

js之正则表达式(上)
1、正则表达式的创建方式
两种方式创建:通过new修饰符创建和字面量的方式创建
1》new修饰符方式创建
1 var b2=new RegExp('Box','ig'); //第二个参数是 模式字符串: 用来限定 匹配的方式 2 // g :全局匹配 i:忽略大小写的匹配 m :多行匹配
2》字面量的方式创建
1 var d= /Box/i; // //之间的是 参数字符串;;第二个/ 后面的是 模式字符串
2、js中正则表达式的测试方式
两种测试方式:test()方法:检测字符串中是否“含有”对应的模式字符串,返回值是true和false;
exec()方法:检测字符串中是否“含有”对应的模式字符串,返回值是匹配到的字符串的数组,如果没有就返回null(返回值类型:object)
1 var d= /Box/i; //忽略大小写的匹配 2 alert(d.test('box')); //true 3 4 alert(/Box/i.test('this is a box')); //true : 匹配字符串中是否 “含有” 匹配字符串 5 6 alert(d.exec('box')); //box 7 8 alert( typeof d.exec('s')); //object
3、String类方法中使用的正则表达式
String类的match()、search()、replace()、split()
1》match()字符串的匹配方法,返回匹配到的数组
1 var pattern=/Box/gi; //全局匹配 不区分大小写 2 var b ='This is a box!It is a small box'; 3 alert(b.match(pattern)); //返回 的是 匹配到的数组 (box,box) 4 //如果不是全局匹配,,那么 只会 匹配第一个 ,返回的数组 只会含有一个 元素 5 pattern =/Box/i; 6 alert(b.match(pattern)); //box
2》search()返回第一个匹配到的字符串索引位置 ,g(全局匹配)在这里不起作用,如果没有匹配到就返回-1
alert(b.search(pattern)); //10
3》replace():找到要被匹配的字符串,然后用指定的字符串进行替换;返回值:返回替换后的字符串
1 alert(b.replace(pattern,'shit')); //返回 替换后的 字符串
注意:如果不是全局匹配的换,只有第一个匹配到的字符串被替换
4》split()按照指定的 “匹配符” 进行分割
1 alert(b.split(pattern)); // This is a ,!It is a small ,
正则表达式的静态方法和实例方法在这里就不做介绍,因为不常用,所以用的时候在查。
4、获取和控制(*重点)
1》单个字符和数字的匹配
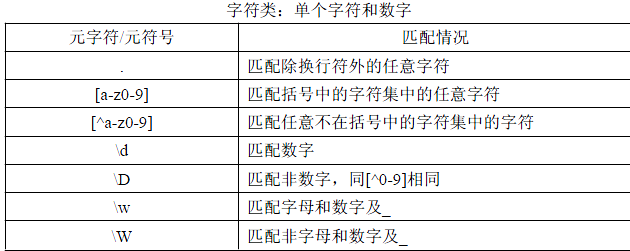
下面通过代码进行演示其使用的方式
1 var pattern =/[a-z]oogle/; //[a-z] 表示 小写字母中的 任意一个 2 alert(pattern.test("google")); //true 3 4 //下面一定要注意(****) 5 var pattern =/[A-Z]oogle/; //匹配的时候 是 匹配 字符串中是否含有 “匹配的字符串” 6 alert(pattern.test('aaaaaaGGGGoogleaaaa')); //true 7 8 alert(/[0-9]aaaa/.test("444aaaa")); //true
还可以进行“复合”匹配
1 var pattern3=/[a-zA-Z0-9]/; //匹配的 a-z和A-Z和0-9都可以 类似于"/w" 2 3 var pattern4=/[^a-z]oogle/; //[^a-z] 代表的就是 非 a-z 的字符
2》空白字符的匹配
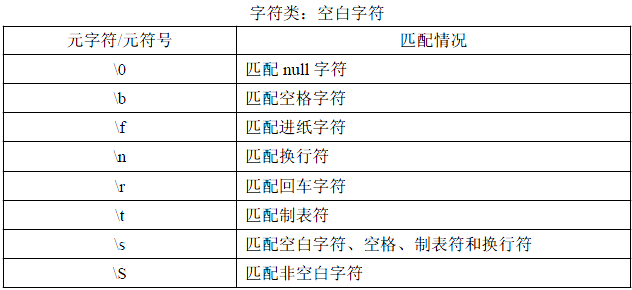
代码演示:
1 //空格字符的匹配 \s 2 var pattern =/goo\sgle/; 3 var str='goo gle'; 4 5 alert(pattern.test(str)); //true
3》锚字符的匹配
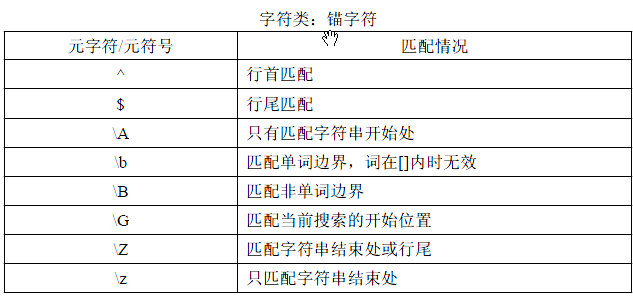
主要是对匹配的控制
代码演示:
1 var pattern ='/^[0-9]oogle/' //^ 位于 匹配字符串的 开头 代表 匹配字符串的 匹配是 从 字符串的 开头开始的 2 alert(pattern.test("4444oogle"));//false 因为是 从 最前面的 那个 4 进行匹配的 3 4 alert(/^[0-9]+oogle/.test("4444oogle")); //true + 代表是 1个 或 多个 5 6 //全局控制 7 var pattern2=/^\woogle$/; //^讲开头控制住,,$将结尾控制住,,所以 就是全局控制,,,\w 代表 匹配 数字字母和_
\b:行尾匹配
1 var pattern2 =/google\b/; //\b 代表是否到达结尾;;;就是e 是否是 最后一个字符 2 var str2='googleeeee'; 3 4 alert(pattern2.test(str2)); //false 5 alert(pattern2.test('google')); //true
5》重复匹配
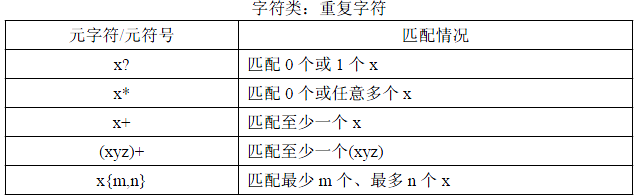
代码演示:
1 var pattern =/go{3}gle/; //限定 o 为三个 2 var pattern2=/go{2,4}gle/; //限定 o 为2 到4 个 3 var pattern3=/go{3,}gle/; //限定o为 3个 或者 3个以上 4 5 var d='google'; 6 alert(pattern.test(d)); //false 7 alert(pattern2.test('goooogle')); //true 8 alert(pattern3.test('gooooogle')); //true
6》替代匹配

代码演示:
1 var pattern =/box|\w+oogle/; //字符串匹配到 'box' 或者 '\w+oogle'都会返回 true 2 alert(pattern.test('box')); //true 3 alert(pattern.test('shigggoogle')); //true
7》分组匹配
记录字符:
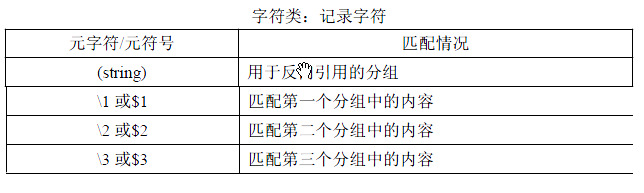
使用RegExp的静态属性 $1 获得 是分组中的内容。
()分组匹配演示:
1 var pattern3 =/google{4,8}$/; //代表 匹配 e字符 4到 8 次 2 var str3='googleeeee'; 3 4 alert(pattern3.test(str3)); //true 5 6 var pattern4=/(google){4,8}/; //表示 匹配 google 4到 8 次 7 alert(pattern4.test('googlegooglegooglegoogle'));//true
$1:取到匹配到的第一个分组的字符串(难点):
1 var pattern =/8(.*)8/; 2 var str='This is a 8google8'; 3 //只要匹配 一次就可以;;不管是怎样的 匹配 4 //pattern.test(str); 5 6 str.match(pattern);//和上面 一样,,下面也能够 取到 分组匹配到的 字符串 7 8 //上面两种任意一种方式还要是匹配,之后就可以通过下面 取到第一分组 匹配到的字符串。 9 alert(RegExp.$1); //google
演示一个案例,将匹配到的字符串 加粗,打印出来
1 var str2='You are a 8shit8'; 2 3 document.write(str2.replace(pattern,'<strong>$1</strong>')); //$1 取出 匹配到的 分组字符串
演示第二个案例,将 'google baidu' 两个单词位置调换
1 var pattern2=/(.*)\s(.*)/; 2 var str='google baidu'; 3 alert(str.replace(pattern2,'$2 $1')); //将 他们的 位置 调换
8》贪婪和惰性
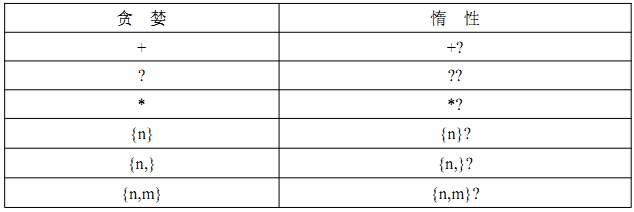
示例一:
1 var pattern =/[a-z]+/; //贪婪模式 2 var str='ddfdfds'; 3 4 alert(str.replace(pattern,1)); //1 //只会 匹配到 第一个 将第一个 替换掉 5 6 pattern=/[a-z]/g; //进行全局匹配 7 8 alert(str.replace(pattern,1)); //1111111 9 10 //使用 惰性模式 11 pattern =/[a-z]+?/; 12 alert(str.replace(pattern,1)); //1dfdfds
下面是显示贪婪模式的经典例子
1 //贪婪模式 2 var pattern2=/8(.*)8/g; 3 var str='8google8 8google8 8google8'; //最先 匹配的 两边的 88 因为 . 也 匹配 8 4 //<strong>google8 8google8 8google</strong> 5 document.write(str.replace(pattern2,'<strong>$1</strong>'));
输出结果:
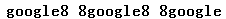
使用惰性模式:
1 //下面使用 惰性模式 2 pattern2=/8(.*?)8/g; 3 document.write(str.replace(pattern2,"<strong>$1</strong>")); 4 //输出结果: 5 //<strong>google</strong> 6 //<strong>google</strong> 7 //<strong>google</strong>
输出结果:
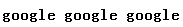
使用 另一种 禁止贪婪的模式:
1 pattern2=/8([^8]*)8/g; 2 document.write(str.replace(pattern2,"<strong>$1</strong>")); //和上面 的 实现的 效果一样
输出结果:

