




RabbitMQ安装
Linux安装,环境centos6.6
1 安装配置epel源 2 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 3 4 机子给配上163的源了,所以直接 5 $ yum install epel-release 6 7 因为RabbitMQ是由erlang实现的,所以要安装erlang 8 $ yum -y install erlang 9 10 安装RabbitMQ 11 $ yum -y install rabbitmq-server 12 13 启动RabbitMQ 14 $ /etc/init.d/rabbitmq-server start/stop
安装Python API
1 pip3 install pika 2 or 3 easy_install pika
基于queue的生产消费者模型
1 #!/usr/bin/env python3 2 #coding:utf8 3 import queue 4 import threading 5 message = queue.Queue(10) 6 def producer(i): 7 '''生产腿堡放入队列''' 8 while True: 9 message.put(i) 10 print("%s放入队列%s" % (threading.current_thread().name, i)) 11 def consumer(i): 12 '''消费者,从队列中取腿堡吃''' 13 while True: 14 msg = message.get() 15 print("%s从队列总取出%s" % (threading.current_thread().name, msg)) 16 17 if __name__ == '__main__': 18 19 for i in range(12): # 生产者的线程腿堡 20 t = threading.Thread(target=producer, args=(i,)) 21 t.start() 22 for i in range(10): # 消费者的线程吃腿堡 23 t = threading.Thread(target=consumer, args=(i,)) 24 t.start()
RabbitMQ 使用
- 生产者代码
1 #!/usr/bin/env python 3 2 import pika 3 ######### 生产者 ######### 4 #链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址) 5 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 6 #创建频道 7 channel = connection.channel() 8 #创建一个队列名叫test 9 channel.queue_declare(queue='test') 10 11 # channel.basic_publish向队列中发送信息 12 # exchange -- 它使我们能够确切地指定消息应该到哪个队列去。 13 # routing_key 指定向哪个队列中发送消息 14 # body是要插入的内容, 字符串格式 15 16 while True: # 循环向队列中发送信息,quit退出程序 17 inp = input(">>>").strip() 18 if inp == 'quit': 19 break 20 channel.basic_publish(exchange='', 21 routing_key='test', 22 body=inp) 23 print("生产者向队列发送信息%s" % inp) 24 25 #缓冲区已经flush而且消息已经确认发送到了RabbitMQ中,关闭链接 26 connection.close() 27 28 # 输出结果 29 >>>python 30 生产者向队列发送信息python 31 >>>quit
- 消费者代码
1 #!/usr/bin/env python 3 2 import pika 3 ######### 消费者 ######### 4 # 链接rabbit 5 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 6 # 创建频道 7 channel = connection.channel() 8 # 如果生产者没有运行创建队列,那么消费者也许就找不到队列了。为了避免这个问题,所有消费者也创建这个队列,如果队列已经存在,则这条无效 9 channel.queue_declare(queue='test') 10 #接收消息需要使用callback这个函数来接收,他会被pika库来调用,接受到的数据都是字节类型的 11 def callback(ch, method, properties, body): 12 """ 13 ch : 代表 channel 14 method :队列名 15 properties : 连接rabbitmq时设置的属性 16 body : 从队列中取到的内容,获取到的数据时字节类型 17 """ 18 print(" [x] Received %r" % body) 19 # channel.basic_consume 表示从队列中取数据,如果拿到数据 那么将执行callback函数,callback是回调函数 20 # no_ack=True 表示消费完这个消息以后不主动把完成状态通知rabbitmq 21 channel.basic_consume(callback, 22 queue='test', 23 no_ack=True) 24 print(' [*] 等待信息. To exit press CTRL+C') 25 #永远循环等待数据处理和callback处理的数据,start_consuming方法会阻塞循环执行 26 channel.start_consuming() 27 28 # 输出结果,一直等待处理队列中的消息,不知终止,除非人为ctrl+c 29 [*]等待消息,To exit press CTRL+C 30 [x] Received b'python'
acknowledgment 消息不丢失的方法
- 生产者,代码同上,未改变
- 消费者代码
1 import pika 2 import time 3 # 链接rabbit 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 # 创建频道 6 channel = connection.channel() 7 # 如果生产者没有运行创建队列,那么消费者创建队列,如果队列已存在,创建队列操作会被忽略 8 channel.queue_declare(queue='hello') 9 # 回调函数 10 def callback(ch, method, properties, body): 11 print(" [x] Received %r" % body) 12 time.sleep(10) 13 print('ok' ) 14 ch.basic_ack(delivery_tag = method.delivery_tag) # 当上面消息处理完成后,通知rabbitmq,消息处理完成,不要在发送了 15 16 channel.basic_consume(callback, 17 queue='hello', 18 no_ack=False) # 表示消费完这个消息后,主动通知rabbitmq完成状态,如果不通知,rabbitmq会把这条消息重新放回队列中,避免丢失 19 20 print(' [*] Waiting for messages. To exit press CTRL+C') 21 channel.start_consuming()
当生产者生成一条数据,被消费者接收,消费者中断后如果不超过10秒,连接的时候数据还在。当超过10秒后,重新连接,数据将消失。消费者等待连接。
durable 消息不丢失(消息持久化)
这个queue_declare 需要在 生产者(product)和消费者(consumer)代码中都进行设置。
- 生产者代码
1 #!/usr/bin/env python 2 import pika 3 # 链接rabbit服务器 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 # 创建频道 6 channel = connection.channel() 7 # 创建队列,使用durable方法 8 channel.queue_declare(queue='test', durable=True) 9 # 如果想让队列实现持久化那么加上durable=True 10 channel.basic_publish(exchange='', 11 routing_key='test', 12 body='Hello World!', 13 properties=pika.BasicProperties( 14 delivery_mode=2, 15 # 标记我们的消息为持久化的 - 通过设置 delivery_mode 属性为 2,在生产者端持久化 16 )) 17 # 这个exchange参数就是这个exchange的名字. 空字符串标识默认的或者匿名的exchange:如果存在routing_key, 消息路由到routing_key指定的队列中。 18 print(" [x] 开始队列'") 19 connection.close()
- 消费者代码
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import pika 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 # 创建频道 6 channel = connection.channel() 7 # 创建队列,使用durable方法,durable=True 开启持久化 8 channel.queue_declare(queue='test', durable=True) 9 10 11 def callback(ch, method, properties, body): 12 print(" [x] Received %r" % body) 13 import time 14 time.sleep(10) 15 print('ok') 16 ch.basic_ack(delivery_tag = method.delivery_tag) 17 18 channel.basic_consume(callback, 19 queue='hello', 20 no_ack=False) 21 22 print(' [*] 等待队列. To exit press CTRL+C') 23 channel.start_consuming()
备注:标记消息为持久化的并不能完全保证消息不会丢失,尽管告诉RabbitMQ保存消息到磁盘,当RabbitMQ接收到消息还没有保存的时候仍然有一个短暂的时间窗口,RabbitMQ不会对每个消息都执行同步fsync(2),可能只是保存到缓存cache还没有写入到磁盘中,这个持久化保证不是很强,但这比我们简单的任务queue要好得多,如果你想要很稳定的消息不丢失,可以使用publisher confirms。
消息顺序获取
默认消息队列里的数据是按照顺序被消费者拿走,例如,消费者1去队列中获取奇数序列任务(分别取任务1,3,5,7),消费者2去队列中获取偶数序列任务(分别取任务2,4,6,8)。如果消费者1处理的任务速度很快,当他完成1,3任务后,消费者2可能2任务还没有处理完,但是消费者1会继续按照排序去取第5个任务而不是第4个任务,完成第五个任务,在执行第七个任务。为了改变这种默认的取任务排序,需要改变参数channel.basic_qos(prefetch_count=1)表示谁来谁取,不在按照奇偶数排列。
- 生产者代码
1 #!/usr/bin/env python3 2 # -*- coding:utf-8 -*- 3 import pika 4 import sys 5 6 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 7 channel = connection.channel() 8 # 设置队列为持久化的队列 9 channel.queue_declare(queue='task_queue', durable=True) 10 message = ' '.join(sys.argv[1:]) or "Hello World!" 11 channel.basic_publish(exchange='', 12 routing_key='task_queue', 13 body=message, 14 properties=pika.BasicProperties( 15 delivery_mode = 2, # 设置消息为持久化的 16 )) 17 print(" [x] Sent %r" % message) 18 connection.close()
- 消费者代码
1 #!/usr/bin/env python 3 2 # -*- coding:utf-8 -*- 3 import pika 4 import time 5 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 6 channel = connection.channel() 7 channel.queue_declare(queue='task_queue',durable=True) # 设置队列持久化 8 9 def callback(ch, method, properties, body): 10 print(" [x] Received %r" % body) 11 time.sleep(10) 12 print('ok') 13 ch.basic_ack(delivery_tag = method.delivery_tag) 14 15 channel.basic_qos(prefetch_count=1) # 表示谁来谁取,不在按照奇偶数排序 16 17 channel.basic_consume(callback, 18 queue='task_queue', 19 no_ack=False) 20 21 print(' [*] Waiting for messages. To exit press CTRL+C') 22 channel.start_consuming()
发布订阅
- fanout : 所有bind到此exchange的queue都可以接受消息
- direct : 通过routingkey和exchange决定的那个唯一的queue可以接受消息
- topic : 所有符合routingkey(一个表达式)的routingkey所bind的queue
当我们向队列里发送消息时,其实并不是自己直接放入队列中的,而是先交给exchange,然后由exchange放入指定的队列中。想象下当我们要将一条消息发送到多个队列中的时候,如果没有exchange,我们需要发送多条到不同的队列中,但是如果有了exchange,它会先和目标队列建立一种绑定关系,当我们把一条消息发送到exchange中的时候,exchange会根据之前和队列的绑定关系,将这条消息发送到所有与它有绑定关系的队里中。
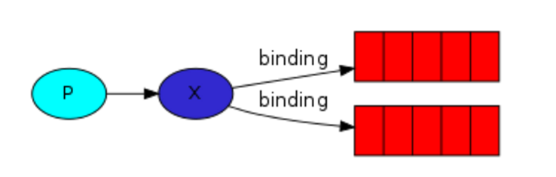
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失了。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,二发布者发布消息时,会将消息放置在所有相关队列中。发布订阅本质上就是发布端将消息发送给了exchange,exchange将消息发送给与它绑定关系的所有队列。
exchange type = fanout 和exchange绑定关系的所有队列都会收到信息
- 发布者代码
1 #!/usr/bin/env python3 2 import pika 3 import sys 4 5 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 6 channel = connection.channel() 7 8 channel.exchange_declare(exchange='logs', type='fanout') # 创建了一个exchange名字叫logs,type=fanout。有了exchange,我们就不需要去创建队列了 9 10 message = ' '.join(sys.argv[1:]) or "info: Hello World!" 11 channel.basic_publish(exchange='logs', routing_key='', body=message) # 指定了exchange后,就不需要指定队列了,所有routing_key='' 12 13 print(" [x] Sent %r" % message) 14 connection.close()
- 订阅者代码
1 #!/usr/bin/env python3 2 import pika 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 5 channel = connection.channel() 6 7 channel.exchange_declare(exchange='logs', type='fanout') # 创建exchange 8 9 result = channel.queue_declare(exclusive=True) # 不指定queue名字,随机生成一个唯一的queue,队列断开后自动删除临时队列 10 queue_name = result.method.queue # 队列名采用服务端分配的临时队列 11 12 channel.queue_bind(exchange='logs', queue=queue_name) # 将临时队列和exchange绑定 13 14 print(' [*] Waiting for logs. To exit press CTRL+C') 15 16 def callback(ch, method, properties, body): # 回调方法 17 print(" [x] %r" % body) 18 19 channel.basic_consume(callback, queue=queue_name, no_ack=True) # 消息接收 20 21 channel.start_consuming() # 保持一直监听的状态
关键字发送
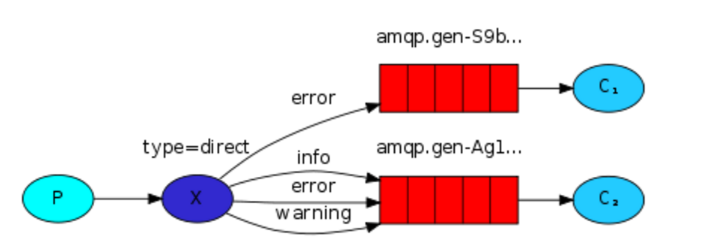
- 生产者代码
1 #!/usr/bin/env python3 2 #coding:utf8 3 #######################生产者################# 4 import pika 5 import sys 6 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 7 channel = connection.channel() 8 channel.exchange_declare(exchange='direct_logs', type='direct') 9 10 severity = sys.argv[1] if len(sys.argv) > 1 else 'info' 11 message = ' '.join(sys.argv[2:]) or 'Hello World!' 12 channel.basic_publish(exchange='direct_logs', 13 routing_key=severity, 14 body=message) 15 print(" [x] Sent %r:%r" % (severity, message)) 16 connection.close()
- 消费者代码
1 #!/usr/bin/env python3 2 #coding:utf8 3 import pika 4 import sys 5 ############消费者#### 6 # 连接 7 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 8 channel = connection.channel() 9 channel.exchange_declare(exchange='direct_logs', type='direct') 10 result = channel.queue_declare(exclusive=True) 11 queue_name = result.method.queue 12 13 # serverites 是一个列表,存放关键字,关键字是通过sys.argv获取的 14 severities = sys.argv[1:] 15 if not severities: 16 sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) 17 sys.exit(1) 18 # 循环绑定关键字和exchange 19 for severity in severities: 20 channel.queue_bind(exchange='direct_logs', 21 queue=queue_name, 22 routing_key=severity) 23 24 print(' [*] Waiting for logs. To exit press CTRL+C') 25 26 def callback(ch, method, properties, body): 27 print(" [x] %r:%r" % (method.routing_key, body)) 28 29 channel.basic_consume(callback, 30 queue=queue_name, 31 no_ack=True) 32 channel.start_consuming()
模糊匹配
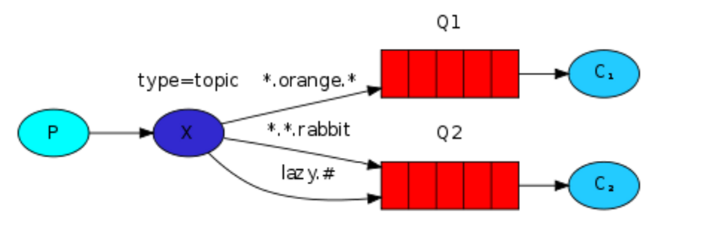
- # 表示可以匹配 0 个或 多个 单词
- * 表示可以匹配到 1个单词
- 消费者代码
1 #!/usr/bin/env python3 2 #coding:utf8 3 import pika 4 import sys 5 6 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 7 channel = connection.channel() 8 9 channel.exchange_declare(exchange='topic_logs',type='topic') 10 11 result = channel.queue_declare(exclusive=True) 12 queue_name = result.method.queue 13 14 binding_keys = sys.argv[1:] 15 if not binding_keys: 16 sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) 17 sys.exit(1) 18 19 for binding_key in binding_keys: 20 channel.queue_bind(exchange='topic_logs', 21 queue=queue_name, 22 routing_key=binding_key) 23 24 print(' [*] Waiting for logs. To exit press CTRL+C') 25 26 def callback(ch, method, properties, body): 27 print(" [x] %r:%r" % (method.routing_key, body)) 28 29 channel.basic_consume(callback, 30 queue=queue_name, 31 no_ack=True) 32 33 channel.start_consuming()
- 生产者代码
1 #!/usr/bin/env python3 2 #coding:utf8 3 import pika 4 import sys 5 6 connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) 7 channel = connection.channel() 8 9 channel.exchange_declare(exchange='topic_logs', type='topic') 10 11 routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' 12 message = ' '.join(sys.argv[2:]) or 'Hello World!' 13 channel.basic_publish(exchange='topic_logs', 14 routing_key=routing_key, 15 body=message) 16 print(" [x] Sent %r:%r" % (routing_key, message)) 17 connection.close()

