
距离的计算及分页排序
作为一个基于LBS的O2O电商平台,要给用户提供 周边的精准的商品和商家的定位及排序。距离的计算和排序问题就摆在我们面前。
我们目前Web获取用户的坐标地址来源有两个:
1) IP地址,通过ip及查询ip地址库获取用户的 坐标信息,缺点是不太准确,一般到市、县,大家还记得那年的 珊瑚虫 QQ吗,同那个原理一样。这个作为我们的默认坐标地址。
2) 用户提供,通过web网站的地图页搜索选取自己的坐标地址,和饿了吗 一样。我们选择的地图服务商为百度地图。
有了用户和商家的坐标地址就可以计算距离。其实就是计算球面上两个点的曲线距离
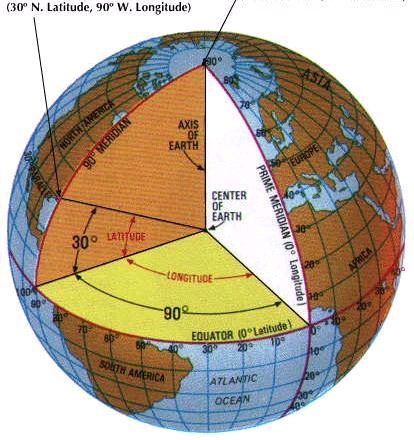
计算公式为:
R = 地球半径
Δlat = lat2− lat1;
Δlong = long2− long1
a = sin²(Δlat/2) + cos(lat1) * cos(lat2) * sin²(Δlong/2)
c = 2*atan2(√a, √(1−a));
d = R*c
mysql计算表达式:3956 * 2 * ASIN ( SQRT (
POWER(SIN((orig.lat - dest.lat)*pi()/180 / 2), 2)
+ COS(orig.lat * pi()/180) * COS(dest.lat * pi()/180) * POWER(SIN((orig.lon - dest.lon) * pi()/180 / 2), 2) ) )
(这里面的3956 单位是英里,公里为6378)
看到计算公式是不是很复杂 很头疼,我也是 我忽然想起老祖宗的勾股定理,看看能不能把这一坨公式简化一下。
我们做的是 身边O2O 社区电商型,距离都不会太远,所以可以看作是平面上的两个点的距离计算。
ROUND(SQRT( POWER(85.39*(store_lng-".$lng."),2)+POWER(111.13*(store_lat-".$lat."),2) ),3)
这样只能减少计算距离的计算量,当商户信息较多时,排序压力还是很大。此时 我们还要再减小搜索范围,
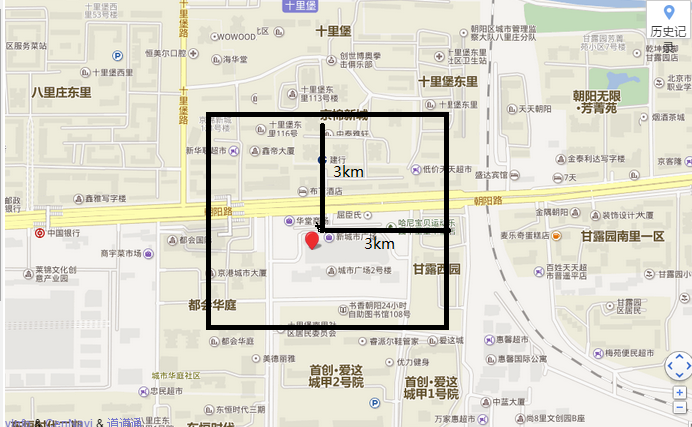
减小搜索范围到 周围3km的正方形中。
$max_lng = $lng + $km/85.39;
$min_lng = $lng - $km/85.39;
$max_lat = $lat + $km/111.13;
$min_lat = $lat - $km/111.13;
select
ROUND(SQRT( POWER(85.39*(store.store_lng-".$lng."),2)+POWER(111.13*(store.store_lat-".$lat."),2) ),3) AS juli
from store
where (store.store_lng BETWEEN ".$min_lng." AND ".$max_lng." ) AND ( store.store_lat BETWEEN ".$min_lat." AND ".$max_lat.")
另外在数据表中的 lng和lat 字段加联合索引 。 这样就解决了查询 效率问题。
看来 问题解决的差不多了,做个压测吧。
我勒个去 压力一大 好慢呀。
排查原因: (1)由于每人的坐标不同,导致每次执行的sql语句不同,sql无法做缓存。
(2)由于(1)的原因 ,服务器也不能缓存数据,每次都是新的请求,每次都要查库。
看来非要出杀手锏了,GeoHash 登场了。(本来想在二期再加)
原理: 首先将纬度范围(-90, 90)平分成两个区间(-90,0)、(0, 90),如果目标纬度位于前一个区间,则编码为0,否则编码为1。由于39.92324属于(0, 90),所以取编码为1。然后再将(0, 90)分成 (0, 45), (45, 90)两个区间,而39.92324位于(0, 45),所以编码为0。以此类推,直到精度符合要求为止。经度也用同样的算法,对(-180, 180)依次细分,得到116.3906的编码。接下来将经度和纬度的编码合并,奇数位是纬度,偶数位是经度,得到编码 11100 11101 00100 01111 00000 01101 01011 00001。最后,用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码。
由于geohash 的有边缘偏差,所以准确度要求高的话,可以加查附件8个区块的信息。
$geoHash_Arr=GeoHash::around($lng,$lat,$km);
$where=" ((geohash LIKE '{$geoHash_Arr[0]}%') OR (geohash LIKE '{$geoHash_Arr[1]}%') "
." OR (geohash LIKE '{$geoHash_Arr[2]}%') OR (geohash LIKE '{$geoHash_Arr[3]}%')"
." OR (geohash LIKE '{$geoHash_Arr[4]}%') OR (geohash LIKE '{$geoHash_Arr[5]}%')"
." OR (geohash LIKE '{$geoHash_Arr[6]}%') OR (geohash LIKE '{$geoHash_Arr[7]}%')"
." OR (geohash LIKE '{$geoHash_Arr[8]}%') )";
public static function around($lng,$lat,$km=3)
{
$n=5;
if($km>7.5)
{
$n=3;
}
else if($km>3)
{
$n=4;
}
else if($km>1)
{
$n=5;
}
else
{
$n=6;
}
$hash=self::encode($lng, $lat, $n);
$ret=self::expand($hash);
array_push($ret,$hash);
return $ret;
}
/*
* * 获取扩展的hash区块
* return array
*/
public static function expand($hash)
{
list($minlng, $maxlng, $minlat, $maxlat) = self::decode($hash);
$n=strlen($hash);
$dlng = ($maxlng - $minlng) / 2;
$dlat = ($maxlat - $minlat) / 2;
return array(
self::encode($minlng - $dlng, $maxlat + $dlat,$n),
self::encode($minlng + $dlng, $maxlat + $dlat,$n),
self::encode($maxlng + $dlng, $maxlat + $dlat,$n),
self::encode($minlng - $dlng, $maxlat - $dlat,$n),
self::encode($maxlng + $dlng, $maxlat - $dlat,$n),
self::encode($minlng - $dlng, $minlat - $dlat,$n),
self::encode($minlng + $dlng, $minlat - $dlat,$n),
self::encode($maxlng + $dlng, $minlat - $dlat,$n),
);
}
这样就解决了 并发下 数据库查询压力大的问题。距离的排序也由数据库 改为了web服务器。
再优化的话,可以 在数据库 加冗余字段,比如geohash4,geohash5,geohash6 分别代表 4位的hash值,5位的hash值,6位的hash值。

