基于ELK的数据分析实践——满满的干货送给你
很多人刚刚接触ELK都不知道如何使用它们来做分析,经常会碰到下面的问题:
- 安装完ELK不知从哪下手
- 拿到数据样本不知道怎么分解数据
- 导入到elasticsearch中奇怪为什么搜不出来
- 搜到结果后,不知道它还能干什么
本篇就以一个完整的流程介绍下,数据从 读取-->分析-->检索-->应用 的全流程处理。在阅读本篇之前,需要先安装ELK,可以参考之前整理安装文档:ELK5.0部署教程
在利用ELK做数据分析时,大致为下面的流程:
- 1 基于logstash分解字段
- 2 基于字段创建Mapping
- 3 查看分词结果
- 4 检索
- 5 聚合
- 6 高亮
可能会根据第4步重复第2步的工作,调整分词等规则。
为了便于理解,先说一下本文的业务背景:
我需要统计一个url对应的pv和uv,这个url需要支持全文检索。每天同一个url都会产生一条数据。最后会按照特定的日期范围对数据进行聚合。
下面就开始数据分析之路吧~
基于logstash分解字段
在使用logstash前,需要对它有一定的了解。logstash的组件其实很简单,主要包括input、filter、output、codec四个部分。
- input 用于读取内容,常用的有stdin(直接从控制台输入)、file(读取文件)等,另外还提供了对接redis、kafka等的插件
- filter 用于对输入的文本进行处理,常用的有grok(基于正则表达式提取字段)、kv(解析键值对形式的数据)、csv、xml等,另外还提供了了一个ruby插件,这个插件如果会用的话,几乎是万能的。
- output 用于把fitler得到的内容输出到指定的接收端,常用的自然是elasticsearch(对接ES)、file(输出到文件)、stdout(直接输出到控制台)
- codec 它用于格式化对应的内容,可以再Input和output插件中使用,比如在output的stdout中使用rubydebug以json的形式输出到控制台
理解上面的内容后,再看看logstash的使用方法。
首先需要定义一个配置文件,配置文件中配置了对应的input,filter,output等,至少是一个input,output。
如我的配置文件:
input {
file {
path => "C:\Users\Documents\workspace\elk\page.csv"
start_position => "beginning"
}
}
filter {
grok {
match => {
"message" => "%{NOTSPACE:url}\s*%{NOTSPACE:date}\s*%{NOTSPACE:pvs}\s*%{NOTSPACE:uvs}\s*%{NOTSPACE:ips}\s*%{NOTSPACE:mems}\s*%{NOTSPACE:new_guests}\s*%{NOTSPACE:quits}\s*%{NOTSPACE:outs}\s*%{NOTSPACE:stay_time}"
}
}
}
output {
stdout{codec => dots}
elasticsearch {
document_type => "test"
index => "page"
hosts => ["1.1.1.1:9200"]
}
}
上面的配置最不容易理解的就是Grok,其实它就是个正则表达式而已,你可以把它理解成是一段正则表达式的占位。至于grok都有哪些关键字,这些关键字对应的正则都是什么,可以直接参考logstash的源码,目录的位置为:
logstash-5.2.2\vendor\bundle\jruby\1.9\gems\logstash-patterns-core-4.0.2\patterns
如果提供的话,可以直接在grokdebug上面进行测试:
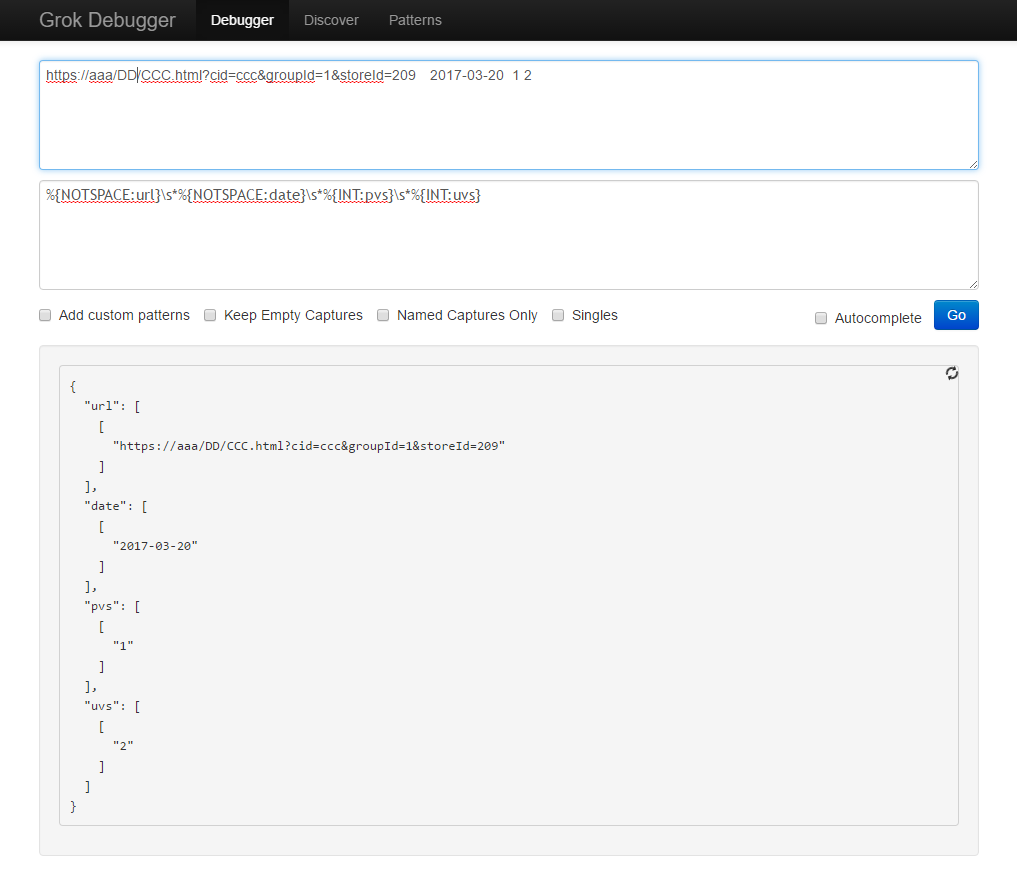
另外一个技巧就是,如果开启stdout并且codec为rubydebug,会把数据输出到控制台,因此使用.代替,即可省略输出,又能检测到现在是否有数据正在处理。而且每个.是一个字符,如果把它输出到文件,也可以直接通过文件的大小,判断处理了多少条。
这样,数据的预处理做完了.....
基于字段创建Mapping
虽然说Es是一个文档数据库,但是它也是有模式的概念的。文档中的每个字段仍然需要定义字段的类型,使用者经常会遇到明明是数字,在kibana却做不了加法;或者明明是IP,kibana里面却不认识。这都是因为Mapping有问题导致的。
在Elasticsearch中其实是有动态映射这个概念的,在字段第一次出现时,ES会自动检测你的字段是否属于数字或者日期或者IP,如果满足它预定义的格式,就按照特殊格式存储。一旦格式设置过了,之后的数据都会按照这种格式存储。举个例子,第一条数据进入ES时,字段检测为数值型;第二条进来的时候,却是一个字符串,结果可能插不进去,也可能插进去读不出来(不同版本处理的方式不同)。
因此,我们需要事先就设定一下字段的Mapping,这样之后使用的时候才不会困惑。
另外,Mapping里面不仅仅有字段的类型,还有这个字段的分词方式,比如使用标准standard分词器,还是中文分词器,或者是自定义的分词器,这个也是很关键的一个概念,稍后再讲。
创建Mapping有两种方式:
第一种,直接创建索引并创建映射
创建索引时,可以直接指定它的配置和Mapping:
PUT index_name
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"type_name" : {
"properties" : {
"field_name" : { "type" : "text" }
}
}
}
}
第二种,先创建索引,再创建映射
# 先创建索引
PUT index_name
{}
# 然后创建Mapping
PUT /index_name/_mapping/type_name
{
"properties": {
"ip": {
"type": "ip"
}
}
}
# 最后查询创建的Mapping
GET /index_name/_mapping/type_name
比如我们上面的URL场景,可以这么建立索引:
PUT url/_mapping/test
{
"properties": {
"url": {
"type": "string",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"date": {
"type": "date"
},
"pvs": {
"type": "integer"
},
"uvs": {
"type": "integer"
}
}
}
PS,在上面的例子中,url需要有两个用途,一个是作为聚合的字段;另一个是需要做全文检索。在ES中全文检索的字段是不能用来做聚合的,因此使用嵌套字段的方式,新增一个url.keyword字段,这个字段设置成keyword类型,不采用任何分词(这是5.0的新特性,如果使用以前版本,可以直接设置string对应的index属性即可);然后本身的url字段则采用默认的标准分词器进行分词。
这样,以后在搜索的时候可以直接以query string的方式检索url,聚合的时候则可以直接使用url.keyword
查看分词结果
如果字段为https://www.elastic.co/guide/en/elasticsearch/reference/5.2,使用standard标准分词器,输入elastic却收不到任何结果,是不是有点怀疑人生。
我们做个小例子,首先创建一个空的索引:
PUT test1/test1/1
{
"text":"https://www.elastic.co/guide/en/elasticsearch/reference/5.2"
}
然后查询这个字段被分解成了什么鬼?
GET /test1/test1/1/_termvectors?fields=text
得到的内容如下:
{
"_index": "test1",
"_type": "test1",
"_id": "1",
"_version": 1,
"found": true,
"took": 1,
"term_vectors": {
"text": {
"field_statistics": {
"sum_doc_freq": 7,
"doc_count": 1,
"sum_ttf": 7
},
"terms": {
"5.2": {
"term_freq": 1,
"tokens": [
{
"position": 6,
"start_offset": 56,
"end_offset": 59
}
]
},
"elasticsearch": {
"term_freq": 1,
"tokens": [
{
"position": 4,
"start_offset": 32,
"end_offset": 45
}
]
},
"en": {
"term_freq": 1,
"tokens": [
{
"position": 3,
"start_offset": 29,
"end_offset": 31
}
]
},
"guide": {
"term_freq": 1,
"tokens": [
{
"position": 2,
"start_offset": 23,
"end_offset": 28
}
]
},
"https": {
"term_freq": 1,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 5
}
]
},
"reference": {
"term_freq": 1,
"tokens": [
{
"position": 5,
"start_offset": 46,
"end_offset": 55
}
]
},
"www.elastic.co": {
"term_freq": 1,
"tokens": [
{
"position": 1,
"start_offset": 8,
"end_offset": 22
}
]
}
}
}
}
}
看到了吧,没有elastic这个词,自然是搜不出来的。如果你不理解这句话,回头看看倒排索引的原理吧!或者看看我的这篇文章:分词器的作用
那么你可能很郁闷,我就是要搜elastic怎么办!没关系,换个分词器就行了~比如elasticsearch为我们提供的simple分词器,就可以简单的按照符号进行切分:
POST _analyze
{
"analyzer": "simple",
"text": "https://www.elastic.co/guide/en/elasticsearch/reference/5.2"
}
得到的结果为:
{
"tokens": [
{
"token": "https",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 0
},
{
"token": "www",
"start_offset": 8,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "elastic",
"start_offset": 12,
"end_offset": 19,
"type": "word",
"position": 2
},
{
"token": "co",
"start_offset": 20,
"end_offset": 22,
"type": "word",
"position": 3
},
{
"token": "guide",
"start_offset": 23,
"end_offset": 28,
"type": "word",
"position": 4
},
{
"token": "en",
"start_offset": 29,
"end_offset": 31,
"type": "word",
"position": 5
},
{
"token": "elasticsearch",
"start_offset": 32,
"end_offset": 45,
"type": "word",
"position": 6
},
{
"token": "reference",
"start_offset": 46,
"end_offset": 55,
"type": "word",
"position": 7
}
]
}
这样你就可以搜索elastic了,但是前提是需要在Mapping里面为该字段指定使用simple分词器,方法为:
PUT url/_mapping/test
{
"properties": {
"url": {
"type": "string",
"analyzer": "simple",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"date": {
"type": "date"
},
"pvs": {
"type": "integer"
},
"uvs": {
"type": "integer"
}
}
修改Mapping前,需要先删除索引,然后重建索引。删除索引的命令为:
DELETE url
不想删除索引,只想改变Mapping?想得美....你当ES是孙悟空会72变?不过,你可以创建一个新的索引,然后把旧索引的数据导入到新索引就行了,这也不失为一种办法。如果想这么搞,可以参考reindex api,如果版本是5.0之前,那么你倒霉了!自己搞定吧!
检索
ES里面检索是一个最基础的功能了,很多人其实这个都是一知半解。由于内容太多,我就结合Kibana讲讲其中的一小部分吧。
很多人安装完kibana之后,登陆后不知道该干啥。如果你的elasticsearch里面已经有数据了,那么此时你需要在Kiban新建对应的索引。
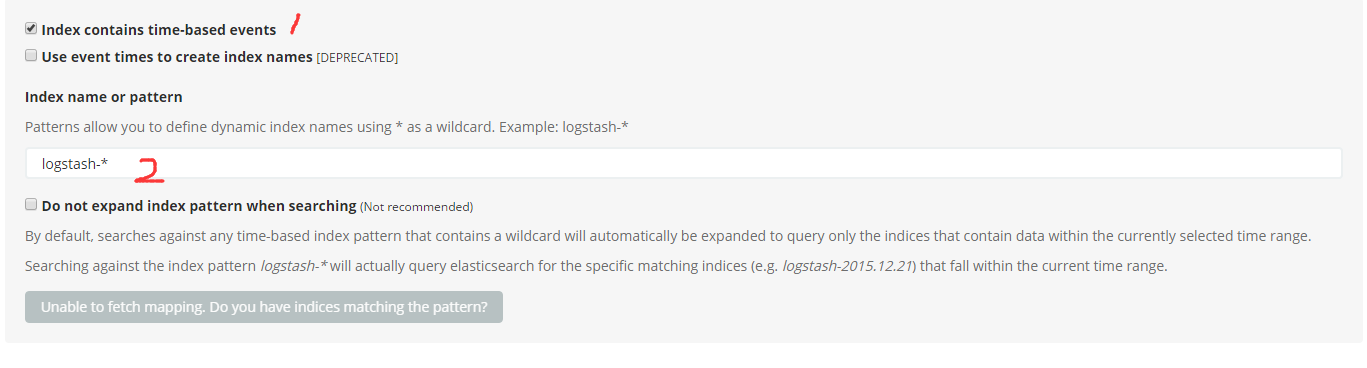
如果你的es的索引是name-2017-03-19,name-2017-03-20这种名字+时间后缀的,那么可以勾选1位置的选项,它会自动聚合这些索引。这样在这一个索引中就可以查询多个索引的数据了,其实他是利用了索引的模式匹配的特性。如果你的索引仅仅是一个简单的名字,那么可以不勾选1位置的选项,直接输入名字,即可。

然后进入Kibana的首页,在输入框里面就可以任意输入关键字进行查询了。
查询的词,需要是上面_termvectors分析出来的词,差一个字母都不行!!!!!
这个搜索框其实就是elasticsearch中的query string,因此所有的lucene查询语法都是支持的!
如果想要了解更多的查询语法,也可以参考我之前整理的文章,Lucene查询语法
另外,这个输入框,其实也可以输入ES的DSL查询语法,只不过写法过于蛋疼,就不推荐了。
自定义查询语法
如果不使用kibana,想在自己的程序里面访问es操作,也可以直接以rest api的方式查询。
比如查询某个索引的全部内容,默认返回10个:
GET /page/test/_search?pretty
再比如,增加一个特殊点的查询:
GET /page/test/_search?pretty
{
"query": {
"query_string" : {
"default_field" : "url",
"query" : "颜色"
}
},
"size": 10,
}
聚合
在es中一个很重要的亮点,就是支持很多的聚合语法,如果没有它,我想很多人会直接使用lucene吧。在ES中的聚合,大体上可以为两类聚合方法,metric和bucket。metic可以理解成avg、sum、count、max、min,bucket可以理解为group by 。有了这两种聚合方法,就可以对ES中的数据做很多处理了。
比如在kibana中,做一个最简单的饼图:
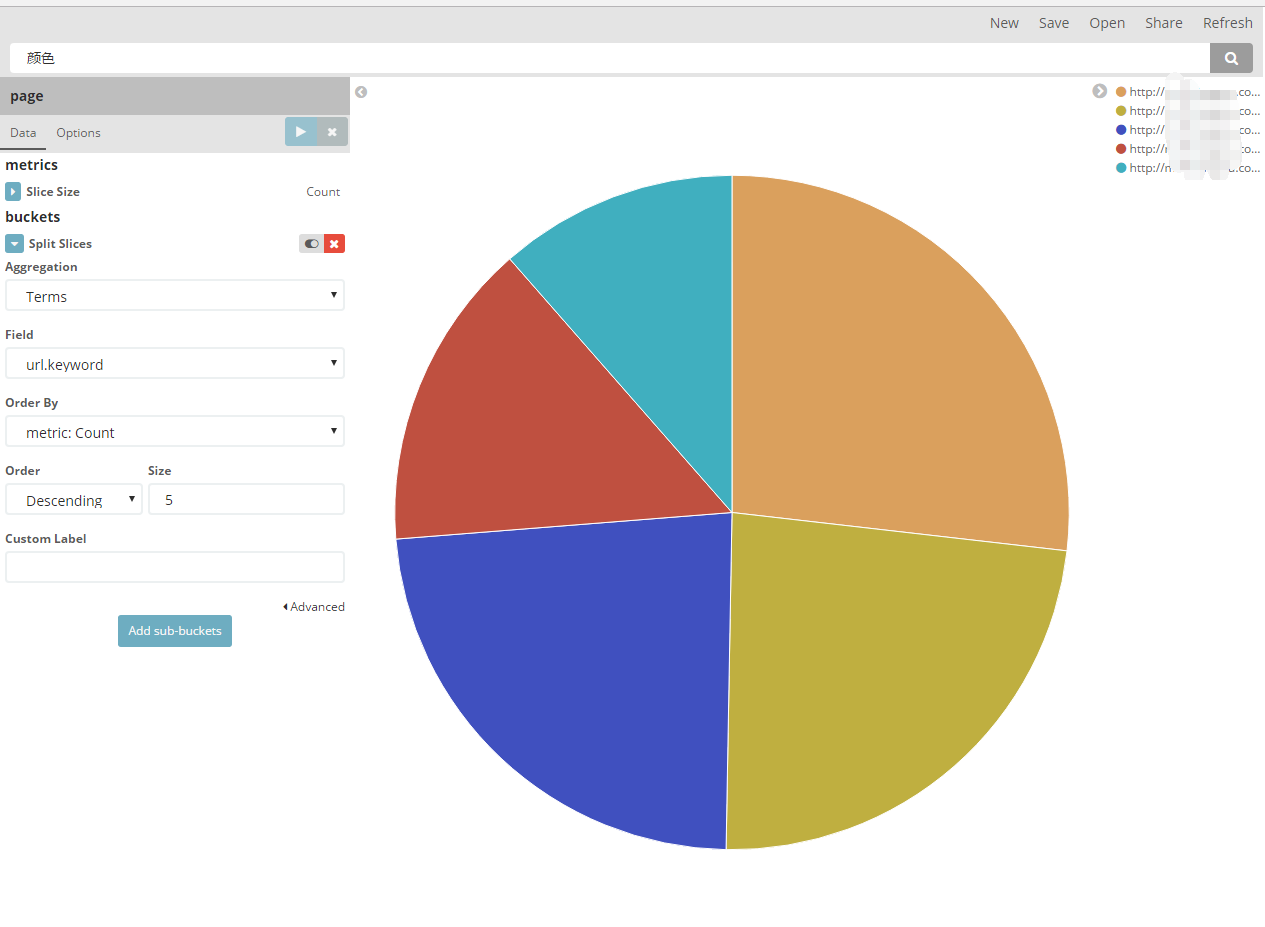
其实它在后台发送的请求,就是这个样子的:
{
"size": 0,
"query": {
"query_string": {
"query": "颜色",
"analyze_wildcard": true
}
},
"_source": {
"excludes": []
},
"aggs": {
"2": {
"terms": {
"field": "url.keyword",
"size": 5,
"order": {
"_count": "desc"
}
}
}
}
}
如果不适用kibana,自己定义聚合请求,那么可以这样写:
GET /page/test/_search?pretty
{
"query": {
"query_string" : {
"default_field" : "url",
"query" : "颜色"
}
},
"size": 0,
"aggs" : {
"agg1" : {
"terms" : {
"field" : "url.keyword",
"size" : 10
},
"aggs" : {
"pvs" : { "sum" : { "field" : "pvs" } },
"uvs" : { "sum" : { "field" : "uvs" } }
}
}
}
}
另外,聚合也支持嵌套聚合,就是跟terms或者sum等agg并列写一个新的aggs对象就行。
高亮
如果是自己使用elasticsearch,高亮也是一个非常重要的内容,它可以帮助最后的使用者快速了解搜索的结果。

后台的原理,是利用ES提供的highlight API,针对搜索的关键字,返回对应的字段。该字段中包含了一个自定义的标签,前端可以基于这个标签高亮着色。
举个简单的例子:
GET /_search
{
"query" : {
"match": { "content": "kimchy" }
},
"highlight" : {
"fields" : {
"content" : {}
}
}
}
上面的请求会针对content字段搜索kimchy。并且返回对应的字段,比如原来的字段内容时hello kimchy,经过高亮后,会再搜索结果的hits中返回:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 30,
"max_score": 13.945707,
"hits": [
{
"_index": "page",
"_type": "test",
"_id": "AVrvHh_kvobeDQC6Q5Sg",
"_score": 13.945707,
"_source": {
"date": "2016-03-14",
"pvs": "3",
"url": "hello kimchy",
"@timestamp": "2017-03-21T04:29:07.187Z",
"uvs": "1",
"@version": "1"
},
"highlight": {
"url": [
"hello <em>kimchy</em>"
]
}
}
]
}
}
这样就可以直接利用highlight中的字段做前端的显示了。
另外,上面的<em>标签可以自定义,比如:
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"pre_tags" : ["<tag1>"],
"post_tags" : ["</tag1>"],
"fields" : {
"_all" : {}
}
}
}
经过上面的一步一步的探索,你应该了解ELK的数据分析的流程与技巧了吧!如果有任何问题,也可以直接留言,可以再交流!
参考
- 1 创建Mapping
- 2 查询Mapping
- 3 动态Maping
- 4 创建索引
- 5 logstash file插件
- 6 logstash grok插件
- 7 logstash elasticsearch插件
- 8 grok调试插件

