
编程之基础:数据类型(一)
相关文章连接:
编程之基础:数据类型(一)
- 3.1 引用类型与值类型 41
- 3.1.1 内存分配 42
- 3.1.2 字节序 44
- 3.1.3 装箱与拆箱 45
- 3.2 对象相等判断 46
- 3.2.1 引用类型判等 46
- 3.2.2 简单值类型判等 47
- 3.2.3 复合值类型判等 47
- 3.3 赋值与复制 50
- 3.3.1 引用类型赋值 50
- 3.3.2 值类型赋值 51
- 3.3.3 传参 52
- 3.3.4 浅复制 55
- 3.3.5 深复制 57
- 3.4 对象的不可改变性 60
- 3.4.1 不可改变性定义 60
- 3.4.2 定义不可改变类型 61
- 3.5 本章回顾 63
- 3.6 本章思考 63
数据类型是编程的基础,每个程序员在使用一种平台开发程序时,首先得知道平台中有哪些数据类型,每种数据类型有哪些特点、又有着怎样的内存分配等。熟练掌握每种类型不仅有利于提高我们的开发效率,还能使我们开发出来的程序更加稳定、健全。.NET中的数据类型共分为两种:引用类型和值类型,它们无论在内存分配还是行为表现上,均有着非常大的差别。
3.1 引用类型与值类型
关于对引用类型和值类型的定义,听得最多的是:值类型分配在线程栈中,而引用类型分配在堆中。这个定义并不准确(因为值类型也可以分配在堆中,而引用类型在某种场合也可以分配在栈中),或者说太抽象,它只是从内存分配的角度来区分值类型和引用类型,而对于内存分配,我们开发者是很难直观地去辨别。如果从代码角度来讲,.NET中的值类型是指"派生自System.ValueType的类型",而引用类型则指.NET中排除值类型在外的所有其它类型。下图3-1显示了.NET中的类型布局:
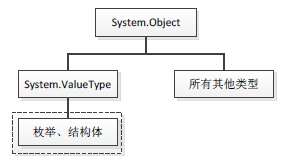
图3-1 类型布局
如上图3-1所示,派生自System.ValueType的类型属于值类型(图中虚线部分,不包括System.ValueType),所有其它类型均为引用类型(包括System.Object、System.ValueType)。在以System.Object为根的庞大"继承树"中圈出一部分(图中虚线框),那么该小部分就属于"值类型"。
注:以上对值类型和引用类型的解释似乎有些难以理解,为什么"根"是引用类型,而某些"枝叶"却是值类型?这是因为.NET内部对派生自System.ValueType的类型做了些"手脚"(这些对我们来讲是不可见的),使其跟其它类型(引用类型)具备不一样的特性。另外,.NET中还有一些引用类型并不继承自System.Object类,比如使用interface关键字定义的接口,它根本不在"继承树"的范围之类,这样看来,像我们平时听见的"所有类型均派生自System.Object类型"的话似乎也不太准确,这些隐藏的不可告人的秘密都是.NET内部做的一些处理,大部分并没有遵守主流规律。
通常值类型又分为两部分:
1)简单值类型:包括类似int、bool、long等.NET内置类型,它们本质上也是一种结构体;
2)复合值类型:使用Struct关键字定义的结构体,如System.Drawing.Point等。复合值类型可以由简单值类型和引用类型组成,下面定义一个复合值类型:
1 //Code 3-1 2 3 struct MultipleValType 4 { 5 int a; //NO.1 6 object c; //NO.2 7 }
如上代码Code 3-1所示,MultipleValType类型包含两个成员,一个简单值类型(NO.1处),一个引用类型(NO.2处)。
值类型均默认派生自System.ValueType,又由于.NET不允许多继承,因此我们既不可以在代码中显示定义一个派生自System.ValueType的结构体,同时也不可以让某个结构体继承自其它结构体。
引用类型和值类型各有自己的特性,这具体表现在内存分配、类型赋值(复制)、类型判等几个方面。
3.1.1 内存分配
本节开头就谈到,引用类型对象与值类型对象在内存中的存储方式不相同,使用new关键字创建的引用类型对象存储在(托管)堆中,而使用new关键字创建的值类型对象则分配在当前线程栈中。
注:堆和栈的具体概念请参见本书后面讲"对象生命期"的第四章。另外,使用类似"int a = 0;"这种方式定义的简单值类型变量,跟使用new关键字"Int32 a = new Int32();"效果一样。
下面代码显示创建一个引用类型对象和一个值类型对象:

1 //Code 3-2 2 3 class Ref //NO.1 4 { 5 int a; 6 Ref ref; 7 public Ref(int a,Ref ref) 8 { 9 this.a = a; 10 this.ref = ref; 11 } 12 } 13 struct Val1 //NO.2 14 { 15 int a; 16 bool b; 17 public Val1(int a,bool b) 18 { 19 this.a = a; 20 this.b =b; 21 } 22 } 23 struct Val2 //NO.3 24 { 25 int a; 26 Ref ref; 27 public Val2(int a,Ref ref) 28 { 29 this.a = a; 30 this.ref = ref; 31 } 32 } 33 class Program 34 { 35 static void Main() 36 { 37 Ref r = new Ref(0,new Ref(1,null)); //NO.4 38 Val1 v1 = new Val1(2,true); //NO.5 39 Val2 v2 = new Val2(3,r); //NO.6 40 } 41 }
如上代码Code 3-2所示,先定义了一个引用类型Ref(NO.1处),它包含一个值类型和一个引用类型成员;然后定义了两个值类型(NO.2和NO.3处),前者只包含两个简单值类型成员(int和bool类型),后者包含一个简单值类型和一个引用类型成员;最后分别各自创建一个对象(NO.4、NO.5以及NO.6处)。创建的三个对象在堆和栈中存储情况见下图3-2:
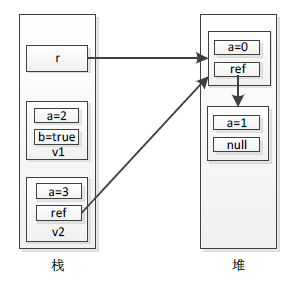
图3-2 堆和栈中数据存储情况
如上图3-2所示,值类型对象v1和v2均存放在栈中,而引用类型对象均存放在堆中。
通常程序运行过程中,线程会读写各自对应的栈(因此有时候我们称"线程栈"),也就是说,"栈"才是程序进行读写数据的地方,那么程序怎么访问存放在堆中的数据(对象)呢?这就需要在栈中保存一个对堆中对象的引用(索引),程序就可以通过该引用访问到存放在堆中的对象。
注:引用类型对象一般分为两部分:对象引用和对象实例,对象引用存放在栈中,程序使用该引用访问堆中的对象实例;对象实例存放在堆中,里面包含对象的数据内容,有关它们更详细介绍,请参见本书后面有关"对象生命期"的第四章。
3.1.2 字节序
我们知道,内存可以看作是一块具有连续编号的存储空间,编号有大有小,所以有高地址和低地址之分。如果以字节为单元进行编号,那么一块内存可以用下图3-3表示:
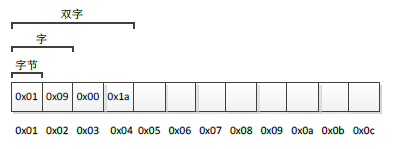
图3-3 内存结构
如上图3-3所示,从左往右,地址编号依次增大,左侧称为"低地址",右侧称为"高地址"。编号为0x01字节中存储数值为0x01,编号为0x02字节中存储数值为0x09,编号为0x03字节中存储数值为0x00,编号为0x04字节中存储数值为0x1a,每个字节中均可存放一个0~255之间的数值。那么这时候,如果我问你,图3-3中最左侧四个字节表示的一个int型整数为多少?你可能会这样去计算:0x01*2的24次方+0x09*2的16次方+0x00*2的8次方+0x1a*2的0次方,然后这样解释:高位字节在左边,低位字节在右边,将这样的一个二进制数转换成十进制数当然是这样计算。事实上,这种计算方法不一定正确,因为没有人告诉你高位字节一定在左边(低地址),而低位字节一定在右边(高地址)。
当占用超过一个字节的数值存放在内存中时,字节之间必然会有一个排列顺序,我们称之为"字节序",这种顺序会因不同的硬件平台而不同。高位字节存放在低地址,而低位字节存放在高地址(如刚才那样),我们称之为"Big-Endian";相反,高位字节存放在高地址,而低位字节存放在低地址,我们称之为"Little-Endian"。在使用高级语言编程的今天,我们大部分时间不用去在意"字节序"的差别,因为这些都有系统底层支撑模块帮我们判断完成。
.NET中的值类型对象和引用类型对象在内存中同样遵循"字节序"的规律,如下面一段代码:
1 //Code 3-3 2 3 class Program 4 { 5 static void Main() 6 { 7 int a = 0x1a09; 8 int b = 0x2e22; 9 int c = b; 10 } 11 }
如上代码Code 3-3所示,变量a、b、c在栈中存储结构如下图3-4:
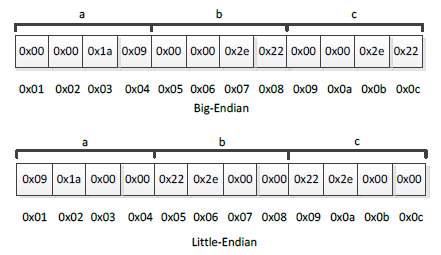
图3-4 整型变量在栈中的存储结构
如上图3-4所示,图中右边为栈底(注意这里,通常情况下,栈底位于高地址,栈顶位于低地址)。依次将c、b和a压入栈,图中上部分为按"Big-Endian"的字节序存放数据,而图中下部分为按"Little-Endian"字节序存放数据。
3.1.3 装箱与拆箱
前面讲到,new出来的值类型对象存放在栈中,new出来的引用类型对象存放在堆中(栈中有引用指向堆中的实例)。如果我们把栈中的值类型转存到堆中,然后通过一个引用访问它,那么这种操作叫"装箱";相反,如果我们把装箱后在堆中的值类型转存到栈中,那么就叫"拆箱"。下面代码Code 3-4表示装箱和拆箱操作:
1 //Code 3-4 2 3 class Program 4 { 5 static void Main() 6 { 7 int a = 1; //NO.1 8 object b = a; //NO.2 9 int c = (int)b; //NO.3 10 } 11 }
如上代码Code 3-4所示,NO.1定义一个整型变量a,它存放在栈中,NO.2处进行装箱操作,将栈中的a的值复制一份到堆中,并且使用b引用指向它,NO.3处将装箱后堆中的值复制一份到栈中,整个过程栈和堆中的变化情况见下图3-5:
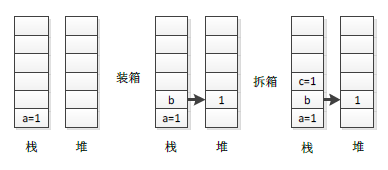
图3-5 装/拆箱栈和堆中变化过程
如上图3-5所示,装箱时将栈中值复制到堆中,拆箱时再将堆中的值复制到栈中。
使用时间短、主要是为了存储数据的类型应该定义为值类型,存放在栈中,随着线程中方法的调用完成,栈中的数据会不停地自动清理出栈,再加上栈一般情况下容量都比较有限,因此,建议类型设计的时候,值类型不要过大,而把那种体积大、程序需要长时间使用的类型定义为引用类型,存放在堆中,交给GC统一管理。同时,拆装箱涉及到频繁的数据移动,影响程序性能,应尽量避免频繁的拆装箱操作发生。
注:图3-5中栈的存储是连续的,而堆中存储可以是随机的,具体原因参见本书后续有关"对象生命期"的第四章。
3.2 对象相等判断
在面向对象的世界里,随处充满着"对象"的影子,那么怎么去判断对象的相等性呢?所谓相等,指具有相同的组成、属性、表现行为等,两个对象相等并不一定要求相同。.NET对象的相等性判断主要包括以下三个方面:
3.2.1 引用类型判等
引用类型分配在堆中,栈中只存放对堆中实例的一个引用,程序只能通过该引用才能访问到堆中的对象实例。对引用类型来讲,只有栈中的两个引用指向堆中的同一个实例时,才能说这两个对象相等(其实是同一个对象),其余任何时候,对象都不相等,就算两个对象中包含的数据一模一样。用图3-6表示为:
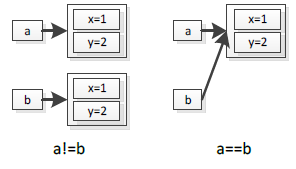
图3-6 引用类型判等
如上图3-6所示,左边的a和b分别指向堆中不同的对象实例,虽然实例中包含相同的内容,但是它两不相等;右边的a和b指向堆中同一个实例,因此它们相等。
可以看出,对于引用类型来讲,判断两个对象是否相等很简单,直接判断两个对象引用是否指向堆中同一个实例,若是,则相等;其余任何情况都不相等。
注:熟悉C/C++中指针的读者应该很清楚,两个不同的整型变量a和b,虽然a的值和b的值相等(比如都为1),但是它们两的地址肯定不相等(参见前面讲到的"字节序")。.NET中引用类型判等其实就是比较对象在堆中的地址,不同的对象地址肯定不相等(就算内容相等)。另外,.NET中的String类型是一种特殊的引用类型,它不遵守引用类型的判等标准,只要两个String包含相同的字符串,那么就相等,String类型判等更符合值类型的判等标准。
3.2.2 简单值类型判等
简单值类型包括.NET内置类型,比如int、bool、long等,这一类的比较准则跟现实中所说到的"相等"概念相似,只要两者的值相等,那么两者就相等,见如下代码:
1 //Code 3-5 2 3 class Program 4 { 5 static void Main() 6 { 7 int a = 10; 8 int b = 11; 9 int c = 10; 10 } 11 }
如上代码Code 3-5所示,a和c相等,与b不相等。为了与引用类型判等进行区分,见下图3-7:

图3-7 简单值类型在栈中的存储情况
如上图3-7所示,假设按照"Big-Endian"的字节序排列,右边是栈底,程序依次将c、b以及a压入栈。我们可以看到,如果比较a和c的内容,"a==c"成立;但是如果比较a和c的地址,很明显,a的(起始)地址为0x01,而c的(起始)地址为0x09,它两的地址不相等。
简单值类型的比较只关注两者包含的内容,而不去关心两者的地址,只要它们的内容相等,那么它们就相等。复合值类型也是比较两者包含的内容,只是复合值类型可能包含多个成员,需要挨个成员进行一一比较,详见下一小节。
注:虽然笔者很不想在.NET的书籍中提到有关指针(地址)的话题,但是为了说明"引用类型判等"的标准与"值类型判等"的标准有何区别,还是稍微提到了指针。我们可以很容易对比发现,引用类型判等其实就是比较对象在堆中的地址,而对象在堆中的地址就是由栈中的引用来表示的,地址不同,栈中引用的值肯定不相等,把栈中引用想象成一个存储堆中地址的变量,完全可以用简单值类型的判等标准去判断引用是否相等。
3.2.3 复合值类型判等
前面讲过,复合值类型由简单值类型、引用类型组成。既然也是值类型的一种,那么它的判等标准和简单值类型一样,只要两个对象包含的内容依次相等,那么它们就相等。下面代码Code 3-6定义了两种复合值类型,一种只由简单值类型组成,一种由简单值类型和引用类型组成:
1 //Code 3-6 2 3 struct MultipleValType1 //NO.1 4 { 5 int _a; 6 int _b; 7 public MultipleValType1(int a,int b) 8 { 9 _a = a; 10 _b = b; 11 } 12 } 13 struct MultipleValType2 //NO.2 14 { 15 int _a; 16 int[] _ref; 17 public MultipleValType2(int a,int[] ref) 18 { 19 _a = a; 20 _ref = ref; 21 } 22 } 23 class Program 24 { 25 static void Main() 26 { 27 MultipleValType1 mvt1 = new MultipleValType1(1,2); //NO.3 28 29 MultipleValType1 mvt2 = new MultipleValType1(1,2); //NO.4 30 // mvt1 equals mvt2 return true; 31 MultipleValType2 mvt3 = new MultipleValType2(2,new int[]{1,2,3}); //NO.5 32 MultipleValType2 mvt4 = new MultipleValType2(2,new int[]{1,2,3}); //NO.6 33 //mvt3 equals mvt4 retturn false; 34 } 35 }
如上代码Code 3-6所示,创建两个复合值类型,一个只包含简单值类型成员(NO.1处),另一个包含简单值类型成员和引用类型成员(NO.2处),最后创建了两对对象mvt1和mvt2(NO.3和NO.4处)、mvt3和mvt4(NO.5和NO.6处),它们都存放在栈中。mvt1和mvt2相等,因为它两包含相等的成员(_a都等于1,_b都等于2),相反,mvt3和mvt4却不相等,虽然看起来它两初始化是一样的(_a都等于1,_ref都指向堆中一个int[]数组,并且数组中的值也相等),原因很简单,按照前面关于"引用类型判等"的标准,mvt3中的_ref和mvt4中的_ref根本就不是指向堆中同一个对象实例(即mvt3._ref!=mvt4._ref)。为了更好地理解这其中的区别,请见下图3-8:
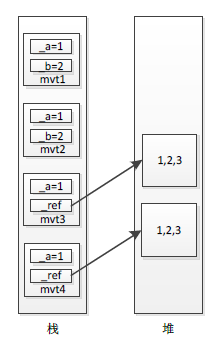
图3-8 复合值类型内存分配
如上图3-8所示,创建的4个对象均存放在栈中,mvt1和mvt2包含相等的成员,因此它两相等,但是mvt3和mvt4包含的引用类型成员_ref并不相等,它们指向堆中不同的对象实例,因此mvt3和mvt4不相等。
对于值类型而言,判断对象是否相等需要按以下几个步骤:
(1)若是简单值类型,则直接比较两者内容,如int、bool等;
(2)若是复合值类型,则遍历对应成员:
1)若成员是简单值类型,则按照"简单值类型判等"的标准进行比较;
2)若成员是引用类型,则按照"引用类型判等"的标准进行比较;
3)若成员是复合值类型,则递归判断。
值类型判等是一个"递归"的过程,只要递归过程中有一次比较不相等,那么整个对象就不相等。详见下图3-9:
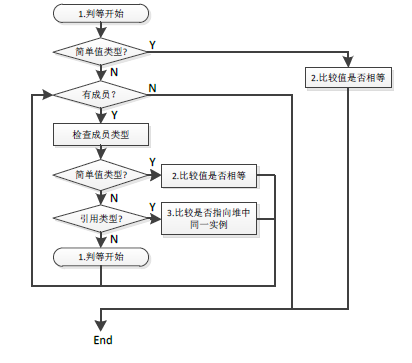
图3-9 值类型判等流程
(本章未完)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人