive)) 57 return true; 58 } 59 return false; 60 } 61 62 // 判断key是否在“lo和hi”开区间范围内 63 final boolean inRange(Object key) { 64 return !tooLow(key) && !tooHigh(key); 65 } 66 67 // 判断key是否在封闭区间内 68 final boolean inClosedRange(Object key) { 69 return (fromStart || m.compare(key, lo) >= 0) 70 && (toEnd || m.compare(hi, key) >= 0); 71 } 72 73 // 判断key是否在区间内, inclusive是区间开关标志 74 final boolean inRange(Object key, boolean inclusive) { 75 return inclusive ? inRange(key) : inClosedRange(key); 76 } 77 78 // 返回最低的Entry 79 final TreeMap.Entry<K,V> absLowest() { 80 // 若“包含起始节点”,则调用getFirstEntry()返回第一个节点 81 // 否则的话,若包括lo,则调用getCeilingEntry(lo)获取大于/等于lo的最小的Entry; 82 // 否则,调用getHigherEntry(lo)获取大于lo的最小Entry 83 TreeMap.Entry<K,V> e = 84 (fromStart ? m.getFirstEntry() : 85 (loInclusive ? m.getCeilingEntry(lo) : 86 m.getHigherEntry(lo))); 87 return (e == null || tooHigh(e.key)) ? null : e; 88 } 89 90 // 返回最高的Entry 91 final TreeMap.Entry<K,V> absHighest() { 92 // 若“包含结束节点”,则调用getLastEntry()返回最后一个节点 93 // 否则的话,若包括hi,则调用getFloorEntry(hi)获取小于/等于hi的最大的Entry; 94 // 否则,调用getLowerEntry(hi)获取大于hi的最大Entry 95 TreeMap.Entry<K,V> e = 96 TreeMap.Entry<K,V> e = 97 (toEnd ? m.getLastEntry() : 98 (hiInclusive ? m.getFloorEntry(hi) : 99 m.getLowerEntry(hi))); 100 return (e == null || tooLow(e.key)) ? null : e; 101 } 102 103 // 返回"大于/等于key的最小的Entry" 104 final TreeMap.Entry<K,V> absCeiling(K key) { 105 // 只有在“key太小”的情况下,absLowest()返回的Entry才是“大于/等于key的最小Entry” 106 // 其它情况下不行。例如,当包含“起始节点”时,absLowest()返回的是最小Entry了! 107 if (tooLow(key)) 108 return absLowest(); 109 // 获取“大于/等于key的最小Entry” 110 TreeMap.Entry<K,V> e = m.getCeilingEntry(key); 111 return (e == null || tooHigh(e.key)) ? null : e; 112 } 113 114 // 返回"大于key的最小的Entry" 115 final TreeMap.Entry<K,V> absHigher(K key) { 116 // 只有在“key太小”的情况下,absLowest()返回的Entry才是“大于key的最小Entry” 117 // 其它情况下不行。例如,当包含“起始节点”时,absLowest()返回的是最小Entry了,而不一定是“大于key的最小Entry”! 118 if (tooLow(key)) 119 return absLowest(); 120 // 获取“大于key的最小Entry” 121 TreeMap.Entry<K,V> e = m.getHigherEntry(key); 122 return (e == null || tooHigh(e.key)) ? null : e; 123 } 124 125 // 返回"小于/等于key的最大的Entry" 126 final TreeMap.Entry<K,V> absFloor(K key) { 127 // 只有在“key太大”的情况下,(absHighest)返回的Entry才是“小于/等于key的最大Entry” 128 // 其它情况下不行。例如,当包含“结束节点”时,absHighest()返回的是最大Entry了! 129 if (tooHigh(key)) 130 return absHighest(); 131 // 获取"小于/等于key的最大的Entry" 132 TreeMap.Entry<K,V> e = m.getFloorEntry(key); 133 return (e == null || tooLow(e.key)) ? null : e; 134 } 135 136 // 返回"小于key的最大的Entry" 137 final TreeMap.Entry<K,V> absLower(K key) { 138 // 只有在“key太大”的情况下,(absHighest)返回的Entry才是“小于key的最大Entry” 139 // 其它情况下不行。例如,当包含“结束节点”时,absHighest()返回的是最大Entry了,而不一定是“小于key的最大Entry”! 140 if (tooHigh(key)) 141 return absHighest(); 142 // 获取"小于key的最大的Entry" 143 TreeMap.Entry<K,V> e = m.getLowerEntry(key); 144 return (e == null || tooLow(e.key)) ? null : e; 145 } 146 147 // 返回“大于最大节点中的最小节点”,不存在的话,返回null 148 final TreeMap.Entry<K,V> absHighFence() { 149 return (toEnd ? null : (hiInclusive ? 150 m.getHigherEntry(hi) : 151 m.getCeilingEntry(hi))); 152 } 153 154 // 返回“小于最小节点中的最大节点”,不存在的话,返回null 155 final TreeMap.Entry<K,V> absLowFence() { 156 return (fromStart ? null : (loInclusive ? 157 m.getLowerEntry(lo) : 158 m.getFloorEntry(lo))); 159 } 160 161 // 下面几个abstract方法是需要NavigableSubMap的实现类实现的方法 162 abstract TreeMap.Entry<K,V> subLowest(); 163 abstract TreeMap.Entry<K,V> subHighest(); 164 abstract TreeMap.Entry<K,V> subCeiling(K key); 165 abstract TreeMap.Entry<K,V> subHigher(K key); 166 abstract TreeMap.Entry<K,V> subFloor(K key); 167 abstract TreeMap.Entry<K,V> subLower(K key); 168 // 返回“顺序”的键迭代器 169 abstract Iterator<K> keyIterator(); 170 // 返回“逆序”的键迭代器 171 abstract Iterator<K> descendingKeyIterator(); 172 173 // 返回SubMap是否为空。空的话,返回true,否则返回false 174 public boolean isEmpty() { 175 return (fromStart && toEnd) ? m.isEmpty() : entrySet().isEmpty(); 176 } 177 178 // 返回SubMap的大小 179 public int size() { 180 return (fromStart && toEnd) ? m.size() : entrySet().size(); 181 } 182 183 // 返回SubMap是否包含键key 184 public final boolean containsKey(Object key) { 185 return inRange(key) && m.containsKey(key); 186 } 187 188 // 将key-value 插入SubMap中 189 public final V put(K key, V value) { 190 if (!inRange(key)) 191 throw new IllegalArgumentException("key out of range"); 192 return m.put(key, value); 193 } 194 195 // 获取key对应值 196 public final V get(Object key) { 197 return !inRange(key)? null : m.get(key); 198 } 199 200 // 删除key对应的键值对 201 public final V remove(Object key) { 202 return !inRange(key)? null : m.remove(key); 203 } 204 205 // 获取“大于/等于key的最小键值对” 206 public final Map.Entry<K,V> ceilingEntry(K key) { 207 return exportEntry(subCeiling(key)); 208 } 209 210 // 获取“大于/等于key的最小键” 211 public final K ceilingKey(K key) { 212 return keyOrNull(subCeiling(key)); 213 } 214 215 // 获取“大于key的最小键值对” 216 public final Map.Entry<K,V> higherEntry(K key) { 217 return exportEntry(subHigher(key)); 218 } 219 220 // 获取“大于key的最小键” 221 public final K higherKey(K key) { 222 return keyOrNull(subHigher(key)); 223 } 224 225 // 获取“小于/等于key的最大键值对” 226 public final Map.Entry<K,V> floorEntry(K key) { 227 return exportEntry(subFloor(key)); 228 } 229 230 // 获取“小于/等于key的最大键” 231 public final K floorKey(K key) { 232 return keyOrNull(subFloor(key)); 233 } 234 235 // 获取“小于key的最大键值对” 236 public final Map.Entry<K,V> lowerEntry(K key) { 237 return exportEntry(subLower(key)); 238 } 239 240 // 获取“小于key的最大键” 241 public final K lowerKey(K key) { 242 return keyOrNull(subLower(key)); 243 } 244 245 // 获取"SubMap的第一个键" 246 public final K firstKey() { 247 return key(subLowest()); 248 } 249 250 // 获取"SubMap的最后一个键" 251 public final K lastKey() { 252 return key(subHighest()); 253 } 254 255 // 获取"SubMap的第一个键值对" 256 public final Map.Entry<K,V> firstEntry() { 257 return exportEntry(subLowest()); 258 } 259 260 // 获取"SubMap的最后一个键值对" 261 public final Map.Entry<K,V> lastEntry() { 262 return exportEntry(subHighest()); 263 } 264 265 // 返回"SubMap的第一个键值对",并从SubMap中删除改键值对 266 public final Map.Entry<K,V> pollFirstEntry() { 267 TreeMap.Entry<K,V> e = subLowest(); 268 Map.Entry<K,V> result = exportEntry(e); 269 if (e != null) 270 m.deleteEntry(e); 271 return result; 272 } 273 274 // 返回"SubMap的最后一个键值对",并从SubMap中删除改键值对 275 public final Map.Entry<K,V> pollLastEntry() { 276 TreeMap.Entry<K,V> e = subHighest(); 277 Map.Entry<K,V> result = exportEntry(e); 278 if (e != null) 279 m.deleteEntry(e); 280 return result; 281 } 282 283 // Views 284 transient NavigableMap<K,V> descendingMapView = null; 285 transient EntrySetView entrySetView = null; 286 transient KeySet<K> navigableKeySetView = null; 287 288 // 返回NavigableSet对象,实际上返回的是当前对象的"Key集合"。 289 public final NavigableSet<K> navigableKeySet() { 290 KeySet<K> nksv = navigableKeySetView; 291 return (nksv != null) ? nksv : 292 (navigableKeySetView = new TreeMap.KeySet(this)); 293 } 294 295 // 返回"Key集合"对象 296 public final Set<K> keySet() { 297 return navigableKeySet(); 298 } 299 300 // 返回“逆序”的Key集合 301 public NavigableSet<K> descendingKeySet() { 302 return descendingMap().navigableKeySet(); 303 } 304 305 // 排列fromKey(包含) 到 toKey(不包含) 的子map 306 public final SortedMap<K,V> subMap(K fromKey, K toKey) { 307 return subMap(fromKey, true, toKey, false); 308 } 309 310 // 返回当前Map的头部(从第一个节点 到 toKey, 不包括toKey) 311 public final SortedMap<K,V> headMap(K toKey) { 312 return headMap(toKey, false); 313 } 314 315 // 返回当前Map的尾部[从 fromKey(包括fromKeyKey) 到 最后一个节点] 316 public final SortedMap<K,V> tailMap(K fromKey) { 317 return tailMap(fromKey, true); 318 } 319 320 // Map的Entry的集合 321 abstract class EntrySetView extends AbstractSet<Map.Entry<K,V>> { 322 private transient int size = -1, sizeModCount; 323 324 // 获取EntrySet的大小 325 public int size() { 326 // 若SubMap是从“开始节点”到“结尾节点”,则SubMap大小就是原TreeMap的大小 327 if (fromStart && toEnd) 328 return m.size(); 329 // 若SubMap不是从“开始节点”到“结尾节点”,则调用iterator()遍历EntrySetView中的元素 330 if (size == -1 || sizeModCount != m.modCount) { 331 sizeModCount = m.modCount; 332 size = 0; 333 Iterator i = iterator(); 334 while (i.hasNext()) { 335 size++; 336 i.next(); 337 } 338 } 339 return size; 340 } 341 342 // 判断EntrySetView是否为空 343 public boolean isEmpty() { 344 TreeMap.Entry<K,V> n = absLowest(); 345 return n == null || tooHigh(n.key); 346 } 347 348 // 判断EntrySetView是否包含Object 349 public boolean contains(Object o) { 350 if (!(o instanceof Map.Entry)) 351 return false; 352 Map.Entry<K,V> entry = (Map.Entry<K,V>) o; 353 K key = entry.getKey(); 354 if (!inRange(key)) 355 return false; 356 TreeMap.Entry node = m.getEntry(key); 357 return node != null && 358 valEquals(node.getValue(), entry.getValue()); 359 } 360 361 // 从EntrySetView中删除Object 362 public boolean remove(Object o) { 363 if (!(o instanceof Map.Entry)) 364 return false; 365 Map.Entry<K,V> entry = (Map.Entry<K,V>) o; 366 K key = entry.getKey(); 367 if (!inRange(key)) 368 return false; 369 TreeMap.Entry<K,V> node = m.getEntry(key); 370 if (node!=null && valEquals(node.getValue(),entry.getValue())){ 371 m.deleteEntry(node); 372 return true; 373 } 374 return false; 375 } 376 } 377 378 // SubMap的迭代器 379 abstract class SubMapIterator<T> implements Iterator<T> { 380 // 上一次被返回的Entry 381 TreeMap.Entry<K,V> lastReturned; 382 // 指向下一个Entry 383 TreeMap.Entry<K,V> next; 384 // “栅栏key”。根据SubMap是“升序”还是“降序”具有不同的意义 385 final K fenceKey; 386 int expectedModCount; 387 388 // 构造函数 389 SubMapIterator(TreeMap.Entry<K,V> first, 390 TreeMap.Entry<K,V> fence) { 391 // 每创建一个SubMapIterator时,保存修改次数 392 // 若后面发现expectedModCount和modCount不相等,则抛出ConcurrentModificationException异常。 393 // 这就是所说的fast-fail机制的原理! 394 expectedModCount = m.modCount; 395 lastReturned = null; 396 next = first; 397 fenceKey = fence == null ? null : fence.key; 398 } 399 400 // 是否存在下一个Entry 401 public final boolean hasNext() { 402 return next != null && next.key != fenceKey; 403 } 404 405 // 返回下一个Entry 406 final TreeMap.Entry<K,V> nextEntry() { 407 TreeMap.Entry<K,V> e = next; 408 if (e == null || e.key == fenceKey) 409 throw new NoSuchElementException(); 410 if (m.modCount != expectedModCount) 411 throw new ConcurrentModificationException(); 412 // next指向e的后继节点 413 next = successor(e); 414 lastReturned = e; 415 return e; 416 } 417 418 // 返回上一个Entry 419 final TreeMap.Entry<K,V> prevEntry() { 420 TreeMap.Entry<K,V> e = next; 421 if (e == null || e.key == fenceKey) 422 throw new NoSuchElementException(); 423 if (m.modCount != expectedModCount) 424 throw new ConcurrentModificationException(); 425 // next指向e的前继节点 426 next = predecessor(e); 427 lastReturned = e; 428 return e; 429 } 430 431 // 删除当前节点(用于“升序的SubMap”)。 432 // 删除之后,可以继续升序遍历;红黑树特性没变。 433 final void removeAscending() { 434 if (lastReturned == null) 435 throw new IllegalStateException(); 436 if (m.modCount != expectedModCount) 437 throw new ConcurrentModificationException(); 438 // 这里重点强调一下“为什么当lastReturned的左右孩子都不为空时,要将其赋值给next”。 439 // 目的是为了“删除lastReturned节点之后,next节点指向的仍然是下一个节点”。 440 // 根据“红黑树”的特性可知: 441 // 当被删除节点有两个儿子时。那么,首先把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。 442 // 这意味着“当被删除节点有两个儿子时,删除当前节点之后,'新的当前节点'实际上是‘原有的后继节点(即下一个节点)’”。 443 // 而此时next仍然指向"新的当前节点"。也就是说next是仍然是指向下一个节点;能继续遍历红黑树。 444 if (lastReturned.left != null && lastReturned.right != null) 445 next = lastReturned; 446 m.deleteEntry(lastReturned); 447 lastReturned = null; 448 expectedModCount = m.modCount; 449 } 450 451 // 删除当前节点(用于“降序的SubMap”)。 452 // 删除之后,可以继续降序遍历;红黑树特性没变。 453 final void removeDescending() { 454 if (lastReturned == null) 455 throw new IllegalStateException(); 456 if (m.modCount != expectedModCount) 457 throw new ConcurrentModificationException(); 458 m.deleteEntry(lastReturned); 459 lastReturned = null; 460 expectedModCount = m.modCount; 461 } 462 463 } 464 465 // SubMap的Entry迭代器,它只支持升序操作,继承于SubMapIterator 466 final class SubMapEntryIterator extends SubMapIterator<Map.Entry<K,V>> { 467 SubMapEntryIterator(TreeMap.Entry<K,V> first, 468 TreeMap.Entry<K,V> fence) { 469 super(first, fence); 470 } 471 // 获取下一个节点(升序) 472 public Map.Entry<K,V> next() { 473 return nextEntry(); 474 } 475 // 删除当前节点(升序) 476 public void remove() { 477 removeAscending(); 478 } 479 } 480 481 // SubMap的Key迭代器,它只支持升序操作,继承于SubMapIterator 482 final class SubMapKeyIterator extends SubMapIterator<K> { 483 SubMapKeyIterator(TreeMap.Entry<K,V> first, 484 TreeMap.Entry<K,V> fence) { 485 super(first, fence); 486 } 487 // 获取下一个节点(升序) 488 public K next() { 489 return nextEntry().key; 490 } 491 // 删除当前节点(升序) 492 public void remove() { 493 removeAscending(); 494 } 495 } 496 497 // 降序SubMap的Entry迭代器,它只支持降序操作,继承于SubMapIterator 498 final class DescendingSubMapEntryIterator extends SubMapIterator<Map.Entry<K,V>> { 499 DescendingSubMapEntryIterator(TreeMap.Entry<K,V> last, 500 TreeMap.Entry<K,V> fence) { 501 super(last, fence); 502 } 503 504 // 获取下一个节点(降序) 505 public Map.Entry<K,V> next() { 506 return prevEntry(); 507 } 508 // 删除当前节点(降序) 509 public void remove() { 510 removeDescending(); 511 } 512 } 513 514 // 降序SubMap的Key迭代器,它只支持降序操作,继承于SubMapIterator 515 final class DescendingSubMapKeyIterator extends SubMapIterator<K> { 516 DescendingSubMapKeyIterator(TreeMap.Entry<K,V> last, 517 TreeMap.Entry<K,V> fence) { 518 super(last, fence); 519 } 520 // 获取下一个节点(降序) 521 public K next() { 522 return prevEntry().key; 523 } 524 // 删除当前节点(降序) 525 public void remove() { 526 removeDescending(); 527 } 528 } 529 }
NavigableSubMap源码很多,但不难理解;读者可以通过源码和注释进行理解。
其实,读完NavigableSubMap的源码后,我们可以得出它的核心思想是:它是一个抽象集合类,为2个子类——"(升序)AscendingSubMap"和"(降序)DescendingSubMap"而服务;因为NavigableSubMap实现了许多公共API。它的最终目的是实现下面的一系列函数:
headMap(K toKey, boolean inclusive) headMap(K toKey) subMap(K fromKey, K toKey) subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) tailMap(K fromKey) tailMap(K fromKey, boolean inclusive) navigableKeySet() descendingKeySet()
参考:
1、红黑树系列集锦
3、红黑树
7、Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号