Spark Client启动原理探索
经过几天闲暇时间的学习,终于又理解的深入了一些,关于Spark Client如何提交作业也更清晰了点。
在整体的流程图上是这样的:
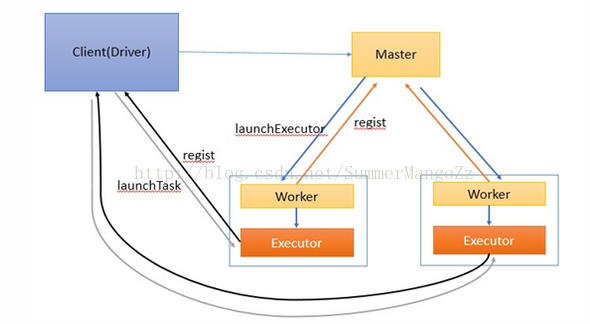
大体的思路就是应用程序通过SparkSubmit提交程序后,自动在当前的JVM中启动Driver,然后与Master通信创建Excutor执行相应的任务。
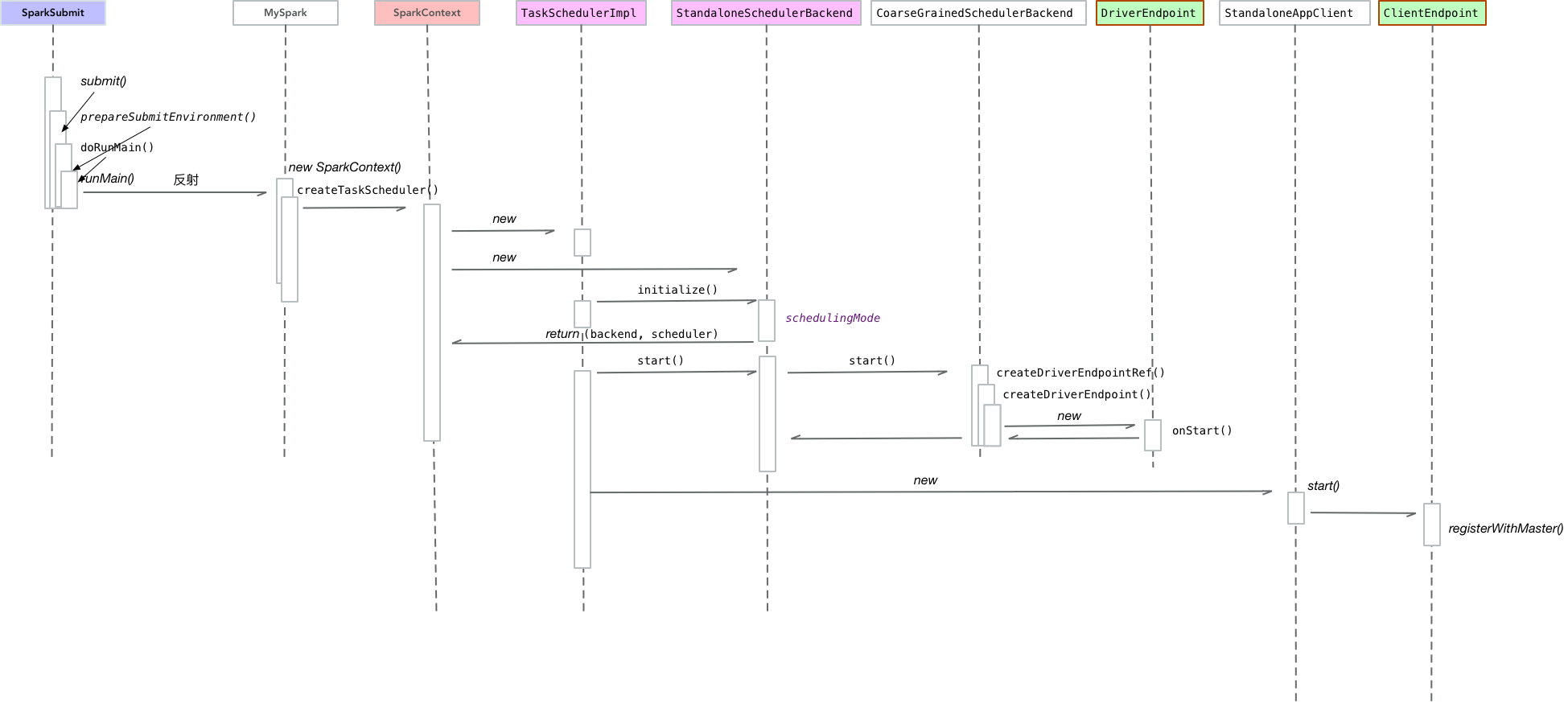
自己整理了下流程图
以及的组件图:
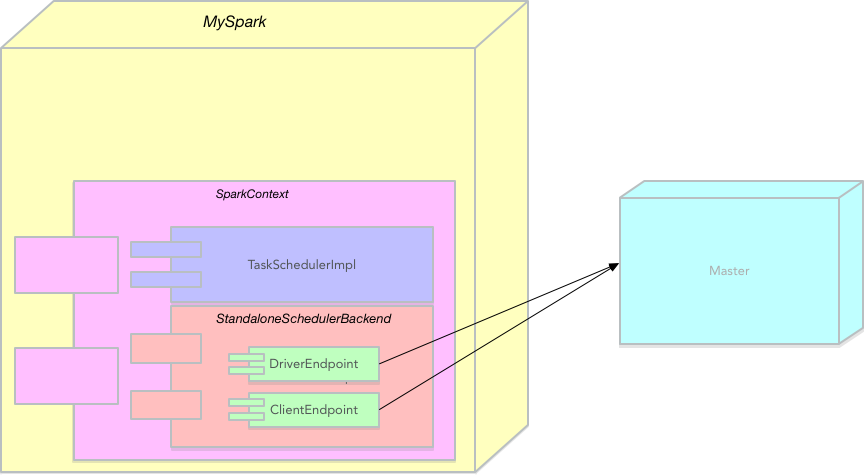
可以看到大概是下面的步骤:
- 新建SparkContext
- 创建对应的scheduler和schedulerBackend
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
...
_taskScheduler.start()
- 启动scheduler的start方法,内部调用backend的start方法
- backend调用父类
CoarseGrainedSchedulerBackend的start方法
override def start() {
super.start()
...
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
}
- 创建对应的drvierEndpoint
- 在backend的start()方法里面创建StandaloneAppClient
- 执行StanaloneAppClient对象的start方法,内部创建ClientEndpoint
DriverEndpoint和ClientEndpoint都会跟Master进行通信,接下来的处理就是编译驱动程序的代码,发送给excutor进行相应的处理。

