Python模块和包
什么是模块?
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。
在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
1.最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。
我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
2.使用模块还可以避免函数名和变量名冲突。每个模块有独立的命名空间,
因此相同名字的函数和变量完全可以分别存在不同的模块中。
所以,我们自己在编写模块时,不必考虑名字会与其他模块冲突
模块分类
模块分为三种:
- 内置标准模块(又称标准库)执行help('modules')查看所有python自带模块列表
- 第三方开源模块,可通过pip install 模块名 联网安装
- 自定义模块
模块调用
import module from module import xx from module.xx.xx import xx as rename from module.xx.xx import *
1.import....
一个py文件就可以作为一个模块
模块的导入:直接导入文件的名字,不需要带着后缀
模块中的函数调用:模块名.函数名()
导入模块的时候做了三件事:1.首先开辟了一个新的命名空间my_moudle
2.执行了my_moudle内的代码
3.将my_moudle里面的名字和命名空间绑定在一起了
注意:模块在一个程序中只会被导入一次,不会重复导入(为了节约资源)那么,如何实现模块在程序中只会被导入一次呢?
当导入一个文件之后,会将模块存储在内存中,当再次导入的时候,就会到内存中查看是否导入过这个模块,如果已经导入过了,就不用再导入了。是通过sys里面的module方法
import sys for i in sys.modules: #查看是否导入过这个模块 print(i)
2.from ...import...(也支持别名)
这种形式导入啥就能用啥,不导入的一律不能用
这个被import导入的名字就相当于属于全局变量了
from xx import read1 read1() from xx import read2 read2()
需要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定关系,如下:



money = 100 def read_money(): print(money)
from zz import money,read_money print('修改前money', money) money = 200 # 将当前位置的名字money绑定到了200 print('修改后money', money) # 打印当前的名字 read_money() # 读取zz.py中的名字money, 仍然为100 """ 修改前money 100 修改后money 200 100 """
from...import *
*与all一起用的,首先会把模块中的所有不是‘_’开头的内容导入进来
可以通过__all__来控制导入的内容,但是只和*有关
*和__all__配合:__all__['read1','read2'],all里面导入什么,*里面就有什么,如果不用all,就都导入进来了。
from zz import * from zz import _x print(read_money) print(_x) print(money) """ <function read_money at 0x00000000029A6598> 2 100 """
3.模块搜索路径
模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
lib里面放的是内置模块
扩展模块一般在site-packages中
sys.path:注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理
import sys print(sys.path) ['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
python解释器会按照列表顺序去依次到每个目录下去匹配你要导入的模块名,只要在一个目录下匹配到了该模块名,就立刻导入,不再继续往后找。
注意列表第一个元素为空,即代表当前目录,所以你自己定义的模块在当前目录会被优先导入。
千万不要自己定义这些你熟悉的模块或关键字啊啥的作为自己的模块名
比如你导入模块os ,你的文件名就不能叫os.py
4.编译python文件
为了提高加载模块的速度,强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,
格式为:module.version.pyc。通常会包含python的版本号。
1.以pyc为后缀的就为编译文件
2.编译pyc文件的时候,只有在导入文件的时候才做(就是作为一个模块的时候他才去编译)
开源模块安装、使用
https://pypi.python.org/pypi 是python的开源模块库,截止2017年9.30日 ,已经收录了118170个来自全世界python开发者贡献的模块,
几乎涵盖了你想用python做的任何事情。 事实上每个python开发者,只要注册一个账号就可以往这个平台上传你自己的模块,这样全世界的开发者都可以容易的下载并使用你的模块。

那如何从这个平台上下载代码呢?
1.直接在上面这个页面上点download,下载后,解压并进入目录,执行以下命令完成安装
编译源码 python setup.py build
安装源码 python setup.py install
2.直接通过pip安装
pip3 install paramiko #paramiko 是模块名
pip命令会自动下载模块包并完成安装。
软件一般会被自动安装你python安装目录的这个子目录里
/your_python_install_path/3.6/lib/python3.6/site-packages
pip命令默认会连接在国外的python官方服务器下载,速度比较慢,你还可以使用国内的豆瓣源,数据会定期同步国外官网,速度快好多
sudo pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com #alex_sayhi是模块名
使用
下载后,直接导入使用就可以,跟自带的模块调用方法无差,演示一个连接linux执行命令的模块
import paramiko ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect('192.168.1.108', 22, 'aa', '123') stdin, stdout, stderr = ssh.exec_command('df') print(stdout.read()) ssh.close(); 执行命令 - 通过用户名和密码连接服务器
开源模块升级
1 | pip3 install --upgrade prompt_toolkit |
包(Package)
当你的模块文件越来越多,就需要对模块文件进行划分,比如把负责跟数据库交互的都放一个文件夹,把与页面交互相关的放一个文件夹,

像上面这样,一个文件夹管理多个模块文件,这个文件夹就被称为包
包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
那不同包之间的模块互相导入呢?
crm/views.py内容
1 2 | def sayhi(): print('hello world!') |
通过manage.py调用
from crm import views views.sayhi()
执行manage.py (注意这里用python2)
1 2 3 4 5 | python manage.py Traceback (most recent call last): File "manage.py", line 6, in <module> from crm import viewsImportError: No module named crm |
竟然说找不到模块,为什么呢?
包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__int__.py用于标识当前文件夹是一个包。
在crm目录下创建一个空文件__int__.py ,再执行一次就可以了
$ touch crm/__init__.py #创建一个空文件 python manage.py hello world!
注意,在python3里,即使目录下没__int__.py文件也能创建成功,猜应该是解释器优化所致,但创建包还是要记得加上这个文件吧。
跨模块导入
目录结构如下

根据上面的结构,如何实现在crm/views.py里导入proj/settings.py模块?
直接导入的话,会报错,说找不到模块

是因为路径找不到,proj/settings.py 相当于是crm/views.py的父亲(crm)的兄弟(proj)的儿子(settings.py),settings.py算是views.py的表弟啦,
在views.py里只能导入同级别兄弟模块代码,或者子级别包里的模块,根本不知道表弟表哥的存在。这可怎么办呢?
答案是添加环境变量,把父亲级的路径添加到sys.path中,就可以了,这样导入 就相当于从父亲级开始找模块了。
crm/views.py中添加环境变量
import sys ,os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #__file__的是打印当前被执行的模块.py文件相对路径,注意是相对路径 print(BASE_DIR) sys.path.append(BASE_DIR) from proj import settings def sayhi(): print('hello world!') print(settings.DATABASES)

*注意;此时在proj/settings.py写上import urls会有问题么?

为什么呢? 因为现在的程序入口是views.py , 你在settings.py导入import urls,其实相当于在crm目录找urls.py,而不是proj目录,
若想正常导入,要改成如下
DATABASES= { 'host':'localhost' } from proj import urls #proj这一层目录已经添加到sys.path里,可以直接找到 print('in proj/settings.py')
绝对导入&相对导入
在linux里可以通过cd ..回到上一层目录 ,cd ../.. 往上回2层,这个..就是指相对路径,在python里,导入也可以通过..
例如:

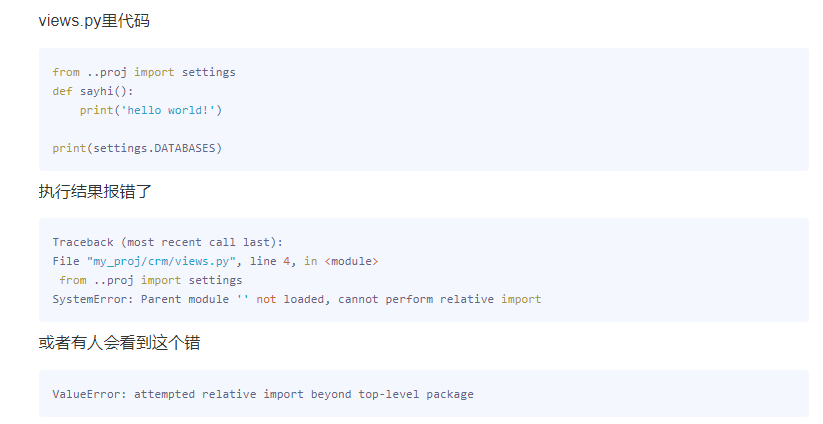
其实这两个错误的原因归根结底是一样的:在涉及到相对导入时,package所对应的文件夹必须正确的被python解释器视作package,而不是普通文件夹。否则由于不被视作package,无法利用package之间的嵌套关系实现python中包的相对导入。
文件夹被python解释器视作package需要满足两个条件:
- 文件夹中必须有__init__.py文件,该文件可以为空,但必须存在该文件。
- 不能作为顶层模块来执行该文件夹中的py文件(即不能作为主函数的入口)。
所以这个问题的解决办法就是,既然你在views.py里执行了相对导入,那就不要把views.py当作入口程序,可以通过上一级的manage.py调用views.py
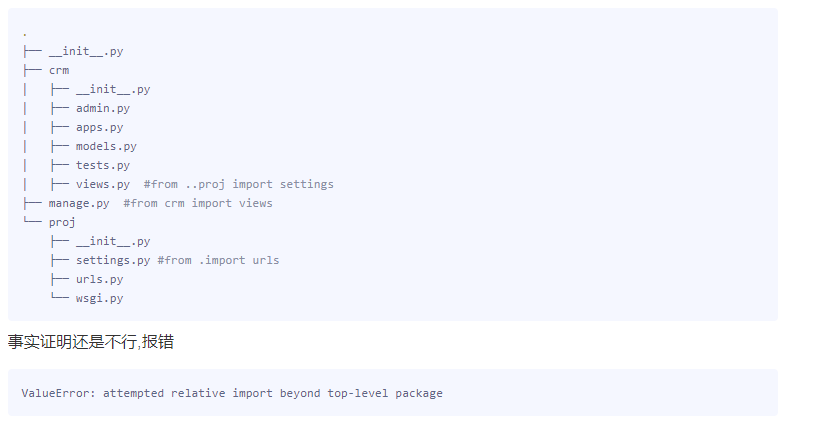
但把from ..proj import settings 改成from . import models 后却执行成功了,为什么呢?
from .. import models会报错的原因是,这句代码会把manage.py所在的这一层视作package,
但实际上它不是,因为package不能是顶层入口代码,若想不出错,只能把manage.py往上再移一层。
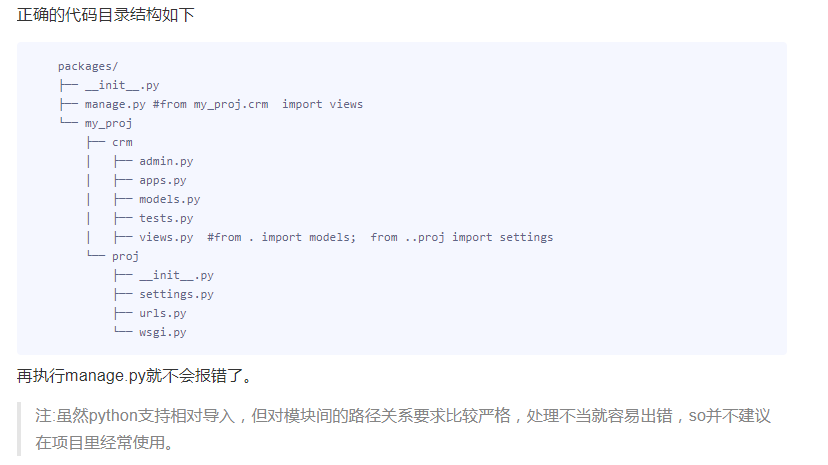
一般在项目中经常使用的相对导入只有
from . import models (相对于从当前目录导入)


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发中对象命名的一点思考
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· C# 深度学习:对抗生成网络(GAN)训练头像生成模型
· .NET 适配 HarmonyOS 进展
· .NET 进程 stackoverflow异常后,还可以接收 TCP 连接请求吗?
· 本地部署 DeepSeek:小白也能轻松搞定!
· 基于DeepSeek R1 满血版大模型的个人知识库,回答都源自对你专属文件的深度学习。
· 在缓慢中沉淀,在挑战中重生!2024个人总结!
· 大人,时代变了! 赶快把自有业务的本地AI“模型”训练起来!
· Tinyfox 简易教程-1:Hello World!