
Haddop大数据
Hadoop 是什么?
haddop是开源的分布式存储,和分布式计算平台
Java编写的开源系统,能够安排在大规模的计算平台上,从而提高计算效率
http://hadoop.apache.org
Hadoop核心组件:
Hbase:Nosql数据库 Key-Value存储
HDFS:分布式文件存储系统,存储海量数据
MapReduce:并行处理框架,实现任务分解和调度,主要用来做数据的分析 (不是谷歌发明的,是谷歌用的)
Hadoop可以用来做什么?
搭建大型数据仓库,PB级数据存储、处理、分析、统计等业务
Hadoop能解决那些问题?
海量数据需要及时分析和处理。
海量数据需要深入分析和挖掘。
数据需要长期保存。
Hadoop在国内的情景?
奇虎360:
京东、百度:存储,分析日志、数据挖掘和机器学习。
广告公司:存储日志,通过协调过滤算法为客户推荐广告
华为:云计算平台
淘宝、阿里:国内使用Hadoop最深入的公司
Hadoop基础理论:
- HDFS的文件被分成块进行存储,块的默认大小64MB,块是文件存储处理的逻辑单元,每个块默认大小64MB,
每个区块至少分配到三台DataNode上(默认三台)
- HDFS中有两类节点,NameNode和DataNode。
- NameNode是管理节点,存放文件元数据,1. 文件与数据块的映射表,2.数据块与数据节点的映射表。
- DateNode是HDFS的工作节点,存放数据块。
详解:
Namenode
-HDFS的守护程序
-记录文件是如何分割成数据块的,以及这些数据块被存储到那些节点上
-对内存和I/O进行集中管理
-是个单点,发生故障将使集群奔溃。
Secondary Namenode
-监控HDFS状态的辅助后台程序
-每个集群都有一个
-与NameNode进行通讯,定期保存HDFS数据快照
-当NameNode故障可以作为备用NameNode使用
DateNode
-每台从服务器都运行一个
-负责把HDFS数据块写到本地文件系统
JobTracker
-用于处理作业(用户提交代码)的后台程序
-决定由那些文件参数处理,然后切割task并分配节点
-监控task,重启失败的task(于不同的节点)
-每个集群只有一个JobTracker,位于Master节点
TaskTracker
-位于slave节点上,与datanode结合(代码与数据一起的原则)
-管理各自节点上的task(由jobtracker分配)
-每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于
并行执行map或reduce任务
-与jobtracker交互
Haddop优势
1.高扩展 2.低成本 3.成熟的开源圈
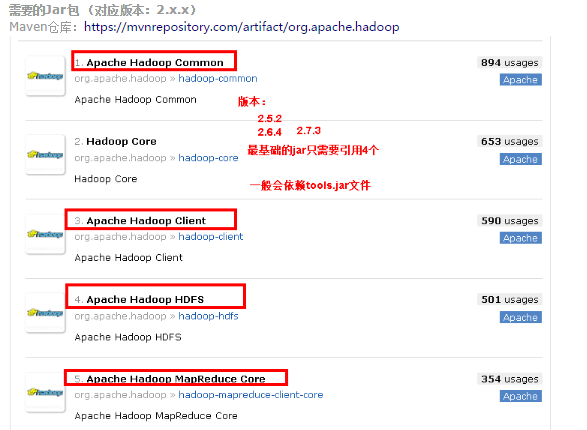
Hadoop 需要jar包
- hadoop-core
- hadoop-common
- hadoop-hdfs
- hadoop-mapreduce-client-core
- hadoop-client
- jdk.tools(一般需要引入,否则报错)
Haddop安装
Setp1:准备Linux环境
Setp2:安装JDK
Setp3:配置Haddop
详细:

主机名
一.查看linux的主机名
hostname
二.修改linux的主机名
hostname 修改后的名称
如:hostname hadoop
这样修改有个问题 每次重启的时候还会还原
如果永久修改的话就要配置文件
vim /etc/sysconfig/network
修改如下
HOSTNAME = hadoop
然后重启一下
reboot -h now 删除所有的进程,而不是平稳地终止它们
备注: shutdown -r now是立即停止然后重新启动,
安全地关闭或重启Linux系统,它在系统关闭之前给系统上的所有登录用户提示一条警告信息。
三.主机名跟ip进行绑定
vim /etc/hosts
在文件中增加一行
192.168.0.130 hadoop
验证
ping hadoop
防火墙
一.查看防火墙是否关闭:
service iptables status
二.关闭防火墙
service iptables stop
三.查看防火墙是否是自动运行
chkconfig --list
备注:
[root@localhost maven]# chkconfig --list | grep iptables
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
如果有一个为on 说明是自动启动的,没有off说明没有自动启动
四.关闭防火墙自动运行
chkconfig iptables off
验证 chkconfig --list | grep iptables
http://www.imooc.com/video/7646
安装JDK
配置环境变量
vim /etc/profile
添加
export JAVA_HOME=/usr/lib/jvm/java-7-epenjdk-amd64/
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
然后保存
然后输入 source /etc/profile 使其生效
配置SSH免密码登录
配置SSH免密码登录,首先需要有SSH的支持,可输入 ssh -version 进行验证是否已经安装ssh

下面开始看看如何配置SSH免密码登录吧。
首先输入ssh localhost,验证在为配置前是无法通过ssh连接本机的
下面在用户目录下(笔者使用的是root用户,所以是/root目录,普通用户的文件夹是在/home,目录下与用户名相同的目录)ls -a ,可以看见有一个隐藏的文件夹.ssh,如果没有的话可以自行创建。
如 我的目录是 /home/root 然后创建.ssh文件夹 mkdir .ssh
然后输入一下命令,出现如下图示:
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa

这里解释一下命令的含义(注意区分大小写):ssh-keygen代表生成密钥;-t表示生成密钥的类型;-P提供密语;-f指定生成的文件.这个命令执行完毕后会在.ssh文件夹下生成两个文件,分别是id_dsa、id_dsa.pub,这是SSH的一对私钥和公钥,就像是钥匙和锁。下一步将id_dsa.pub追加到授权的key中,键入一下命令:
cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys
此时,免密码登录本机就配置完成了,下面再次输入ssh localhost进行验证,出现下图所示信息代表配置成功了
ssh localhost

则是配置成功了
配置Haddop
下载hadoop
输入 wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
解压缩 tar -zxvf hadoop-1.2.1.tar.gz
二. 配置系统环境变量PATH
vim /etc/profile
添加 export HADOOP_HOME=/opt/hadoop-1.2.1
然后在 export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH上添加 $HADOOP_HOME/bin 如下:
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH
然后保存
然后输入 source /etc/profile 使其生效
验证是否配置成功: 输入hadoop,此时出来好多命令,说明配置成功
一. 开始配置hadoop的配置文件(一共配置4个文件)
输入 echo $JAVA_HOME 查看jdk 安装目录 如:/usr/local/jdk
1.1 进入到 /usr/local/xiaoma/hadoop/hadoop/etc/hadoop
1.2 vim hadoop-env.sh
把 # export JAVA_HOME=/usr/lib/j2sdk1.5-sun 改成jdk的路径
如:export JAVA_HOME=/usr/local/jdk
1.3 vim core-site.xml
在<configuration> </configuration> 标签内输入以下代码
<property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/xiaoma/hadoop/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
备注:第一个属性用来配置hadoop的工作目录,第二个用来配置 name目录还如何访问
1.4 vim hdfs-site.xml
在<configuration> </configuration> 标签内输入以下代码
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/xiaoma/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/xiaoma/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>localhost:50070</value>
</property>
备注:属性用来配置 文件系统数据的存放目录
1.5 vim mapred-site.xml.template
在<configuration> </configuration> 标签内输入以下代码
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
备注:属性用来配置任务该如何访问
4.1 初始化HDFS系统
在hadop2.7.1目录下执行命令:
|
1
|
bin/hdfs namenode -format |
出现如下结果说明初始化成功。

4.2 开启 NameNode 和 DataNode 守护进程
在hadop2.7.1目录下执行命令:
|
1
|
sbin/start-dfs.sh |
成功的截图如下:

4.3 使用jps命令查看进程信息:

若出现如图所示结果,则说明DataNode和NameNode都已经开启。
停止的话 是
在hadop2.7.1目录下执行命令:
|
1
|
sbin/stop-dfs.sh |
4.4 查看web界面
在浏览器中输入 http://localhost:50070 ,即可查看相关信息,截图如下

至此,hadoop的环境就已经搭建好了。
输入jps 进行验证
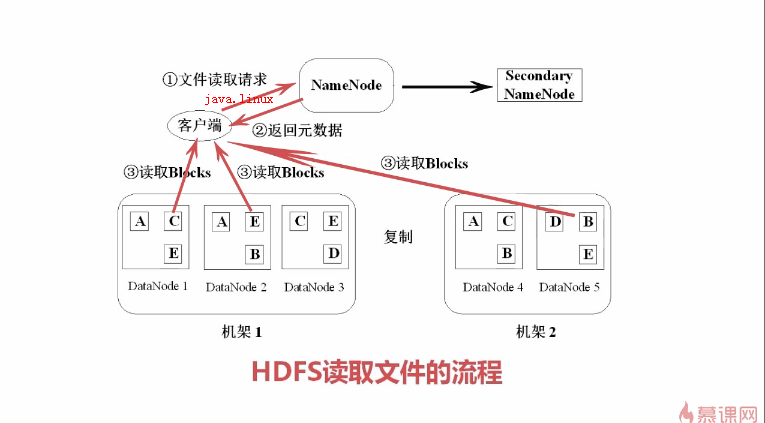
HDFS中数据管理策略
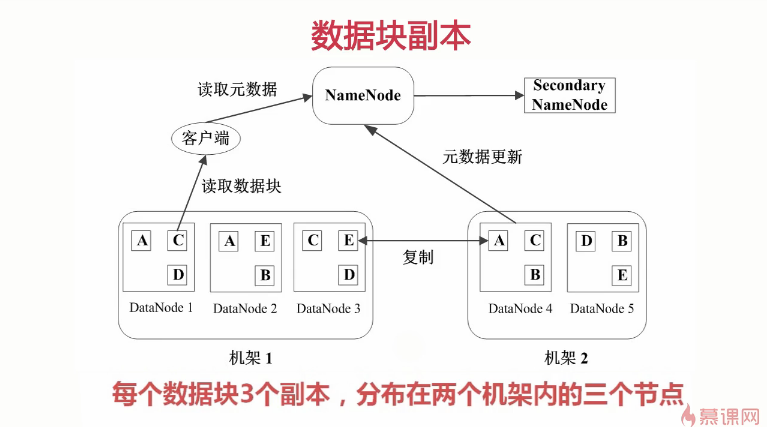
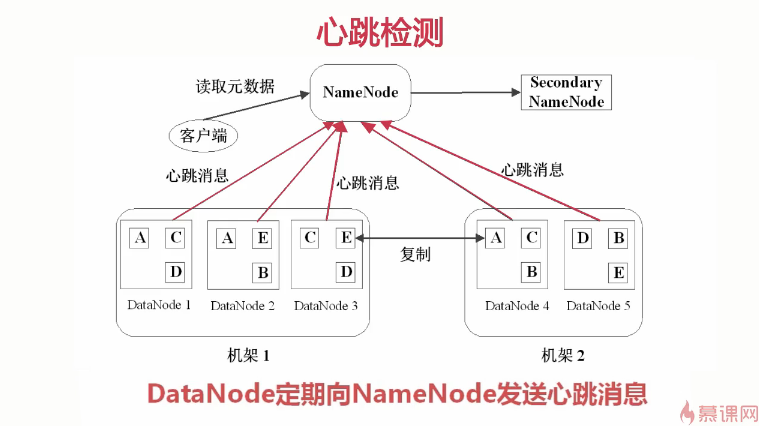
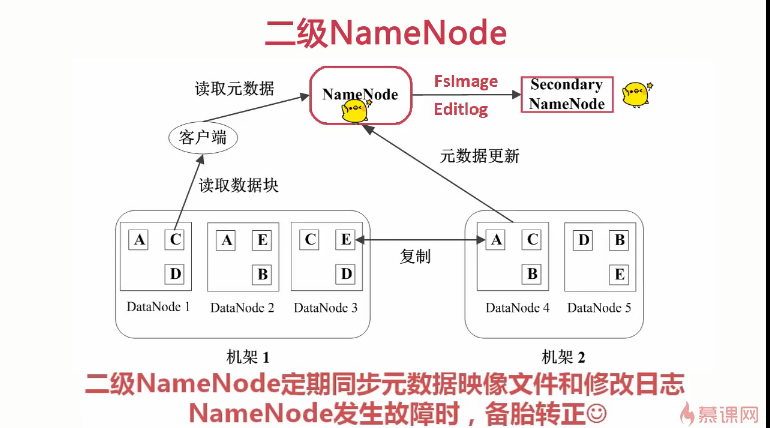
HDFS读取文件的流程
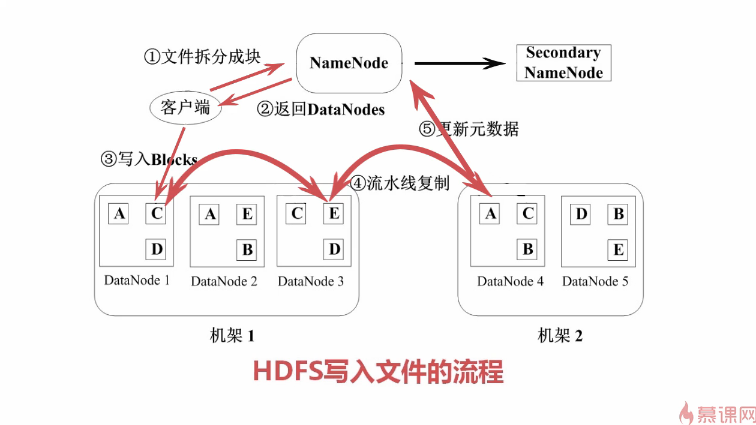
HDFS写入文件的流程:
HDFS的特点
1、数据冗余,硬件容错(3个备份)
2、流式的数据访问(一次写入,多次读取,一旦写入就没法随机修改)
3、存储大文件
适用性和局限性
- 适合数据批量读写,吞吐量高;
- 不适合交互式应用,低延迟很难满足;
- 适合一次写入多次读写,顺序读写;
- 不支持多用户并发写相同的文件;
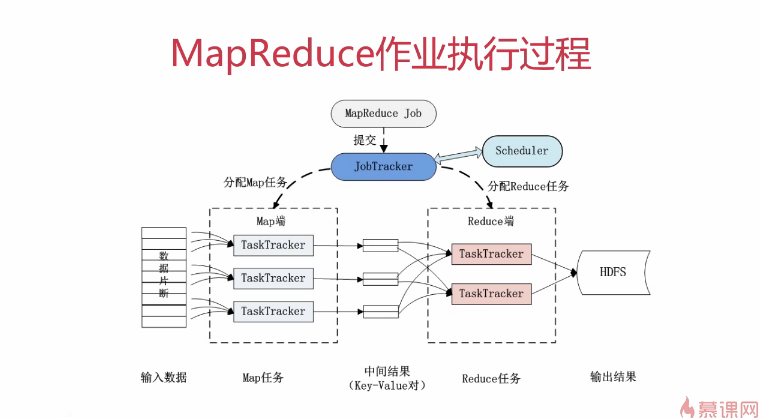
MapReduce原理
分而久之,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce)。
MapReduce运行流程
JobTracker的角色
1.作业调度 2.分配任务、监控任务执行进度 3.监控TaskTracker的状态
TaskTracker的角色
1.执行任务 2.汇报任务状态
http://www.imooc.com/video/7648
