01: RabbitMQ
目录:
- 1.1 RabbitMq与Redis队列对比
- 1.2 在win7 64位机上安装RabbitMQ
- 1.3 RabbitMQ消息分发轮询 与 持久化
- 1.4 RabbitMQ 设定某个队列里最大可积累消息的条数(prefetch_count=1)
- 1.5 用exchange实现一条消息广播给多个队列queue接收
- 1.6 RabbitMQ rpc实现(消费者可以将执行结果返回给生产者)
- 1.7 RabbitMQ原理
- 1.8 RabbitMQ使用场景
1.1 RabbitMq与Redis队列对比 返回顶部
1、RabbitMQ与Redis作用
1. RabbitMQ: RabbitMQ是一个可以在不同程序间共享数据的代理,是实现AMQP(高级消息队列协议)的消息中间件的一种
2. Redis: 是一个Key-Value的NoSQL数据库
2. 线程Queue,进程Queue和RabbitMQ区别
1. 进程Queue用于父进程与子进程(或同一父进程中多个子进程)间数据传递
2. python自己的多个进程间交换数据或者与其他语言(如Java)进程queue就无能为力
3. RabbitMQ就是这样一个可以在不同程序间共享数据的代理
3、具体对比
1. 可靠消费
Redis: 没有相应的机制保证消息的消费,当消费者消费失败的时候,消息体丢失,需要手动处理
RabbitMQ: 具有消息消费确认,即使消费者消费失败,也会自动使消息体返回原队列,同时可全程持久化,保证消息体被正确消费
2. 可靠发布
Reids: 不提供,需自行实现
RabbitMQ: 具有发布确认功能,保证消息被发布到服务器
3. 高可用
Redis: 采用主从模式,读写分离,但是故障转移还没有非常完善的官方解决方案
RabbitMQ: 集群采用磁盘、内存节点,任意单点故障都不会影响整个队列的操作
4. 持久化
Redis: 将整个Redis实例持久化到磁盘
RabbitMQ: 队列,消息,都可以选择是否持久化
5. 应用场景分析
Redis: 轻量级,高并发,延迟敏感即时数据分析、秒杀计数器、缓存等
RabbitMQ: 重量级,高并发,异步批量数据异步处理、并行任务串行化,高负载任务的负载均衡等
1.2 在win7 64位机上安装RabbitMQ 返回顶部
1:安装RabbitMQ需要先安装Erlang语言开发包
1)下载地址 http://www.erlang.org/download.html 在win7下安装Erlang最好默认安装。
2)C:\Program Files\erl8.3\bin 将Erlang的bin目录路径添加到环境变量
2:安装RabbitMQ 下载地址 http://www.rabbitmq.com/download.html
1) 按照默认安装,安装RabbitMQ
2) C:\Program Files\RabbitMQ Server\rabbitmq_server-3.6.8\sbin 将sbin目录添加到path环境变量中
3)安装完成后后就可以在windows的services.msc中看到RabbitMQ处于启动状态
4)切换到执行命令目录: cd C:\Program Files\RabbitMQ Server\rabbitmq_server-3.6.8\sbin
a) 首先关闭rabbitmq: rabbitmqctl stop_app
b) 还原: rabbitmqctl reset
c) 启动: rabbitmqctl start_app
d) 添加用户: rabbitmqctl add_user root root
e) 设置权限: rabbitmqctl set_permissions -p / root ".*" ".*" ".*"
f) 查看用户: rabbitmqctl list_users
g) 查看队列及未处理个数: rabbitmqctl.bat list_queues
3:安装pike
注:为了支持RabbitMQ,每种语言都有自己专有的模块去与RabbitMQ通信,在python中最常用的是pika
安装pika的方法: pip install pika
1.3 RabbitMQ消息分发轮询 与 持久化 返回顶部
1、RabbitMQ消息分发轮询:重启RabbitMq会丢失所有的queue中的数据
1. RabbitMQ默认采取轮询方法,将第一个消息发给a第二个发送给b以此类推
2. 默认生产者会将消息发送消费者后会等待确认,如果加上no_ack=True就不会等确认,如果消费者还未执行完
就突然断了,那么这条数据不会被其他消费者接收到


import pika #1 建立一个最基本的socket #2 ConnectionParameters指定连接的地址,可以加上端口号,用户名,密码等,本机不需要密码 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #开通一个管道 #声明queue,管道象一条马路,可以跑很多车,每个queue就像一辆车,这里的队列‘车’名字叫hello channel.queue_declare(queue='hello') #这里就是正真开始发消息了,向队列hello中发送消息’hello’ channel.basic_publish(exchange='', routing_key='hello', #routing_key就是队列的名字,这里指定向队列hello发消息 body='Hello World!') #body里面是要向队列发送的消息 print(" [x] Sent 'Hello World!'") connection.close() #发送结束后关闭队列,不用关闭管道
import pika,time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #因为不知道那个那个程序先启动,所以需要两边都声明一个queue channel.queue_declare(queue='hello') #因为你要从这个队列里收消息,所以你也要建立这个队列 #1 ch 是刚刚声明的channel = connection.channel()对象 #2 method是指定要把消息发送给那些queue的信息 def callback(ch, method, properties, body): #回调函数,消息来了就调用这个函数处理 time.sleep(80) print(ch,method,properties) print(" [x] Received %r" % body) ch.basic_ack(delivery_tag=method.delivery_tag) #如果去掉no_ack = True必须加ch.basic_ack,让消费者收到消息主动发送确认 #否则消费者如果收到消息后断掉,那么这条消息依然会发送给另一个,再断开又发送下一个,无限循环 #这里仅仅是声明了收队列hello中的内容,并调用callback处理,实际上在这里还没有收 #只有执行下面的channel.start_consuming()才会正真的收 channel.basic_consume(callback, #如果收到消息,调用callback函数来处理消息,标准格式带四个参数 queue='hello', #指明要从那个队列里收消息 # no_ack=True #no acknowledgement,如果为True不让消费者确认是否收到数据 ) #no_ack = True去掉,如果一个消费者断掉会将数据传递给另一个消费者 print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() #只有启动这里才会启动收消息,一直收,没有消息就卡在这里 # 1. no_ack=True 指定不需要让消费者收到消息发送却认,如果这个消费者还未接收就断开,消息就会丢失 # 2. 若果no_ack=True 被注释掉,默认就是no_ack=False,那么如果消费者收到消息前断开,就发送给其他消费者 # 3. 如果no_ack=False,那么就必须指定消费者收到消息必须发生确认(ch.basic_ack(delivery_tag=method.delivery_tag)) # 如果没有这句,生产者就认为消费者未收到数据,如果这个消费者断开,就会发送给下一个(即使已经收到) # 4. channel.start_consuming()这句才是正真指定让消费者接收数据,每次启动消费者都会卡在这里等待接收数据
2、RabbitMQ消息持久化:重启RabbitMq会保留所有的queue中的数据
1. 将队列变成持久化的只需要添加下面两条即可:
第一条:channel.queue_declare(queue='hello1',durable=True)
第二条:channel.basic_publish(properties = pika.BasicProperties(delivery_mode=2,))
import pika #1 建立一个最基本的socket #2 ConnectionParameters指定连接的地址,可以加上端口号,用户名,密码等,本机不需要密码 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #开通一个管道 #声明queue,管道象一条马路,可以跑很多车,每个queue就像一辆车,这里的队列‘车’名字叫hello #第一步:要想达到队列持久化,就必须再加上durable=True,这样重启完RabbitMQ后队列数据才不会丢 channel.queue_declare(queue='hello1',durable=True) channel.basic_publish(exchange='', routing_key='hello1', #routing_key就是队列的名字,这里指定向队列hello发消息 body='Hello World!', #body里面是要向队列发送的消息 properties = pika.BasicProperties( delivery_mode=2, #第二步:如果只有这一条重启服RabbitMQ服务后只有队列,但没数据 ) #消息持久化 ) print(" [x] Sent 'Hello World!'") connection.close() #发送结束后关闭队列,不用关闭管道
import pika, time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 因为不知道那个那个程序先启动,所以需要两边都声明一个queue channel.queue_declare(queue='hello1', durable=True) # 1 ch 是刚刚声明的channel = connection.channel()对象 # 2 method是指定要把消息发送给那些queue的信息 def callback(ch, method, properties, body): # 回调函数,消息来了就调用这个函数处理 # time.sleep(8) print(ch, method, properties) print(" [x] Received %r" % body) ch.basic_ack(delivery_tag=method.delivery_tag) # 如果去掉no_ack = True必须加ch.basic_ack,让消费者收到消息主动发送确认 # 否则消费者如果收到消息后断掉,那么这条消息依然会发送给另一个,再断开又发送下一个,无限循环 # 这里仅仅是声明了收队列hello中的内容,并调用callback处理,实际上在这里还没有收 # 只有执行下面的channel.start_consuming()才会正真的收 channel.basic_consume(callback, # 如果收到消息,调用callback函数来处理消息,标准格式带四个参数 queue='hello1', # 指明要从那个队列里收消息 # no_ack=True #no acknowledgement,如果为True不让消费者确认是否收到数据 ) # no_ack = True去掉,如果一个消费者断掉会将数据传递给另一个消费者 print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 只有启动这里才会启动收消息,一直收,没有消息就卡在这里
2. 测试队列是持久化的
1. 在windows的services.msc服务中重启RabbitMQ服务
2. 切换到目录: cd C:\Program Files\RabbitMQ Server\rabbitmq_server-3.6.8\sbin
3. 执行命令 : rabbitmqctl.bat list_queues 所有的queue数据都还在
1.4 RabbitMQ 设定某个队列里最大可积累消息的条数(prefetch_count=1) 返回顶部
1、设定队列最大积累条数作用
1. 基于上面的情况,第一条消息发送给消费者1,第二条发送给消费者2,以此类推,
2. 现实生活中机器的配置不同,所以均匀分配就不好了,这时就可以使用RabbitMQ的广播模式
3. RabbitMQ向客户端发消息时先检查你现在还有多少消息,如果对列里积累的消息超过1,就不会再给你发消息了
2、只需要改变一点
将RabbitMQ变成广播模式特别容易,仅用在消费者端添加:channel.basic_qos(prefetch_count=1) 指定这个消费
者的队列最多就积累一条消息,如果超过一条未处理的消息,就不再接收
import pika #1 建立一个最基本的socket #2 ConnectionParameters指定连接的地址,可以加上端口号,用户名,密码等,本机不需要密码 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #开通一个管道 #声明queue,管道象一条马路,可以跑很多车,每个queue就像一辆车,这里的队列‘车’名字叫hello #第一步:要想达到队列持久化,就必须再加上durable=True,这样重启完RabbitMQ后队列数据才不会丢 channel.queue_declare(queue='hello1',durable=True) channel.basic_publish(exchange='', routing_key='hello1', #routing_key就是队列的名字,这里指定向队列hello发消息 body='Hello World!', #body里面是要向队列发送的消息 properties = pika.BasicProperties( delivery_mode=2, #第二步:如果只有这一条重启服RabbitMQ服务后只有队列,但没数据 ) #消息持久化 ) print(" [x] Sent 'Hello World!'") connection.close() #发送结束后关闭队列,不用关闭管道
import pika,time connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() #因为不知道那个那个程序先启动,所以需要两边都声明一个queue channel.queue_declare(queue='hello1',durable=True) #1 ch 是刚刚声明的channel = connection.channel()对象 #2 method是指定要把消息发送给那些queue的信息 def callback(ch, method, properties, body): #回调函数,消息来了就调用这个函数处理 time.sleep(8) print(ch,method,properties) print(" [x] Received %r" % body) ch.basic_ack(delivery_tag=method.delivery_tag) #如果去掉no_ack = True必须加ch.basic_ack,让消费者收到消息主动发送确认 #否则消费者如果收到消息后断掉,那么这条消息依然会发送给另一个,再断开又发送下一个,无限循环 channel.basic_qos(prefetch_count=1) #指定队列最多对多积累一条消息,超过一条不在接收 #这里仅仅是声明了收队列hello中的内容,并调用callback处理,实际上在这里还没有收 #只有执行下面的channel.start_consuming()才会正真的收 channel.basic_consume(callback, #如果收到消息,调用callback函数来处理消息,标准格式带四个参数 queue='hello1', #指明要从那个队列里收消息 # no_ack=True #no acknowledgement,如果为True不让消费者确认是否收到数据 ) #no_ack = True去掉,如果一个消费者断掉会将数据传递给另一个消费者 print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() #只有启动这里才会启动收消息,一直收,没有消息就卡在这里 # 1. 将RabbitMQ变成广播模式特别容易,仅用在消费者端添加:channel.basic_qos(prefetch_count=1) 指定这个消费 # 者的队列最多就积累一条消息,如果超过一条未处理的消息,就不再接收 # 2. 生产者中的代码和1.4中一样,消费者仅仅也就加了上面那条即可 # 3. 为了演示这个效果,可以将消费者代码赋值一份为consumer2.py,在consumer2.py中将回调函数中加上 # time.sleep(8)这样生产者连续发送4条消息,发现有三条都给了consumer,consumer2.py仅仅收到一条
1.5 用exchange实现一条消息广播给多个队列queue接收 返回顶部
1、广播的作用
1. 之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里
2. 但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了
3. Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
1)fanout: 所有绑定(bind)到此exchange的queue都可以接收消息(可以有多个exchange)
2)direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
3)topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
2、fanout 将消息发送给所有绑定到exchange转发器的队列(第一种)
1. fanout说明
1. 发布方(生产者)是不需要申明queue的,仅需要有一个exchange,类型是fanout
2. 消费者也要将在生产者中定义的exchange再定义一遍
3. 通过channel.queue_bind将需要的queue绑定到exchange中(queue=queue_name指定绑定的queue的名字)
4. 下面就一样了,通过exchange将消息发送到所有绑定的queue,消费者然后就可以从队列中收取数据了
2. fanout使用举例
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #1 标注出exchange类型为fanout,所有绑定(bind)到此exchange的queue都可以接收消息 channel.exchange_declare(exchange='logs', exchange_type='fanout') #1 可以通过命令行输入要发送的消息,如果没有输入默认是"info: Hello World!" # message = ' '.join(sys.argv[1:]) or "info: Hello World!" message = 'info:Hello World!' #也可以直接将发的消息写死 #1 因为这里是fanout广播,所以就不用声明queue channel.basic_publish(exchange='logs', routing_key='', #这里不必指定收消息的queue body=message) print(" [x] Sent %r" % message) connection.close() #注:在广播的exchange中如果生产者发送消息时有消费者不在,过后消费者再运行也不会收到(收音机)
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', exchange_type='fanout') #1 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 #2 发送端没有声明queue为什么接收端要声明queue:指定让装发器发送给那些queue #3 这里不指定具体的队列名字是因为这里的queue仅仅是为了收广播的,如果不收了这个queue就没用了 #4 这个queue的对象是result,queue真正的名字其实是result.method.queue(随机的queue名字) result = channel.queue_declare(exclusive=True) queue_name = result.method.queue #1 将queue绑定到转发器exchange='logs'中,让队列queue知道从哪个转法器去接收数据,logs是转法器名字 #2 这里声明queue=queue_name 是指定转发器要将消息发送给那些队列,然后消费者再从queue中收 channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): #每次收到消息都会调用这个回调函数处理 print(" [x] %r" % body) channel.basic_consume(callback, #指定处理这个随机queue的回调函数 queue=queue_name, #上面生成的随机queue名字 no_ack=True) channel.start_consuming()
3、有选择的接收消息(exchange type=direct) (第二种)
1. 有选择的接收消息作用
作用: 接收者可以过滤,只接收自己想要的消息
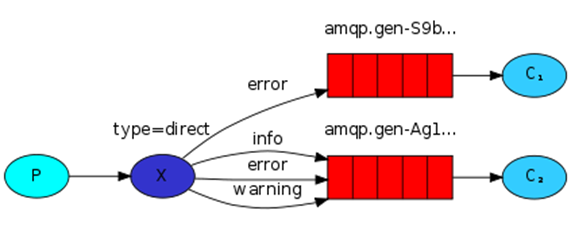
2. 运行演示
1.执行生产者发送命令:
C:\Users\admin\PycharmProjects\s14\Day11> python direct_publisher.py warning from alex
注1:这里生产者指定发送的消息时warning级别
2. 执行消费者接收命令:
C:\Users\admin\PycharmProjects\s14\Day11> python direct_consumer.py info warning [x] 'warning':b'from alex'
注2:这里只有运行消费者指定收取级别是warning级别的才会收到数据,其他级别都无法收到from alex这条消息
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', #exchange名字可以随便取 exchange_type='direct') #exchange模式,是direct #1 可以定义不同级别的日志,如果没有写级别就默认就发到info中 #2 默认会去取你执行生产者这个脚本的第一个参数,如果没有传入参数就按照默认是级别‘info’ severity = sys.argv[1] if len(sys.argv) > 1 else 'info' message = ' '.join(sys.argv[2:]) or 'Hello World!' #开始发消息 channel.basic_publish(exchange='direct_logs', routing_key=severity, #定义将消息都发到这个级别里面 body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 1 serverities就是将你执行生产者脚本时后面跟的参数,以列表形式返回 # 2 如果没有参数就会报错就退出了(参数可以是info,warning。。) # python direct_consumer.py info warning severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) print('ser', severities) # 1 循环列表所有传入的参数,将每一个参数都绑定到这个exchange中 # 2 queue=queue_name是上面随机生成的队列名字 # 3 routing_key=severity指定所有级别为severity参数指定级别的全部都收 # 4 客户端之所以可以收所有级别的queue是因为这里都绑定各个级别的queue for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
4、RabbitMQ topic细致的消息过滤
1. 有选择的接收消息作用
1. 比如说现在有很多应用,Apache,MySQL的日志都会包含info,error等,这样如何区分
2. direct过滤是直接写死了是info,error等,而这里是用过滤条件
3. (收取生产者发送的任何消息);*.error(收取所有级别为error的消息);mysql.*(收取所有以mysql开头的消息)
4. topic和上面的direct写法上没有什么区别,仅仅需要将格式变成topic即可(type='topic')
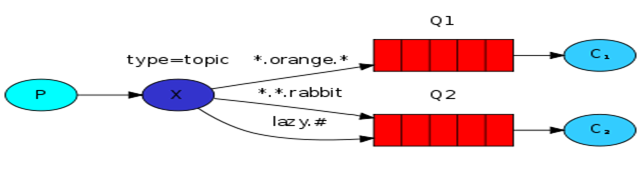
2. 运行演示
1. 运行生产者程序发送消息
1)C:\Users\admin\PycharmProjects\s14\Day11> python topic_publisher.py mysql.info
2. 运行消费者程序接收指定级别的消息
1)C:\Users\admin\PycharmProjects\s14\Day11> python topic_consumer.py *.info
2)C:\Users\admin\PycharmProjects\s14\Day11> python topic_consumer.py *.error mysql.*
3)C:\Users\admin\PycharmProjects\s14\Day11> python topic_consumer.py #
注1:在生产者中发送mysql.info消费者中三条都可以收到这条消息,消息内容为:[x] 'mysql.info':b'Hello World!'
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') #1 发送消息的格式应该是anonymous.info的形式 routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
1.6 RabbitMQ rpc实现(消费者可以将执行结果返回给生产者) 返回顶部
1、rpc作用
1. 在前面的方法中只能实现生产者发消息,消费者收消息,消息流是单向的
2. 如果生产者发一条消息,需要让消费者执行,并让消费者将执行结果返回给生产者,前面的方法就无法完成
3. rpc可以实现生产者与消费者互发消息(两边即是生产者又是消费者)
4. 为了实现即使生产者又是消费者,需要建立两个queue,一个queue用来放命令,一个queue用来放执行结果
import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() #实例化连接实例对象 channel.queue_declare(queue='rpc_queue') #客户端将消息发送到rpc_queue服务器端也要定义这个queue def fib(n): #这里就是求斐波那契的一个函数,不是重点 if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2) #1 on_request中做了哪些事:收取命令,执行命令,返回结果 #2 这里的props参数就是客户端告诉服务器端要将结果发送到哪个queue中 def on_request(ch, method, props, body): #调试的时候,消费者只要发送消息就会调用这个函数 n = int(body) #这里的body就是从客户端收取的内容 print(" [.] fib(%s)" % n) response = fib(n) #直接调用定义的fib斐波那契函数得到执行结果 #1在这一步服务器端已经的到了执行结果,但是怎样才能将结果返回给客户端 #2 这里是在客户端发送消息的时候添加了一个新的字段,字段里指明服务器将结果发到哪个队列里 ch.basic_publish(exchange='', routing_key=props.reply_to, #是发送方随机生成的那个队列的名字 #1 correlation_id是客户端发送给服务器端uuid值,服务端会将这个id再返回给客户端 #2 这样客户端就可以确定这条消息就是客户端刚刚发送给你的执行结果 properties=pika.BasicProperties(correlation_id = props.correlation_id), body=str(response)) # 将消息返回给客户端 ch.basic_ack(delivery_tag = method.delivery_tag) #收到消息后主动发送确认 #收到消息就调用回调函数on_request,并指定从rpc_queue中收取消息 channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming() #调试的时候,消费者没有消息时就卡在这里,有消息就自动调用on_request
import pika import uuid,time class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) self.channel = self.connection.channel() #实例化连接实例对象 result = self.channel.queue_declare(exclusive=True) #生成一个随机queue对象 self.callback_queue = result.method.queue #获得这个随机queue self.channel.basic_consume(self.on_response, no_ack=True, #声明调用on_response处理 queue=self.callback_queue) #从刚刚指定的随机queue中取结果 def on_response(self, ch, method, props, body): #只要一收到消息就自动调用这个回调函数 #1 corr_id是服务器端自己生成的uuid值,在发送消息时已经一起发送给服务器端 #2 服务器端会将执行结果和客户端发送给自己uuid值一起发送给客户端 #3 客户端通过判断如果,uuid值相同那么这条消息就是我刚刚发送消息的执行结果 #4 得到了执行结果body后才会将None变成body执行结果,结束下面的while循环 if self.corr_id == props.correlation_id: self.response = body #想让下面的while循环结束就在这里让self.response不为None #这里的body是我们收到的内容 def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) self.channel.basic_publish(exchange='', #在广播模式可以指定转发器名字 routing_key='rpc_queue', #将命令发发送到rpc_queue properties=pika.BasicProperties( #消息持久化 reply_to = self.callback_queue, #让服务器将执行结果返回到这个queue里, # reply_to这个queue是前面生成的随机queue correlation_id = self.corr_id,#corr_id随机生成的uuid值 ), body=str(n)) #发送的消息 while self.response is None: #想让这个死循环结束,就必须使self.response不为None self.connection.process_data_events() #非阻塞版的start_consumer,有消息就收消息,没消息不阻塞继续往下走 #如果有消息就会自动触发on_response函数, #在on_response中将self.response改成body(服务端返回的结果)了所以就跳出while了 print("只要能走到这里就证明没消息") time.sleep(0.5) return int(self.response) fibonacci_rpc = FibonacciRpcClient() #实例化 imp_num = input('please input fib num:') response = fibonacci_rpc.call(imp_num) #调用实例的call方法 计算斐波那契第六个数的值 print(" 第%s个fib数是 %r" %(imp_num,response)) #注:uuid的作用是如果我们在while循环中没有sleep而是发送了其他命令,不用uuid标示就会接收乱
1.7 RabbitMQ原理 返回顶部
1、RabbitMQ介绍
1. MQ全称为Message Queue, 是一种分布式应用程序的的通信方法,它是消费-生产者模型的一个典型的代表。
2. producer往消息队列中不断写入消息,而另一端consumer则可以读取或者订阅队列中的消息。
3. RabbitMQ是一个遵循AMQP协议的消息中间件,它从生产者接受消息并传递给消费者,在这和过程中,根据路由规则就行路由、缓存和持久化。
4. 业务上,可以实现服务提供者和消费者之间的数据解耦,提供高可用性的消息传输机制,在实际生产中应用相当广泛。
2、Rabbitmq系统最核心的组件:Exchange和Queue
1. clientA生产消息,发送给服务器端的Exchange1
2. Exchange1收到消息,根据ROUTINKEY,将消息转发给匹配的Queue1
3. Queue1收到消息,将消息发送给订阅者Client1
4. Client1收到消息,发送ACK给队列确认收到消息
5. Queue1收到ACK,删除队列中缓存的此条消息
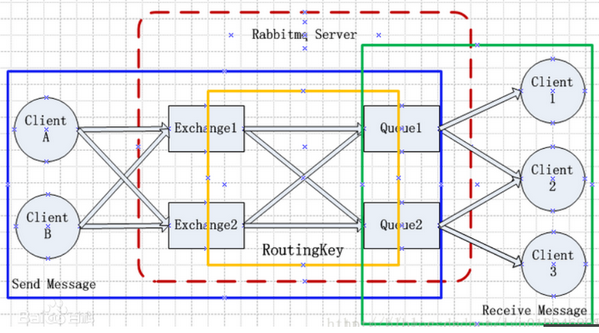
# 1、Publisher:是Message的生产者,Publisher这个Clients产生了一些Message。 # 2、Consumer:Message的消费者,Publisher产生的Message,最终要到达Consumer这个Clients,进行消费。 # 3、Exchange:指定消息按什么规则,路由到哪个Queue,Message消息先要到达Exchange,在Server中承担着从Produce接收Message的责任。 # 4、Queue:到达Exchange的消息,根据制定的规则(Routing key)到达对应的Queue, # 在Server中承担着装载Message,是Message的容器,等待被消费出去。 # 5、Routing key:在Exchange和Queue之间隐藏有一条黑线,可以将这条黑线看成是Routing key, # Exchange就是根据这些定义好的Routing key,将Message送到对应的Queue中去,是Exchange和Queue之间的桥梁。 # 6、Broker:之前一直不理解这个Broker,其实Broker就是接收和分发消息的应用,也就是说RabbitMQ Server就是Message Broker。 # 7、VirtualHost:虚拟主机,一个Broker里可以开有多个VirtualHost,它的作用是用作不同用户的权限分离。 # 8、Connection:是Publisher/Consumer和Broker之间的TCP连接。 # 断开连接的操作只会在Publisher/Consumer端进行,Broker不会断开连接,除非出现网络故障或者Broker服务出现问题,Broker服务宕了。 # 9、Connection: Channel: 如果每一次访问RabbitMQ就建立一个Connection,那在消息量大的时候建立TCP Connection的开销就会很大, # 导致的后果就是效率低下。
3、Queue(组件1)
1. 消息队列,提供了FIFO的处理机制,具有缓存消息的能力,rabbitmq中,队列消息可以设置为持久化,临时或者自动删除。
2. 设置为持久化的队列,queue中的消息会在server本地硬盘存储一份,防止系统crash,数据丢失
3. 设置为临时队列,queue中的数据在系统重启之后就会丢失
4. 设置为自动删除的队列,当不存在用户连接到server,队列中的数据会被自动删除
4、Exchange(组件2)
1. Exchange类似于数据通信网络中的交换机,提供消息路由策略。
2. rabbitmq中,producer不是通过信道直接将消息发送给queue,而是先发送给Exchange。
3. 一个Exchange可以和多个Queue进行绑定,producer在传递消息的时候,会传递一个ROUTING_KEY。
4. Exchange会根据这个ROUTING_KEY按照特定的路由算法,将消息路由给指定的queue。
5. 和Queue一样,Exchange也可设置为持久化,临时或者自动删除。
1.8 RabbitMQ使用场景 返回顶部
1、异步处理
1. 在注册服务的时候,如果同步串行化的方式处理,让存储数据、邮件通知等挨着完成,延迟较大
2. 采用消息队列,可以将邮件服务分离开来,将邮件任务之间放入消息队列中,之间返回,减少了延迟,提高了用户体验
2、应用解耦
1. 电商里面,在订单与库存系统的中间添加一个消息队列服务器,在用户下单后,订单系统将数据先进行持久化处理
2. 然后将消息写入消息队列,直接返回订单创建成功,然后库存系统使用拉/推的方式,获取订单信息再进行库存操作
3、流量削锋
1. 秒杀活动中,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
2. 服务器在接收到用户请求后,首先写入消息队列,这时如果消息队列中消息数量超过最大数量,则直接拒绝用户请求或返回跳转到错误页面;
3. 秒杀业务根据秒杀规则读取消息队列中的请求信息,进行后续处理
4、日志处理:Kalfka消息中间件
1.9 RabbitMQ如何保证可靠消费
参考博客:https://www.cnblogs.com/nizuimeiabc1/p/9397326.html
1、确认种类
1)一种是消息发送确认
1. 这种是用来确认生产者将消息发送给交换器,交换器传递给队列的过程中,消息是否成功投递。
2. 发送确认分为两步,一是确认是否到达交换器,二是确认是否到达队列。
2)第二种是消费接收确认
1. 这种是确认消费者是否成功消费了队列中的消息。
2、消息发送确认(第一种)
1. 如果设置了Mandatory属性则当消息不能被正确路由到队列中去时将会触发ReturnCallback
2. 是否到达交换器
3. 是否到达队列
1)ReturnCallback接口当消息从交换器发送到对应队列失败时触发(比如根据发送消息时指定的routingKey找不到队列时会触发)
2)一旦消息被投递到所有匹配的队列之后Broker就会发送一个确认给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了
3、消费接收确(确认)
1. 一旦发布一条消息生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息
2. 当消息最终得到确认之后,生产者应用可以通过回调ACK方法来处理该确认消息
3. 如果RabbitMQ因为自身内部错误导致消息丢失,生产者应用可以通过回调NACK方法来处理该确认消息
作者:学无止境
出处:https://www.cnblogs.com/xiaonq
生活不只是眼前的苟且,还有诗和远方。

