mongodb基本使用
简介
MongoDB是一款强大、灵活、且易于扩展的通用型数据库
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
MongoDB的特点:
1、易用性
MongoDB是由C++编写的,是一个基于分布式文件存储的开源数据库系统,它不是关系型数据库。在高负载的情况下,添加更多的节点,可以保证服务器的性能。
'''MongoDB是一个面向文档(document-oriented)的数据库,而不是关系型数据库。 不采用关系型主要是为了获得更好得扩展性。当然还有一些其他好处,与关系数据库相比,面向文档的数据库不再有“行“(row) 的概念取而代之的是更为灵活的“文档”(document)模型。通过在文档中嵌入文档和数组,面向文档的方法能够仅使用一条记录 来表现复杂的层级关系,这与现代的面向对象语言的开发者对数据的看法一致。 另外,不再有预定义模式(predefined schema):文档的键(key)和值(value)不再是固定的类型和大小 。由于没有固定的模式,根据需要添加或删除字段变得更容易了。通常由于开发者能够进行快速迭代,所以开发进程得以加快。 而且,实验更容易进行。开发者能尝试大量的数据模型,从中选一个最好的。 '''
2、易扩展性
''' 应用程序数据集的大小正在以不可思议的速度增长。随着可用带宽的增长和存储器价格的下降,即使是一个小规模的应用程序,需要存储的数据量也可能大的惊人,甚至超出 了很多数据库的处理能力。过去非常罕见的T级数据,现在已经是司空见惯了。 由于需要存储的数据量不断增长,开发者面临一个问题:应该如何扩展数据库,分为纵向扩展和横向扩展,纵向扩展是最省力的做法,但缺点是大型机一般都非常贵,而且 当数据量达到机器的物理极限时,花再多的钱也买不到更强的机器了,此时选择横向扩展更为合适,但横向扩展带来的另外一个问题就是需要管理的机器太多。 MongoDB的设计采用横向扩展。面向文档的数据模型使它能很容易地在多台服务器之间进行数据分割。MongoDB能够自动处理跨集群的数据和负载,自动重新分配文档, 以及将用户的请求路由到正确的机器上。这样,开发者能够集中精力编写应用程序,而不需要考虑如何扩展的问题。 如果一个集群需要更大的容量,只需要向集群添加新服务器,MongoDB就会自动将现有的数据向新服务器传送 '''
3、丰富的功能
MongoDB作为一款通用型数据库,除了能够创建、读取、更新和删除数据之外,还提供了一系列不断扩展的独特功能 #1、索引 支持通用二级索引,允许多种快速查询,且提供唯一索引、复合索引、地理空间索引、全文索引 #2、聚合 支持聚合管道,用户能通过简单的片段创建复杂的集合,并通过数据库自动优化 #3、特殊的集合类型 支持存在时间有限的集合,适用于那些将在某个时刻过期的数据,如会话session。类似地,MongoDB也支持固定大小的集合,用于保存近期数据,如日志 #4、文件存储 支持一种非常易用的协议,用于存储大文件和文件元数据。MongoDB并不具备一些在关系型数据库中很普遍的功能,如链接join和复杂的多行事务。省略 这些的功能是处于架构上的考虑,或者说为了得到更好的扩展性,因为在分布式系统中这两个功能难以高效地实现
4、性能
''' MongoDB的一个主要目标是提供卓越的性能,这很大程度上决定了MongoDB的设计。MongoDB把尽可能多的内存用作缓存cache, 视图为每次查询自动选择正确的索引。 总之各方面的设计都旨在保持它的高性能 虽然MongoDB非常强大并试图保留关系型数据库的很多特性,但它并不追求具备关系型数据库的所有功能。 只要有可能,数据库服务器就会将处理逻辑交给客户端。 这种精简方式的设计是MongoDB能够实现如此高性能的原因之一 '''
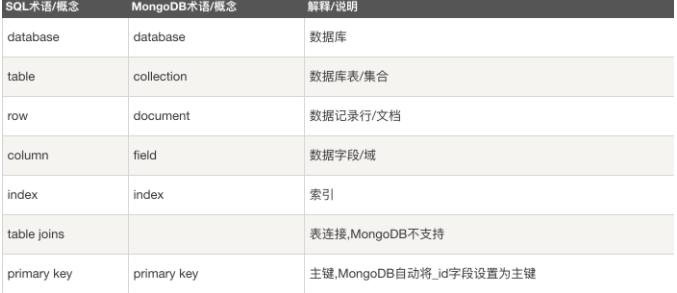
MongoDB基础知识
python与mongdb结合
from pymongo import MongoClient
#1、连接
#client=MongoClient('mongodb://root:123@localhost:27017/')
client = MongoClient('localhost', 27017)
#2、use 数据库
db=client['tz_mongodb'] #等同于:client.db1
connection = db['test']
# 增删改查
connection.insert_many([{'a':1,'b':2},{'c':3,'d':4}])
#3、查看库下所有的集合
print(db.collection_names(include_system_collections=False))
#4、创建集合
table_user=db['userinfo'] #等同于:db.user
#5、插入文档
import datetime
user0={
"_id":1,
"name":"egon",
"birth":datetime.datetime.now(),
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}
}
实例
# 爬取'https://www.kuaidaili.com/free/inha/{}/'把ip和port存入到mongodb数据库中
import requests from bs4 import BeautifulSoup import time start_url = 'https://www.kuaidaili.com/free/inha/{}/' def get_response(url): try: response = requests.get(url) except Exception as e: print(e) return None else: response.encoding='utf-8' return response.text def prase_proxy(html): soup = BeautifulSoup(html,'lxml') body = soup.find(name='tbody') data = body.find_all(name='tr') for item in data: proxy_dict = {} proxy_dict['ip']= item.find(attrs={"data-title": "IP"}).text proxy_dict['port'] = item.find(attrs={"data-title": "PORT"}).text print('==============') save_proxy(proxy_dict) def save_proxy(proxy): try: collection = db['proxy'] print(proxy) collection.insert(proxy) except Exception as e: print(e) if __name__ == '__main__': client = MongoClient('localhost', 27017) db = client['proxies'] for i in range(1,2): prase_proxy(get_response(start_url.format(i))) time.sleep(2)
