前端学HTTP之字符集


前面的话
HTTP报文中可以承载以任何语言表示的内容,就像它能承载图像、影片或任何类型的媒体那样。对HTTP来说,实体主体只是二进制信息的容器而已。为了支持国际性内容,服务器需要告知客户端每个文档的字母表和语言,这样客户端才能正确地把文档中的信息解包为字符并把内容呈现给用户,而要实现这个功能,需要用到接下来要详细介绍的字符集
首部概述
服务器通过HTTP协议的Content-Type首部中的charset参数和Content-Language首部告知客户端文档的字母表和语言。这些首部描述了实体主体的“信息盒子”里面装的是什么,如何把内容转换成合适的字符以便显示在屏幕上以及里面的词语表示的是哪种语言
同时,客户端需要告知服务器用户理解何种语言,浏览器上安装了何种字母表编码算法。客户端发送Accept-Charset首部和Accept-Language首部,告知服务器它理解哪些字符集编码算法和语言以及其中的优先顺序
下面的HTTP报文中的这些Accept首部可能是母语为法语的人发出的。他喜欢使用母语,但也会说一点儿英语,他的浏览器支持iso-8859-1 西欧字符集编码和UTF-8 Unicode字符集编码
Accept-Language: fr, en;q=0.8 Accept-Charset: iso-8859-l, utf-8
参数“q=0.8”是质量因子(quality factor),说明英语的优先级(0.8)比法语低(默认值是1.0)
编码过程
HTTP字符集的值说明如何把实体内容的二进制码转换为特定字母表中的字符。每个字符集标记都命名了一种把二进制码转换为字符的算法(反之亦然)。字符集标记在由IANA维护的MIME字符集注册机构进行了标准化。附录H中概述了其中的很多字符集
下面的Content-Type首部告知接收者,传输的内容是一份HTML文件,用charset参数告知接收者使用iso-8859-6阿拉伯字符集的解码算法把内容中的二进制码转换为字符:
Content-Type: text/html; charset=iso-8859-6
iso-8859-6的编码算法把8位值域映射为拉丁字母和阿拉伯字母,以及数字,标点和其他符号。例如,在下图中,突出显示的二进制码的值是225,它在iso-8859-6中被映射到阿拉伯字母“FEH”(读音类似英语字母F)

[注意]与汉语、日语不同的是,阿拉伯语中只有28个字符,8位空间有256个不同的值,足以容纳拉丁字符、 阿拉伯字符以及其他符号
有些字符编码(比如UTF-8和iso-2022-jp)更加复杂,它们是可变长(variable-length)编码,也就是说每个字符的位数都是可变的。这种类型的编码允许使用额外的二进制位表示拥有大量字符的字母表(比如汉语和日语),仅用较少的二进制位来表示标准的拉丁字符
我们想把文档中的二进制码转换为字符以便显示在屏幕上。但由于有很多不同的字母表,也有很多不同的方法把字符编码成二进制码(这些方法各有优缺点),我们需要一种标准方法来描述并应用把二进制码转换为字符的解码算法
把二进制码转换为字符要经过两个步骤,如下图所示
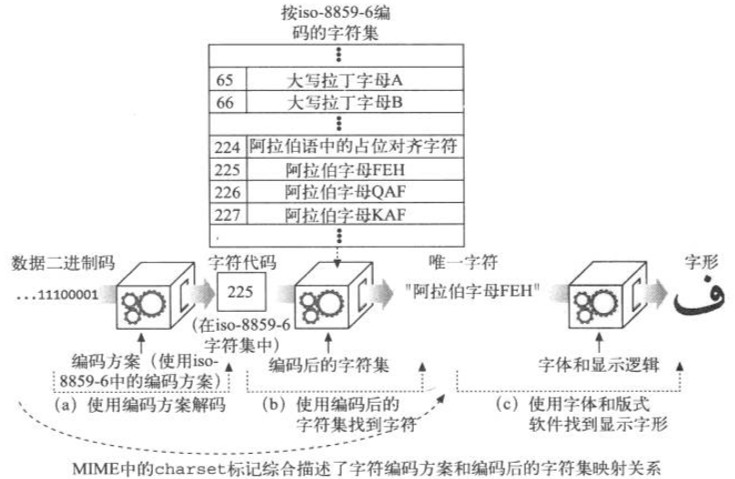
在图a中,文档中的二进制码被转换成字符代码,它表示了特定编码字符集 中某个特定编号的字符。在这个例子里,解码后的字符代码是数字编号225
在图b中,字符代码用于从编码的字符集中选择特定的元素。在iso-8859-6中,值225对应阿拉伯字母“FEH”。在步骤a和b中使用的算法取决于MIME的charset标记
国际化字符系统的关键目标是把语义(字母)和表示(图形化的显示形式)隔离开来。HTTP只关心字符数据和相关语言及字符集标签的传输。字符形状的显示是由用户的图形显示软件(包括浏览器、操作系统、字体等)完成的,如图c所示
如果客户端使用了错误的字符集参数,客户端就会显示一些奇怪的错乱字符。假设浏览器从主体中获得值225(二进制为11100001)
如果浏览器认为主体是用iso-8859-1西欧字符编码的,它将会显示带有重音符号的小写拉丁字母“a”
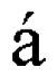
如果浏览器使用iso-8859-6阿拉伯编码,它将会显示阿拉伯字母“FEH”

如果浏览器使用iso-8859-7希腊编码,它将会显示小写的希腊字母“Alpha”
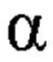
如果浏览器使用iso-8859-8希伯来编码,它将会显示希伯来字母“BET”

【标准化的MIME charset值】
特定的字符编码方案和特定的已编码字符集组合成一个MIME字符集(MIME charset)。HTTP在Content-Type和Accept-Charset首部中使用标准化的MIME charset标记。MIME charset的值都会在IANA注册
下表列出了文档和浏览器所使用的一些MIME charset编码方案

[注意]关于完整的已注册字符集内容请移步至此
Web服务器通过在Content-Type首部中使用charset参数把MIME字符集标记发送给客户端
Content-Type:text/html; charset=iso-2022-jp
如果没有显式地列出字符集,接收方可能就要设法从文档内容中推断出字符集。对于HTML内容来说,可以在描述charset的<meta HTTP-EQUIT="Content-Type">标记中找到字符集
下例中展示了HTML META标记如何把字符集设置为日语编码iso-2022-jp。如果文档不是HTML类型,或其中没有META Content-Type标记,软件可以设法扫描实际的文本,看看能否找出语言和编码的常见模式,以此推断字符编码
<head> <meta HTTP-EQUIT="Content-Type" content="text/html;charset=iso-2202-jp"> <meta lang="jp"> <title>Japanese</title> </head>
在过去的几十年间,人们开发了成千上万种字符编解码方法。大多数客户端不可能支持所有这些不同的字符编码和映射系统
HTTP客户端可以使用Accept-Charset请求首部来明确告知服务器它支持哪些字符系统。Accept-Charset首部的值列出了客户端支持的字符编码方案。例如,下面的HTTP请求首部表明,客户端接受西欧字符系统iso-8859-1和UTF-8变长的Unicode兼容系统。服务器可以随便选择这两种字符编码方案之一来返回内容
Accept-Charset: iso-8859-1, utf-8
[注意]没有Content-Charset这样的响应首部和Accept-Charset请求首部匹配。为了和MIME标准兼容,响应的字符集是由服务器通过Content-Type响应首部的charset参数带回来的。不对称真是太糟了,不过需要的信息倒是都有了
编码语法
【术语】
以下是应当了解的电子化字符系统的8个术语
1、字符
字符是指字母、数字、标点、表意文字(比如汉语)、符号,或其他文本形式的书写“原子”。由统一字符集(Universal Character Set, UCS,它的非正式的名字是Unicode3)首创,为多种语言中的很多字符开发了一系列标准化的文本名称,它们常用来便捷地命名字符,而且不会与其他字符冲突
2、字形
描述字符的笔画图案或唯一的图形化形状。如果一个字符有多种不同的写法,就有多个字形
3、编码后的字符
分配给字符的唯一数字编号,这样我们就可以操作它了
4、代码空间
计划用于字符代码值的整数范围
5、代码宽度
每个固定大小的字符代码所用的位数
6、字符库
特定的工作字符集,相当于全体字符的一个子集
7、编码后的字符集
组成字符库(从全球的字符中选出若干字符)的已编码字符集,并为每个字符分配代码空间中的一个代码。换句话说,它把数字化的字符代码映射为实际的字符
8、字符编码方案
把数字化的字符代码编码成一系列二进制码(并能相应地反向解码)的算法。字符编码方案可用来减少识别字符所需要的数据总量(压缩)、解决传输限制、统一重叠编码字符集
【糟糕的命名】
从技术上说,MIME中的charset标记(用在Content-Type首部的charset参数中和Accept-Charset首部中)描述的压根就不是字符集。MIME中的charset值所命名的是把数据位映射为唯一的字符的一整套算法。它是字符编码方案(character encoding scheme)和编码后的字符集(coded character set)这两种概念的组合
因为关于字符编码方案和编码后的字符集方面的标准都已经发布过了,所以,这个术语的使用是很草率的,很容易引起混淆。下面是HTTP/1.1的作者们对于他们如何使用这些术语的介绍
术语“字符集”在本文档中是指一种方法,它可以把一系列8位字节转换为一系列字符。注意:术语“字符集”经常被称为“字符编码”。但由于HTTP和MIME共享同样的注册信息,术语也能共享是很重要的
IETF在RFC 2277中也采用了非标准的术语:
本文档中使用术语“字符集”来表示一组把一系列8位字节转换为一系列字符的规则的集合,比如编码后的字符集与字符编码方案的组合。这与MIME的“charset=”参数中标识符的用法相同,并且已在IANA的字符集注册表中注册。(注意这不是在其他标准主体,比如在国际标准化组织ISO中使用的术语)
[注意]更糟糕的是,MIME中的charset标记经常会从特定的编码后字符集的名称或编码方案的名称里面选取。例如,iso-8859-1是一个编码后字符集(它为一个包含256个欧洲字符的集合分配了数字化的代码),但MIME用charset值iso-8859-1来表示一种8位的、对编码后的字符集恒等的编码。这种不精确的术语并不是致命的问題,但在阅读标准文档的时候,需要对其假设用法保持清醒的头脑
因此,在阅读标准文档的时候,要保持清醒,这样才能确切地知道它所定义的到底是什么
【字符】
字符是书写的最基本的构建单元。字符可以表示字母、数字、标点、表意符号(比如在汉语中)、数学符号,或其他书写的基本单元
字符和字体以及风格无关。下图显示了同一个字符(UCS中的命名是LATIN SMALL LETTER A)的若干变体。尽管它们的笔画图案和风格有很大的不同,但母语是西欧语言的读者都能立刻辨认出这5个形状是同一个字符

在很多书面语体系中,根据一个字符在单词中位置的不同,同一个字符也会有不同的笔画形状。例如,下图中的4种笔画都表示字符ARABIC LETTER AIN

图a显示了AIN作为一个单独的字符时是如何书写的。图d显示的是AIN在单词开头时的情形。图c显示了AIN在单词中间的情形,而图b显示的是AIN在单词结尾处的情形
【字形】
不要把字符和字形混淆。字符是唯一的、抽象的语言“原子”。字形是画出每个字符时使用的特定方式。根据艺术形式和手法的不同,每个字符可以有很多不同的字形
同样,也不要把字符与表示形式混淆起来。为了让书法作品更好看,很多手写体和字体允许人们把相邻的字符漂亮地连写起来,称为连笔(ligatures),这样两个字符就平滑地连接在一起了。母语为英语的作者常把F和I结合为FI连笔,而阿拉伯语的作者常把字符“LAM”和“ALIF”结合为一种很优雅的连笔

这里给出一般的规则:如果用一种字形替代另一种的时候,文本的意思变了,那这些字形就是不同的字符。否则,它们就是同一个字符的不同风格的表示形式
【编码后的字符集】
根据RFC 2277和2130的定义,编码后的字符集把整数映射到字符。编码后的字符集经常用数组来实现,通过代码数值来索引。数组的元素就是字符

下面我们来看一些重要的编码后的字符集标准,包括具有历史意义的US-ASCII字符集、ASCII的iso-8859扩展、日文的JIS X 0201字符集以及统一字符集(Universal Character Set, Unicode)
1、US-ASCII:所有字符集的始祖
ASCII是最著名的编码后字符集,早在1968年就由ANSI在标准X3.4,“美国标准信息交换代码”(American Standard Code for Information Interchange)中进行了标准化。ASCII的代码值只是从0到127,因此只需要7个二进制码就可以覆盖代码空间。ASCII的推荐名称是US-ASCU,这样可以和那些7位字符集的一些国际化变体区分开来。HTTP报文(首部,URI等)使用的字符集是US-ASCII
2、iso-8859
iso-8859字符集标准是US-ASCII的8位超集,使用二进制码的高位增加了一些国际化书面字符。由额外的二进制码提供的附加空间(多了128个代码)还不够大,甚至都不够所有的欧洲字符使用,更不用说亚洲字符了。因此iso-8859为不同地区定制了不同的字符集,如下所示

iso-8859-1 西欧语言(例如,英语、法语) iso-8859-2 中欧和东欧语言(例如,捷克、波兰) iso-8859-3 南欧语言 iso-8859-4 北欧语言(例如,拉托维亚,立陶宛,格陵兰} iso-8859-5 斯拉夫语(例如,保加利亚、俄罗斯、塞尔维亚) iso-8859-6 阿拉伯语 iso-8859-7 希腊语 iso-8859-8 希伯来语 iso-8859-9 土耳其语 iso-8859-10 日耳曼和斯堪的纳维亚语言(例如,冰岛、因纽特) iso-8859-15 对iso-8859-1的修改,包括了新的欧元字符
iso-8859-1也称为Latin1,是HTML的默认字符集。可以用它来表示大多数西欧语言的文本。因为iso-8859-15中包含了新的欧元符号,有过一些用它来代替iso-8859-1并作为HTTP默认编码后字符集的讨论。然而,由于iso-8859-1已经被广泛采用,要大范围地变更到iso-8859-15恐怕不是短时间内可以完成的
3、JIS X 0201
JIS X 0201是把ASCII扩展到日文半宽片假名字符的一个极小化的字符集。半宽片假名字符最早用在日文电报系统中。JISX 0201常常被称作JIS Roman,JIS是 “Japanese Industrial Standard”(日文工业化标准)的缩写
4、JIS X 0208与JIS X 0212
日文中包括数千个来自几个书面语系统中的字符。尽管可以勉强只使用JIS X 0201中的那63个基本的片假名字符,但实际使用中需要远比这个更完整的字符集
JIS X 0208字符集是首个多字节日文字符集,它定义了6879个编码的字符,其中大多数是来源于中文的日本汉字。JIS X 0212字符集又扩充了6067个字符
5、UCS
UCS(Universal Character Set,统一字符集)是把全世界的所有字符整合到单一的编码后字符集的环球标准化成果。UCS由ISO 10646定义。Unicode是遵循UCS标准的商业化联合组织。UCS具有能容纳百万以上字符的代码空间,不过基本集合只有大约5万个字符
【字符编码方案】
字符编码方案规定如何把字符的代码数字打包装入内容比特,以及在另一端如何将其解包回字符代码

字符编码方案有以下3种主要类型
1、固定宽度
固定宽度方式的编码用固定数量的比特表示每个编码后的字符。它们能被快速处理,但可能会浪费空间
2、可变宽度(无模态)
可变宽度方式的编码对不同的字符代码数字采用不同数量的比特。对于常用字符,这样可以减少需要的位数,而且还能在允许使用多字节来表示国际性字符的同时,保持对传统8位字符集的兼容性
3、可变宽度(有模态)
有模态的编码使用特殊的“转义”模式在不同的模态之间切换。例如,可以用有模态的编码在文本中使用多个互相有重叠的字符集。有模态的编码处理起来比较复杂,但它们可以有效地支持复杂的书写系统
下面我们来看一些常见的编码方案
1、8位
8位固定宽度恒等编码把每个字符代码编码为相应的8位二进制值。它只能支持有256个字符代码范围的字符集。iso-8859字符集家族系列使用的就是8位恒等编码
2、UTF-8
UTF-8是一种流行的为UCS设计的字符编码方案,UTF表示UCS变换格式(UCS Transformation Format)。UTF-8为字符代码值使用的是无模态的变宽编码,第一字节的高位表示编码后的字符所用的字节数,所需的每个后续字节都含有6位的代码值
如果编码后的第1字节的最高位是0,长度就是1字节,剩余的7位就包含字符的代码。这样带来的美妙结果就是和ASCII兼容(但和iso-8859系列不兼容,因为iso-8859系列使用了最高位)
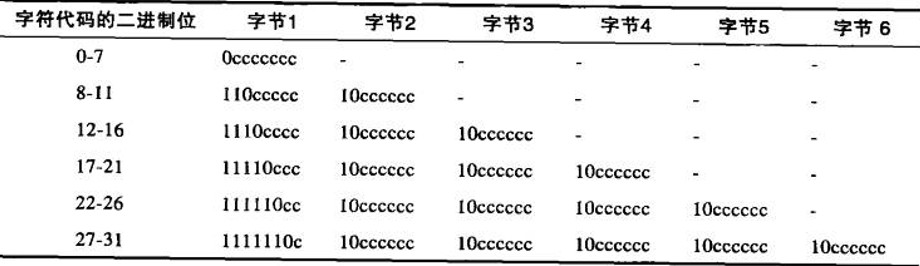
例如,字符代码90(ASCII的“Z”)会被编码为1个字节(01011010),而代码5073(13位二进制值为1001111010001)会被编码为3个字节:11100001 10001111 10010001
3、iso-2022-jp
iso-2022-jp是互联网上的日文文档中广泛使用的编码。它是变宽、有模态的,所有值都不超过128,以避免和不支持8位字符的软件出现兼容性问题
编码上下文始终被设置为4种预设的字符集之一,使用特殊的“转义序列” (escape sequence)在字符集之间切换。iso-2022-jp的初始状态使用US-ASCII字符集,使用3个字节的转义序列可以切换到JIS X 0201(JIS-Roman)字符集或大得多的JIS X 0208-1978和JIS X 0208-1983字符集
下表中列出了这些转义序列。实际上,日文文本以ESC @或ESC B 开始,以ESC(B或ESC(J结束

在US-ASCII或JIS-Roman模态下,每个字符使用单个字节。当使用更大的JISX 0208系列的字符集时,每个字符代码使用2个字节。该编码把发送的字节的值域范围限制在33~126之间
4、euc-jp
euc-jp是另一种流行的日文编码。EUC代表“Extended Unix Code”(扩展Unix代码),最早是为了在Unix操作系统上支持亚洲字符而开发的
和iso-2022-jp类似,euc-jp编码也是变长的,允许使用几种标准的日文字符集。但和iso-2022-jp不同的是,euc-jp编码不是模态的。没有转义序列可以在不同模态之间切换
euc-jp支持4种编码后的字符集:JIS X 0201(JIS-Roman,对ASCII进行一些日文替换)、JIS X 0208、半宽片假名(最早在日文电报系统中使用的63个字符)以及JIS X 0212
编码JIS Roman(它和ASCII兼容)的时候使用1个字节,对JIS X 0208和半宽片假名则使用2个字节,而对JIS X 0212使用3个字节。这种编码有点浪费空间但处理起来很简单
下表概括了此编码的格局

语言标记
语言标记是命名口语的标准化字符串短语
名字需要标准化,不然的话,有些人会把法语文档打上French标记,而有些其他人会用Francis,还有些人可能会用France,更有些懒人可能会用Fra甚至是F。标准化语言标记就可以避免这些混乱
英语的标记是en,德语的标记是de,韩语的标记是ko,等等。语言标记能够描述语言的地区变种和方言,比如巴西葡萄牙语的标记是pt-BR、美式英语的标记是en-US,汉语中的湖南话的标记是zh-xiang。甚至还有个标准语言标记i-klingon是描述克林根语的
实体的Content-Language首部字段描述实体的目标受众语言。如果内容主要是给法语受众的,其Content-Language首部字段就将包含:
Content-Language:fr
Content-Language首部不仅限于文本文档。音频片段、电影以及应用程序都有可能是面向特定语言受众的。任何面向特定语言受众的媒体类型都可以有Content-Language首部。在下图中,音频文件标记为面向纳瓦霍(Navajo)听众

如果内容是面向多种语言受众的,可以列出多种语言。就像在HTTP规范中建议的,一份同时用英语和毛利语写的“Treaty of Waitangi”(怀唐伊条约)译稿,可以这样描述:
Content-Language:mi, en
不过,不能仅根据有多种语言在实体中出现就认为它是面向多种语言受众的。为初学者编写的语言入门教材,比如“A First Lesson in Latin”(拉丁语第一课),显然是为英语受众准备的,应当只用en来描述
我们绝大多数人至少懂一种语言。HTTP允许我们把语言方面的限制和优先选择都发送给网站服务器。如果网站服务器有以多种语言表示的资源版本,它就能把内容用我们最优选的语言表示出来
客户端请求西班牙语内容:
Accept-Language:es
可以在Accept-Language首部中放入多个语言标记以枚举所支持的全部语言及其优先顺序(从左到右)。客户端首选英语,但也接受瑞士德语(标准语言标记是de-CH)或其他德语变种(标记是de):
Accept-Language:en, de-CH, de
客户端使用Accept-Language首部和Accept-Charset首部请求可以理解的内 容
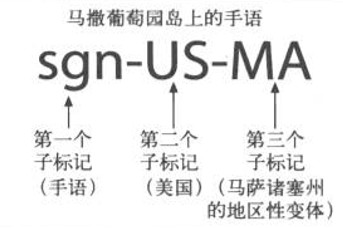
在RFC 3066,“Tags for the Identification of Languages”(标识语言的标记)中记录了语言标记的标准化语法。可以用语言标记来表示:一般的语言分类(比如es代表西班牙语);特定国家的语言(比如en-GB代表英国英语);语言的方言(比如no-bok指挪威的书面语);地区性的语言(比如sgn-US-MA代表美国马撒葡萄园岛上的手语);标准化的非变种语言(比如i-navajo);非标准的语言(比如 x-snowboarder-slang)
语言标记有一个或多个部分,用连字号分隔,称为子标记:
第一个子标记称为主子标记,其值是标准化的;第二个子标记是可选的,遵循它自己的命名标准;其他尾随的子标记都是未注册的
主子标记中只能含有字母(A-Z)。其后的子标记可以含有字母和数字,长度最多8个字符
下图中给出了一个示例
所有的标记都是不区分大小写的,也就是说,标记en和eN是等价的。但是,习惯上用全小写来表示一般的语言,而用全大写来表示特定的国家。例如,fr表示所有分类为法语的语言,而FR表示国家法国
第一个和第二个语言子标记的值由各种标准文档以及相关的维护组织定义。IANA依据RFC 3066中概括的规则来管理标准的语言标记列表
如果语言标记由标准的国家和语言值组成,标记就不需要专门注册。只有那些无法用标准的国家和语言值构成的语言标记才需要专门向IANA注册
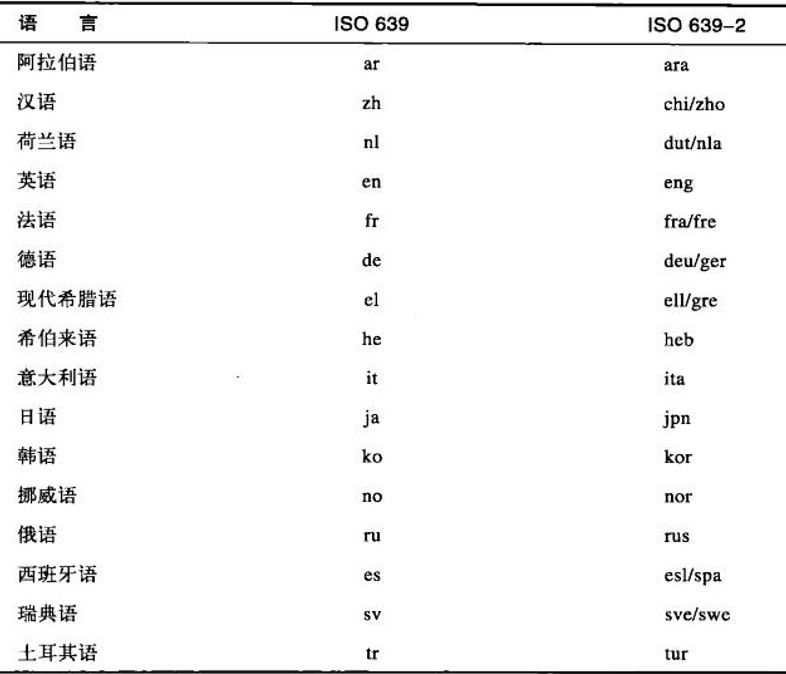
第一个子标记通常是标准化的语言记号,选自ISO 639中的语言标准集合。不过也可以用字母i来标识在IANA中注册的名字,或用x表示私有的或者扩展的名字,下面是各种规则
如果第一个子标记含有2个字符,那就是来自ISO 639和639-1标准的语言代码;如果含有3个字符,那就是来自ISO 639-223标准及其扩展的语言代码;如果是字母i,则表示该语言标记是在IANA显式注册的;如果是字母x,则表示该语言标记是私有的、非标准的,或扩展的子标记
下表中给出了一些示例
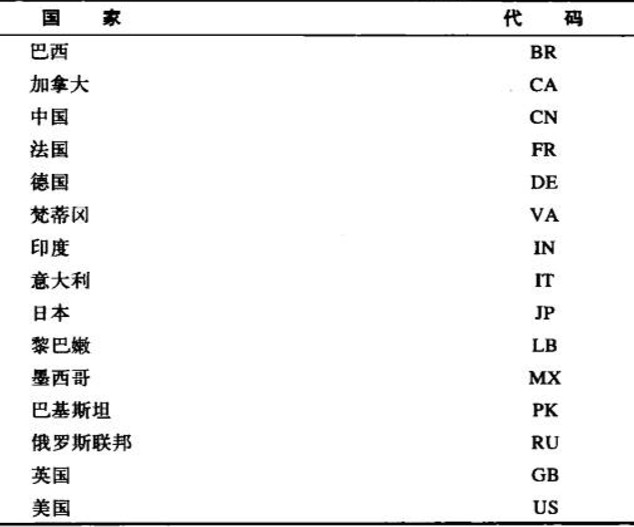
第二个子标记通常是标准化的国家记号,选自ISO 3166中的国家代码和地区标准集合。不过也可以是在IANA注册过的其他字符串,下面是各种规则。
如果第二个子标记含有2个字符,那就是ISO 3166中定义的国家/地区;如果含有3-8个字符,可能是在IANA中注册的值;如果是单个字符,这是非法的情况
下表中列出了ISO 3166中的部分国家代码
除了最长可以到8个字符(字母和数字)之外,第三个和其后的子标记没有特殊规则
国际化URI
直到今天,URI还没有为国际化提供足够的支持。除了少数(定义得很糟的)例外,URI如今还是由US-ASCII字符的一个子集组成的。人们正在努力使主机名和URL的路径中能包含更丰富的集合中的字符,但直到现在,这些标准还没有被广泛接受和部署
URI的设计者们希望世界上每个人都能通过电子邮件、电话、公告板,甚至无线电来共享URI。他们还希望URI容易使用和记忆,但这两个目标是相互冲突的
为了让世界各地的人们都能够便捷地输入、操控,以及共享URI,设计者们为URI选择了常用字符的一个很有限的子集(基本的拉丁字母表中的字母、数字以及少数特殊符号)。世界上绝大多数软件和键盘都支持这个小的字符集合
但不幸的是,限制了字符集的话,URI就无法被全球的人们方便地使用和记忆。世界上有很大一部分人甚至都不认识拉丁字母,他们几乎无法把URI当作抽象模式来记忆
URI的设计者们觉得确保资源标识符的可转抄能力(transcribability)和共享能力比让它们由最有意义的字符组成更加重要。因此,如今的URI基本上是由ASCII字符的受限子集构成的
URI中允许出现的US-ASCII字符的子集,可以被分成保留、未保留以及转义字符这几类。未保留的字符可用于URI允许其出现的任何部分。保留的字符在很多URI中都有特殊的含义,因此一般来说不能使用它们
下表中列出了全部未保留、保留,以及转义字符

【转义】
URI转义提供了一种安全的方式,可以在URI内部插入保留字符以及原本不支持的字符(比如各种空白)。每个转义是一组3字符序列,由百分号(%)后面跟上两个十六进制数字的字符。这两个十六进制数字就表示一个US-ASCII字符的代码
例如,要在URL中插入一个空白(ASCII 32),可以用转义%20,因为20是32的十六进制表示。类似地,如果想插入一个百分号并且不想让它被当作转义,就可以输入%25,25是百分号的ASCII代码的十六进制值
下图展示了URI中的概念性字符是如何转换为当前字符集中字符的代码字节的。需要处理URI时,转义会被反转义回来,产生它们代表的ASCII代码的字节
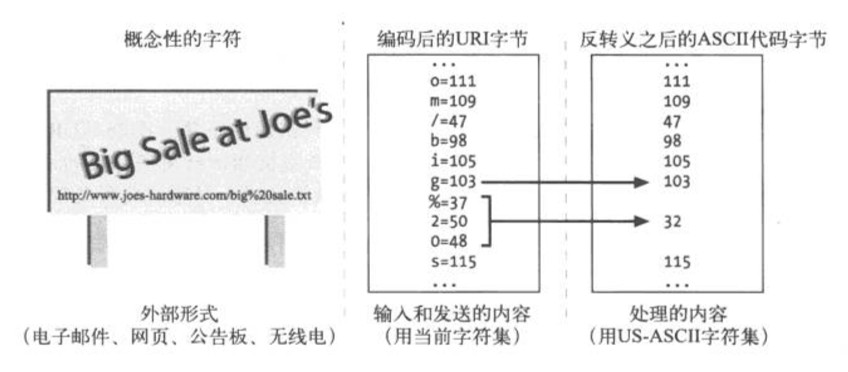
在内部处理时,HTTP应用程序应当在传输和转发URI的时候保持转义不变。HTTP应用程序应该仅在需要数据的时候才对URI进行转义。更重要的是,应用程序应该确保任何URI都不会被反转义2次,因为在转义的时候可能会把百分号编码进去,反转义出来之后,再转一次就会导致数据丢失
需要注意的是,要转义的值本身应该在US-ASCII代码值的范围内(0~127)。某些应用程序试图用转义值来表示iso-8859-l中扩展的字符(代码范围在128-
255)。例如,网站服务器可能会错误地用转义来对包含了国际字符的文件名进行编码。这样做是不对的,可能会使别的应用出问题
例如,文件名Sven Olssen.html(包含了一个元音变音)可能被网站服务器编码为 Sven%20%D6lssen.html。把空格编码为%20是对的,但从技术上说,把O编码为%D6是非法的,因为代码D6(十进制值214)落在了ASCII代码范围之外。ASCII只定义了最大值为0X7F(十进制值127)的代码
【模态切换】
有些URI也用ASCII字符的序列来表示其他字符集中的字符。例如,可能使用iso-2022-jp编码插入“ESC(J”,切换到JIS-Roman字符集,用“ESC(B”切换回ASCII字符集。这在一些本地化的环境中可以工作,但这种方式没有进行良好的定义,而且没有标准化的方案来识别URL所使用的特定编码。正如RFC 2396的作者所说的那样:
对于含有非ASCII字符的原始字符序列来说,境况复杂。如果可能用到多个字符集的活,传输表示字符序列的8位字节序列的因特网协议期待能有办法来识别所用的字符集[RFC 2277]
然而,在通用的URI语法中没有提供进行这种识别的手段。个别的URI方案可以请求单一的字符集,定义默认的字符集,或提供指示所用字符集的方法。期待将来对这个规范的修改能为URI中的字符编码提供一种系统化的处理方案
目前,URI对国际化应用还不是非常友好。URI的可移植性目标比语言灵活性方面的目标更重要。人们正在尽最大努力使URI更加国际化,但在短期内,HTTP应用程序还是应当坚持使用ASCII。它从1968年就出现了,所以只用它的话,一切还不至于太糟
注意事项
HTTP首部必须由US-ASCII字符集中的字符构成。不过,并不是所有的客户端和服务器都正确地实现了这一点,可能会时不时收到一些代码值大于127的非法字符
很多HTTP应用程序使用操作系统和库例程来处理字符(比如Unix中的字符分类库ctype),但不是所有这些库都支持ASCII范围(0-127)之外的字符代码
在某些情况下(一般来说,是较老的实现),当输入非ASCII字符时,这些库可能会返回不正确的结果,或者使应用程序崩溃。假设报文中含有非法数据,在使用这些字符分类库来处理HTTP报文之前,要仔细阅读它们的文档
HTTP的规范中明确定义了合法的GMT日期格式,但要知道并非所有Web服务器和客户端都遵守这些规则。例如,我们曾见过Web服务器发送的无效HTTP Date(日期)首部中的月份是用本地语言表示的
HTTP应用程序应当尝试容忍一些不合规矩的日期,不能在接收的时候崩溃。不过也不是所有发送出来的日期都能被正确解释,如果日期无法解析,服务器应当谨慎处理
DNS目前还不支持在域名中使用国际化的字符。现在正在进行支持多语言的域名的相关标准化工作,但还没有被广泛部署
好的代码像粥一样,都是用时间熬出来的




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?