MongoDB数据库聚合
前面的话
聚合操作主要用于对数据的批量处理,将记录按条件分组以后,然后再进行一系列操作,例如,求最大值、最小值、平均值,求和等操作。聚合操作还能够对记录进行复杂的操作,主要用于数理统计和数据挖掘。在 MongoDB 中,聚合操作的输入是集合中的文档,输出可以是一个文档,也可以是多条文档。本文将详细介绍MongoDB数据库聚合
单目的聚合
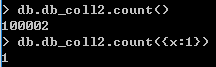
【count】
count是最简单,最容易,也是最常用的聚合工具,返回集合中的文档数量
db.collection_name.count()
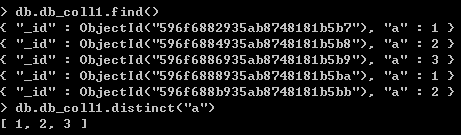
【distinct】
distinct()方法返回不重复的结果
聚合管道
聚合管道由阶段(Stage)组成,文档在一个阶段处理完毕后,聚合管道会把处理结果传到下一个阶段
聚合管道可以对文档进行过滤,查询出符合条件的文档;也可以对文档进行变换,改变文档的输出形式
每个阶段用阶段操作符(Stage Operators)定义,在每个阶段操作符中可以用表达式操作符(Expression Operators)计算总和、平均值、拼接分割字符串等相关操作,直到每个阶段进行完成,最终返回结果,返回的结果可以直接输出,也可以存储到集合中
【aggregate()】
MongoDB 中使用aggregate() 方法来构建和使用聚合管道,基本语法如下
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
下图是官网实例
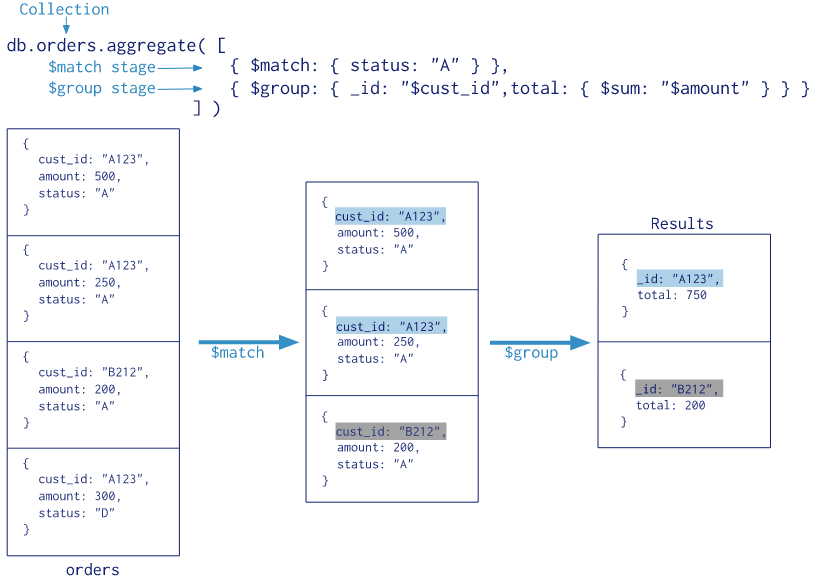
实例中,$match 用于获取 status = "A" 的记录,然后将符合条件的记录送到下一阶段 $group 中进行分组求和计算,最后返回 Results。其中,$match、$group 都是阶段操作符,而阶段 $group 中用到的 $sum 是表达式操作符
接下来,对阶段操作符和表达式操作符进行详解。将下列数据储存到article集合中,下面的实例将反复用到article集合
db.article.insertMany([{ "_id": ObjectId("58e1d2f0bb1bbc3245fa7570"), "title": "MongoDB Aggregate", "author": "huochai", "tags": ['Mongodb', 'Database', 'Query'], "pages": 5, "time" : ISODate("2017-07-19T22:42:39.736Z") }, { "_id": ObjectId("58e1d2f0bb1bbc3245fa7571"), "title": "MongoDB Index", "author": "huochai", "tags": ['Mongodb', 'Index', 'Query'], "pages": 3, "time" : ISODate("2017-07-19T22:43:39.236Z") }, { "_id": ObjectId("58e1d2f0bb1bbc3245fa7572"), "title": "MongoDB Query", "author": "match", "tags": ['Mongodb', 'Query'], "pages": 8, "time" : ISODate("2017-07-19T22:44:56.276Z") }])

阶段操作符
在UNIX命令中,shell管道可以对某些输入执行操作,并将输出用作下一个命令的输入。 MongoDB也在聚合框架中支持类似的概念。每一组输出可作为另一组文档的输入,并生成一组生成的文档(或最终生成的JSON文档在管道的末尾)。这样就可以再次用于下一阶段等等。
以下是在聚合框架可能的阶段操作符
$project - 用于从集合中选择一些特定字段 $match - 这是一个过滤操作,因此可以减少作为下一阶段输入的文档数量。 $group - 这是上面讨论的实际聚合。 $sort - 排序文档。 $skip - 通过这种方式,可以在给定数量的文档的文档列表中向前跳过。 $limit - 限制从当前位置开始的给定数量的文档数量。 $unwind - 用于展开正在使用数组的文档。使用数组时,数据是预先加入的,此操作将被撤销,以便再次单独使用文档。 因此,在这个阶段,将增加下一阶段的文件数量。
【$project】
下面示例中把文档中 pages 字段的值都增加10,并重命名成 newPages 字段,且不显示_id字段
db.article.aggregate([{$project:{}}])

【$match】
在 $match 中不能使用 $where 表达式操作符。如果 $match 位于管道的第一个阶段,可以利用索引来提高查询效率。如果$match 中使用 $text 操作符的话,只能位于管道的第一阶段。$match 尽量出现在管道的最前面,过滤出需要的数据,在后续的阶段中可以提高效率
查询出文档中 pages 字段的值大于等于5的数据

【$group】
从 article 中得到每个 author 的文章数,并输入 author 和对应的文章数

【$sort】
让集合 article 以 pages 升序排列

【$limit】
返回集合 article 中前两条文档

【$skip】
跳过集合 article 中一条文档,输出剩下的文档

【$unwind】
$unwind 参数数组字段为空或不存在时,待处理的文档将会被忽略,该文档将不会有任何输出。$unwind 参数不是一个数组类型时,将会抛出异常。$unwind 所作的修改,只用于输出,不能改变原文档
把集合 article 中 title="MongoDB Aggregate" 的 tags 字段拆分

表达式操作符
表达式操作符有很多操作类型,其中最常用的有布尔管道聚合操作、集合操作、比较聚合操作、算术聚合操作、字符串聚合操作、数组聚合操作、日期聚合操作、条件聚合操作、数据类型聚合操作等
【布尔】
$and 与
$or 或
$not 非
x>=10,并且x<=30的文档,返回true
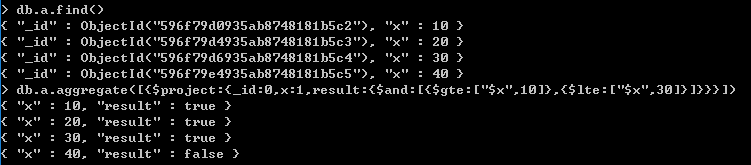
x>30,或者x<20的文档,返回true

x>20的文档,返回true

【文氏图集合操作】
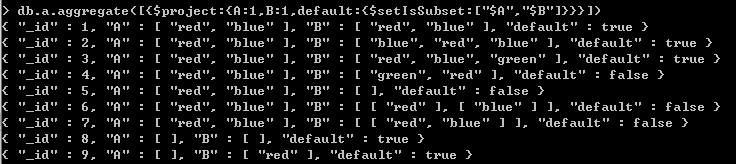
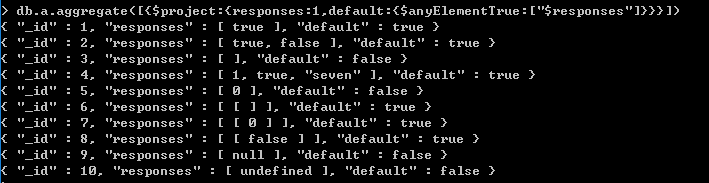
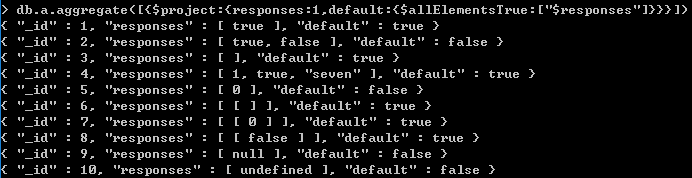
$setEquals 除了重复元素外,包括的元素相同 $setIntersection 交集 $setUnion 并集 $setDifference 只在前一集合出现,也就是后一个集合的补集 $setIsSubset 前一个集合是后一个集合的子集 $anyElementTrue 一个集合内,只要一个元素为真,则返回true $allElementsTrue 一个集合内,所有的元素都为真,则返回true
集合A与集合B,除了重复元素外,包括的元素相同,返回true
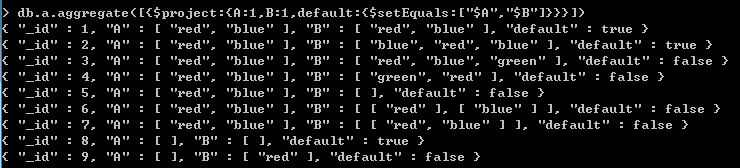
返回集合A与集合B的交集

返回集合A与集合B的并集

返回只在集合A中出现的数据,或者说是集合B的补集

集合A是集合B的子集,则返回true
只要一个为true,则返回true
全部为true,返回true
【比较操作】
$cmp 两个值相等返回0,前值大于后值返回1,前值小于后值返回-1 $eq 是否相等 $gt 前值是否大于后值 $gte 前值是否大于等于后值 $lt 前值是否小于后值 $lte 前值是否小于等于后值 $ne 是否不相等
qty与250相比较

qty与250是否相等

qty是否大于250

qty是否大于等于250

qty是否小于250

qty是否小于等于250

qty与250是否不相等

【算术运算】
$abs 绝对值 $add 和 $ceil 向上取整 $divide 除 $exp ex $floor 向下取整 $ln 自然对数 $log 对数 $log10 以10为底的对数 $mod 取模 $multiply 乘 $pow 指数 $sqrt 平方根 $subtract 减 $trunc 截掉小数取整
返回start - end后的绝对值

返回start + end的和

返回start / end的结果

返回estart的值

返回logestart的值

返回logendstart的值

返回log10start的值

返回start mod end的值

返回start * end的积

返回startend

返回start的平方根

返回start - end的差值

返回x的向上取整值

返回x的向下取整值

返回x的截掉小数取整值

【字符串操作】
$concat 字符串连接 $indexOfBytes 子串位置(字节) $indexOfCP 子串位置(字符) $split 分割字符串 $strLenBytes 字节长度 $strLenCP 字符长度 $strcasecmp 字符串比较 $substrBytes 创建子串(按字节) $substrCP 创建子串(按字符) $toLower 小写 $toUpper 大写
返回item和description连接后的字符串

返回'foo'在item中第一次出现的位置(字节)

返回'foo'在item中第一次出现的位置(字符)

以'o'来分割item

返回item的字节长度

返回item的字符长度

返回item与''foo"比较后的结果

返回item在0-3字节位置的子串

返回item在0-3字符位置的子串

将item大写

【数组操作】
$arrayElemAt 返回指定数组索引中的元素 $concatArrays 数组连接 $filter 返回筛选后的数组 $indexOfArray 索引 $isArray 是否是数组 $range 创建数值数组 $reverseArray 反转数组 $reduce 对数组中的每个元素应用表达式,并将它们组合成一个值 $size 数组元素个数 $slice 子数组 $zip 合并数组 $in 返回一个布尔值,表示指定的值是否在数组中
返回索引为0的元素

将name与favorites数组合并

返回item.price大于等于100的item

返回数字2在数组中的索引值

是否是数组
{ $isArray: [ "hello" ] } false
{ $isArray: [ [ "hello", "world" ] ] } true
创建数值数组
{ $range: [ 0, 10, 2 ] } [ 0, 2, 4, 6, 8 ]
{ $range: [ 10, 0, -2 ] } [ 10, 8, 6, 4, 2 ]
{ $range: [ 0, 10, -2 ] } [ ]
{ $range: [ 0, 5 ] } [ 1, 2, 3, 4, 5]
返回反转的数组
{ $reverseArray: [ 1, 2, 3 ] } [ 3, 2, 1 ]
{ $reverseArray: { $slice: [ [ "foo", "bar", "baz", "qux" ], 1, 2 ] } } [ "baz", "bar" ]
{ $reverseArray: null } null
{ $reverseArray: [ ] } [ ]
{ $reverseArray: [ [ 1, 2, 3 ], [ 4, 5, 6 ] ] } [ [ 4, 5, 6 ], [ 1, 2, 3 ] ]
对数组中的每个元素应用表达式,并将它们组合成一个值
{ $reduce: { input: [ [ 3, 4 ], [ 5, 6 ] ], initialValue: [ 1, 2 ], in: { $concatArrays : ["$$value", "$$this"] } } } [ 1, 2, 3, 4, 5, 6 ]
返回数组元素个数

返回子数组
{ $slice: [ [ 1, 2, 3 ], 1, 1 ] } [ 2 ]
{ $slice: [ [ 1, 2, 3 ], -2 ] } [ 2, 3 ]
{ $slice: [ [ 1, 2, 3 ], 15, 2 ] } [ ]
{ $slice: [ [ 1, 2, 3 ], -15, 2 ] } [ 1, 2 ]
返回一个布尔值,表示指定的值是否在数组中
{ $in: [ 2, [ 1, 2, 3 ] ] } true
{ $in: [ "abc", [ "xyz", "abc" ] ] } true
{ $in: [ "xy", [ "xyz", "abc" ] ] } false
{ $in: [ [ "a" ], [ "a" ] ] } false
{ $in: [ [ "a" ], [ [ "a" ] ] ] } true
{ $in: [ /^a/, [ "a" ] ] } false
{ $in: [ /^a/, [ /^a/ ] ] } true
【日期操作】
$dayOfYear 日(1-366) $dayOfMonth 月(1-23) $dayOfWeek 星期(1 (Sunday) 到 7 (Saturday)) $year 年 $month 月(1-12) $week 周(0-53) $hour 时(0-23) $minute 分(0-59) $second 秒(0-60) $millisecond 毫秒(0-999) $dateToString 返回格式化字符串的日期 $isoDayOfWeek 以ISO 8601格式返回星期几 $isoWeek 以ISO 8601格式返回周号,范围从1到53 $isoWeekYear 以ISO 8601格式返回年份编号

db.a.aggregate( [ { $project: { year: { $year: "$date" }, month: { $month: "$date" }, day: { $dayOfMonth: "$date" }, hour: { $hour: "$date" }, minutes: { $minute: "$date" }, seconds: { $second: "$date" }, milliseconds: { $millisecond: "$date" }, dayOfYear: { $dayOfYear: "$date" }, dayOfWeek: { $dayOfWeek: "$date" }, week: { $week: "$date" } } } ] )

【条件操作】
$cond 三元操作符 $ifNull 返回第一个表达式的非空结果或第二个表达式的结果 $switch switch操作符
如果qty>=250,返回true

如果qty是空,则result返回“是空的”,否则result=qty

switch操作符示例
{ $switch: { branches: [ { case: { $eq: [ 0, 5 ] }, then: "equals" }, { case: { $gt: [ 0, 5 ] }, then: "greater than" } ], default: "Did not match" } } "Did not match"
优化与限制
【优化】
默认情况下,整个集合作为聚合管道的输入,为了提高处理数据的效率,可以使用以下策略:
1、将 $match 和 $sort 放到管道的前面,可以给集合建立索引,来提高处理数据的效率
2、可以用 $match、$limit、$skip 对文档进行提前过滤,以减少后续处理文档的数量
3、当聚合管道执行命令时,MongoDB 也会对各个阶段自动进行优化,主要包括以下两种情况:
【1】$sort + $match 顺序优化。如果 $match 出现在 $sort 之后,优化器会自动把 $match 放到 $sort 前面
【2】$skip + $limit 顺序优化。如果 $skip 在 $limit 之后,优化器会把 $limit 移动到 $skip 的前面,移动后 $limit的值等于原来的值加上 $skip 的值
【限制】
对聚合管道的限制主要表现在对返回结果大小和内存的限制
1、返回结果大小
聚合结果返回的是一个文档,不能超过 16M,从 MongoDB 2.6版本以后,返回的结果可以是一个游标或者存储到集合中,返回的结果不受 16M 的限制。
2、内存
聚合管道的每个阶段最多只能用 100M 的内存,如果超过100M,会报错,如果需要处理大数据,可以使用 allowDiskUse 选项,存储到磁盘上
好的代码像粥一样,都是用时间熬出来的


