Implementing a data access layer of an application has been cumbersome for quite a while. Too much boilerplate code had to be written. Domain classes were anemic and haven't been designed in a real object oriented or domain driven manner.
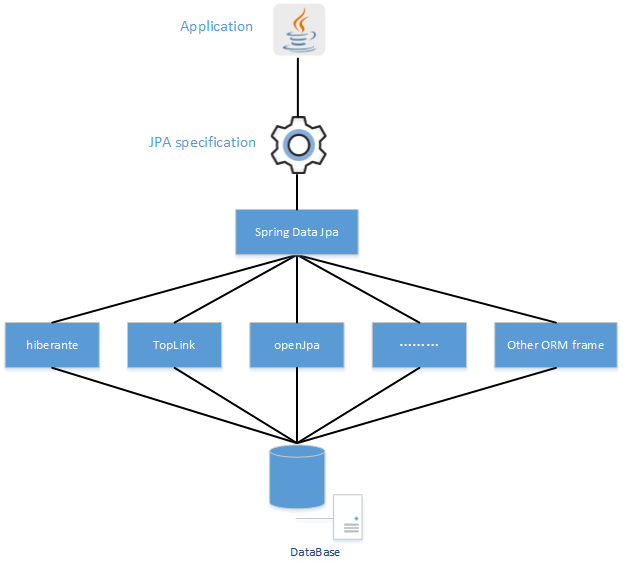
Using both of these technologies makes developers life a lot easier regarding rich domain model's persistence. Nevertheless the amount of boilerplate code to implement repositories especially is still quite high. So the goal of the repository abstraction of Spring Data is to reduce the effort to implement data access layers for various persistence stores significantly.
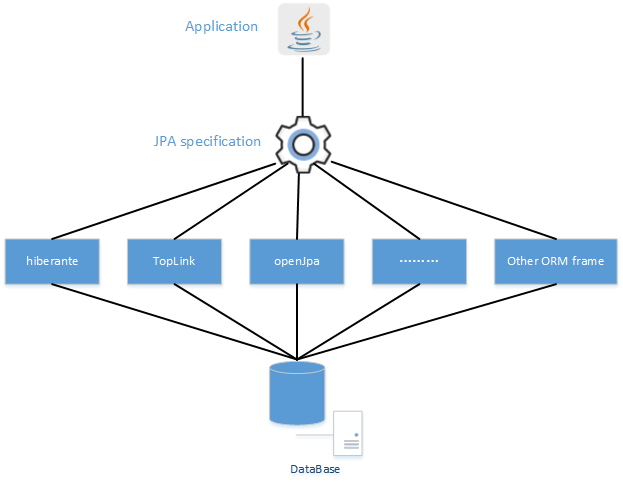
Long story short, then, Spring Data JPA provides a definition to implement repositories that is supported under the hood by referencing the JPA specification, using the provider you define.
长话短说,Spring Data JPA 是在JPA规范的基础下提供了Repository层的实现,但是使用那一款ORM需要你自己去决定。
我的理解是:虽然ORM框架都实现了JPA规范,但是在不同ORM框架之间切换是需要编写的代码有一些差异,而通过使用Spring Data Jpa能够方便大家在不同的ORM框架中间进行切换而不要更改代码。并且Spring Data Jpa对Repository层封装的很好,可以省去不少的麻烦。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步