Python 文件编码问题解决
最近使用python操作文件,经常遇到编码错误的问题,例如:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbe in position 350: in
我看百度的解决方法就是手动指定编码方式,类似于以下这种方式:
encoding="UTF-8"
虽然这种类似的方法也能解决。但是这种方法只能靠运气去碰,如果刚好碰到文件编码和你指定的编码一致,那么就不会报错了。这种方式在尝试的过程就会很麻烦。
这里就有一个解决的小技巧,我们用Sublime这类的软件打开要操作的文件,就会在左下角看见文件到底是个什么编码格式。例如:
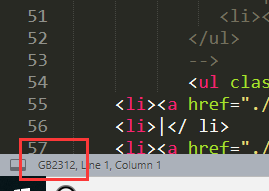
这样我们就找到文件具体的格式了。然后就通过百度找到指定编码格式的代码就可以解决编码问题。那么可以猜想这是不是一种通用的解决编码问题的方法呢?
本文来自博客园,作者:|旧市拾荒|,转载请注明原文链接:https://www.cnblogs.com/xiaoyh/p/11214046.html
