
大数据3-Flume收集数据+落地HDFS

flume
日志收集系统
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。


基本概念
Event 事件
把读取的一条日志信息包装成一个对象,这个对象就叫Flume Event。
本质就是一个json字符串,如:{head:info,body:info}
Agent 代理
代理,是一个java进程(JVM),它承载event,从外部源传递到下一个目标的组件。
主要由3部分组成:Source、Channel、Sink。
Source 数据源
Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
Channel 数据通道
Source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的。对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
Sink 数据汇聚点
Sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、Hbase、solr、自定义。
组合过程
为了安全性,数据的传输是将数据封装成一个Event事件。Source会将从服务器收集的数据封装成Event,然后存储在缓冲区Channel,Channel的结构与队列比较相似(先进先出)。Sink就会从缓冲区Channel中抓取数据,抓取到数据时,就会把Channel中的对应数据删除,并且把抓取的数据写入HDFS等目标地址或者也可以是下一个Source。一定是当数据传输成功后,才会删除缓冲区Channel中的数据,这是为了可靠性。当接收方Crash(崩溃)时,以便可以重新发送数据。

2、可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。
Flume提供了三种级别的可靠性保障,从强到弱依次分别为:
end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。)
Store on failure(这也是Scribe-Facebook开源的日志收集系统-采用的策略,当数据接收方crash(崩溃)时,将数据写到本地,待恢复后,继续发送)
Besteffort(数据发送到接收方后,不会进行确认)
3、需要安装jdk
 jdk安装
jdk安装4、安装flume
安装flume5、目录结构
目录结构 


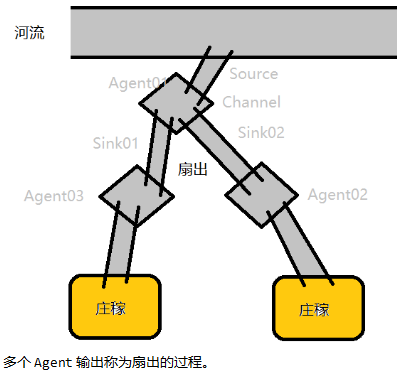
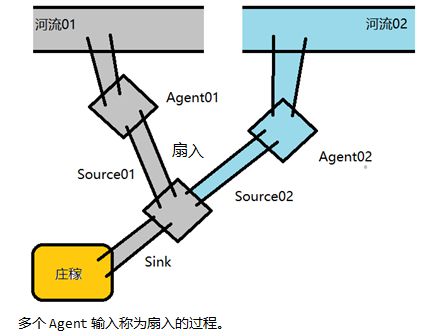
Source组件
重点掌握Avro Source和Spooling Directory Source。

#单节点Flume配置 #命名Agent a1的组件 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #描述/配置Source a1.sources.r1.type = netcat #内置类型,接收来自网络的数据 a1.sources.r1.bind = 0.0.0.0 #等同于网络的127.0.0.1 a1.sources.r1.port = 22222 #服务的端口号 #描述Sink a1.sinks.k1.type = logger #内置类型 #描述内存Channel a1.channels.c1.type = memory #保存数据到内存 a1.channels.c1.capacity = 1000 #容量最大存放1000条日志 a1.channels.c1.transactionCapacity = 100 #事务中的一批数据100条 #为Channle绑定Source和Sink a1.sources.r1.channels = c1 #一个source可以绑定到多个channel a1.sinks.k1.channel = c1 #一个sink只能绑定到一个channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/src/flume/data
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 22222
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = http
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 22222
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.220.137
a1.sinks.k1.port = 22222
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 22222
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.220.137
a1.sinks.k1.port = 22222
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
channels –
type – 类型名称,"AVRO"
bind – 需要监听的主机名或IP
port – 要监听的端口
threads – 工作线程最大线程数
selector.type
selector.*
interceptors – 空格分隔的拦截器列表
interceptors.*
compression-type none 压缩类型,可以是“none”或“default”,这个值必须和AvroSource的压缩格式匹配
ssl false 是否启用ssl加密,如果启用还需要配置一个“keystore”和一个“keystore-password”.
keystore – 为SSL提供的 java密钥文件 所在路径
keystore-password – 为SSL提供的 java密钥文件 密码
keystore-type JKS 密钥库类型可以是 “JKS” 或 “PKCS12”.
exclude-protocols SSLv3 空格分隔开的列表,用来指定在SSL / TLS协议中排除。SSLv3将总是被排除除了所指定的协议。
ipFilter false 如果需要为netty开启ip过滤,将此项设置为true
ipFilterRules – 陪netty的ip过滤设置表达式规则
channels –
type – 类型,需要指定为"spooldir"
spoolDir – 读取文件的路径,即"搜集目录"
fileSuffix .COMPLETED 对处理完成的文件追加的后缀
deletePolicy never 处理完成后是否删除文件,需是"never"或"immediate"
fileHeader false Whether to add a header storing the absolute path filename.
fileHeaderKey file Header key to use when appending absolute path filename to event header.
basenameHeader false Whether to add a header storing the basename of the file.
basenameHeaderKey basename Header Key to use when appending basename of file to event header.
ignorePattern ^$ 正则表达式指定哪些文件需要忽略
trackerDir .flumespool Directory to store metadata related to processing of files. If this path is not an absolute path, then it is interpreted as relative to the spoolDir.
consumeOrder 处理文件的策略,oldest, youngest 或 random。
maxBackoff 4000 The maximum time (in millis) to wait between consecutive attempts to write to the channel(s) if the channel is full. The source will start at a low backoff and increase it exponentially each time the channel throws a ChannelException, upto the value specified by this parameter.
batchSize 100 Granularity at which to batch transfer to the channel
inputCharset UTF-8 读取文件时使用的编码。
decodeErrorPolicy FAIL 当在输入文件中发现无法处理的字符编码时如何处理。FAIL:抛出一个异常而无法 解析该文件。REPLACE:用“替换字符”字符,通常是Unicode的U + FFFD更换不可解析角色。 忽略:掉落的不可解析的字符序列。
deserializer LINE 声明用来将文件解析为事件的解析器。默认一行为一个事件。处理类必须实现EventDeserializer.Builder接口。
deserializer.* Varies per event deserializer.
bufferMaxLines – (Obselete) This option is now ignored.
bufferMaxLineLength 5000 (Deprecated) Maximum length of a line in the commit buffer. Use deserializer.maxLineLength instead.
selector.type replicating replicating or multiplexing
selector.* Depends on the selector.type value
interceptors – Space-separated list of interceptors
interceptors.*
type 类型,必须为"HTTP"
port – 监听的端口
bind 0.0.0.0 监听的主机名或ip
handler org.apache.flume.source.http.JSONHandler 处理器类,需要实现HTTPSourceHandler接口
handler.* – 处理器的配置参数
selector.type
selector.*
interceptors –
interceptors.*
enableSSL false 是否开启SSL,如果需要设置为true。注意,HTTP不支持SSLv3。
excludeProtocols SSLv3 空格分隔的要排除的SSL/TLS协议。SSLv3总是被排除的。
keystore 密钥库文件所在位置。
keystorePassword Keystore 密钥库密码
3.3.6.1启动时报错不继续
[root@localhost conf]# ../bin/flume-ng agent --conf conf --conf-file flume.properties --name a1 -Dflume.root.logger=INFO,console
Info: Including Hive libraries found via () for Hive access
+ exec /usr/local/src/java/jdk1.7.0_51/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp 'conf:/usr/local/src/flume/apache-flume-1.6.0-bin/lib/*:/lib/*' -Djava.library.path= org.apache.flume.node.Application --conf-file flume.properties --name a1
log4j:WARN No appenders could be found for logger (org.apache.flume.lifecycle.LifecycleSupervisor).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
错误原因:
log4j属性文件,路径不正确
解决办法:
[root@localhost bin]# ./flume-ng agent -c /usr/local/src/flume/apache-flume-1.6.0-bin/conf -f /usr/local/src/flume/apache-flume-1.6.0-bin/conf/flume.properties -n a1 -Dflume.root.logger=INFO,console
或者
[root@localhost bin]# ./flume-ng agent -c ../conf -f ../conf/flume.properties -n a1 -Dflume.root.logger=INFO,console
3.3.6.2监控目录重名异常
如果文件已经处理过,哪怕完成的文件被删除,也无济于事
java.lang.IllegalStateException: File name has been re-used with different files. Spooling assumptions violated for /usr/local/src/flume/data/g.txt.COMPLETED
解决办法:
不能有重名文件放入到监控的目录中。
都把文件删除了,它怎么还知道这个文件处理过呢?
Flume在监控目录下创建了一个隐藏目录.flumespool下面有一个隐藏文件.flumespool-main.meta,里面记录了处理过的信息。把此隐藏目录删除,就可以处理重名文件。
[root@localhost conf]# ../bin/flume-ng agent -c ./ -f ./flume-avro.properties -n a1 -Dflume.root.logger=INFO,console
启动结果:
2017-11-07 19:58:03,708 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:253)] Avro source r1 started.
cd /usr/local/src/flume #进入目录
vi log.txt #创建数据文件,内容如下
hi flume.
you are good tools.
通过flume提供的avro客户端向指定机器指定端口发送日志信息:
./flume-ng –h #帮助可以看命令格式及参数用法
./flume-ng avro-client -c ../conf -H 0.0.0.0 -p 22222 -F ../../log.txt
控制台收到消息:
注意:红色框中的打印的内容会被截断,在控制台不能显示很多,只显示很短的一部分内容。
channel组件
事件将被存储在内存中的具有指定大小的队列中。非常适合那些需要高吞吐量但是失败是会丢失数据的场景下。
参数说明:
type – 类型,必须是“memory”
capacity 100 事件存储在信道中的最大数量
transactionCapacity 100 每个事务中的最大事件数
keep-alive 3 添加或删除操作的超时时间
byteCapacityBufferPercentage 20 Defines the percent of buffer between byteCapacity and the estimated total size of all events in the channel, to account for data in headers. See below.
byteCapacity see description Maximum total bytes of memory allowed as a sum of all events in this channel. The implementation only counts the Event body, which is the reason for providing the byteCapacityBufferPercentage configuration parameter as well. Defaults to a computed value equal to 80% of the maximum memory available to the JVM (i.e. 80% of the -Xmx value passed on the command line). Note that if you have multiple memory channels on a single JVM, and they happen to hold the same physical events (i.e. if you are using a replicating channel selector from a single source) then those event sizes may be double-counted for channel byteCapacity purposes. Setting this value to 0 will cause this value to fall back to a hard internal limit of about 200 GB.
事件被持久存储在可靠的数据库中。目前支持嵌入式的Derby数据库。如果可恢复性非常的重要可以使用这种方式
性能会比较低下,但是即使程序出错数据不会丢失。
参数说明:
type – 类型,必须是“file”
checkpointDir ~/.flume/file-channel/checkpoint 检查点文件存放的位置
useDualCheckpoints false Backup the checkpoint. If this is set to true, backupCheckpointDir must be set
backupCheckpointDir – The directory where the checkpoint is backed up to. This directory must not be the same as the data directories or the checkpoint directory
dataDirs ~/.flume/file-channel/data 逗号分隔的目录列表,用以存放日志文件。使用单独的磁盘上的多个目录可以提高文件通道效率。
transactionCapacity 10000 The maximum size of transaction supported by the channel
checkpointInterval 30000 Amount of time (in millis) between checkpoints
maxFileSize 2146435071 一个日志文件的最大尺寸
minimumRequiredSpace 524288000 Minimum Required free space (in bytes). To avoid data corruption, File Channel stops accepting take/put requests when free space drops below this value
capacity 1000000 Maximum capacity of the channel
keep-alive 3 Amount of time (in sec) to wait for a put operation
use-log-replay-v1 false Expert: Use old replay logic
use-fast-replay false Expert: Replay without using queue
checkpointOnClose true Controls if a checkpoint is created when the channel is closed. Creating a checkpoint on close speeds up subsequent startup of the file channel by avoiding replay.
encryption.activeKey – Key name used to encrypt new data
encryption.cipherProvider – Cipher provider type, supported types: AESCTRNOPADDING
encryption.keyProvider – Key provider type, supported types: JCEKSFILE
encryption.keyProvider.keyStoreFile – Path to the keystore file
encrpytion.keyProvider.keyStorePasswordFile – Path to the keystore password file
encryption.keyProvider.keys – List of all keys (e.g. history of the activeKey setting)
encyption.keyProvider.keys.*.passwordFile – Path to the optional key password file
内存溢出通道。事件被存储在内存队列和磁盘中。 内存队列作为主存储,而磁盘作为溢出内容的存储。当内存队列已满时,后续的事件将被存储在文件通道中。这个通道适用于正常操作期间适用内存通道已期实现高效吞吐,而在高峰期间适用文件通道实现高耐受性。通过降低吞吐效率提高系统可耐受性。如果Agent崩溃,则只有存储在文件系统中的事件可以被恢复,内存中数据会丢失。此通道处于试验阶段,不建议在生产环境中使用。 参数说明: type – 类型,必须是"SPILLABLEMEMORY" memoryCapacity 10000 内存中存储事件的最大值,如果想要禁用内存缓冲区将此值设置为0。 overflowCapacity 100000000 可以存储在磁盘中的事件数量最大值。设置为0可以禁用磁盘存储。 overflowTimeout 3 The number of seconds to wait before enabling disk overflow when memory fills up. byteCapacityBufferPercentage 20 Defines the percent of buffer between byteCapacity and the estimated total size of all events in the channel, to account for data in headers. See below. byteCapacity see description Maximum bytes of memory allowed as a sum of all events in the memory queue. The implementation only counts the Event body, which is the reason for providing the byteCapacityBufferPercentage configuration parameter as well. Defaults to a computed value equal to 80% of the maximum memory available to the JVM (i.e. 80% of the -Xmx value passed on the command line). Note that if you have multiple memory channels on a single JVM, and they happen to hold the same physical events (i.e. if you are using a replicating channel selector from a single source) then those event sizes may be double-counted for channel byteCapacity purposes. Setting this value to 0 will cause this value to fall back to a hard internal limit of about 200 GB. avgEventSize 500 Estimated average size of events, in bytes, going into the channel <file channel properties> see file channel Any file channel property with the exception of ‘keep-alive’ and ‘capacity’ can be used. The keep-alive of file channel is managed by Spillable Memory Channel. Use ‘overflowCapacity’ to set the File channel’s capacity.
sink组件
记录INFO级别的日志,通常用于调试。
参数说明:
channel –
type – The component type name, needs to be logger
maxBytesToLog 16 Maximum number of bytes of the Event body to log
要求必须在 --conf 参数指定的目录下有 log4j的配置文件log4j.properties
可以通过-Dflume.root.logger=INFO,console在命令启动时手动指定log4j参数
在本地文件系统中存储事件。
每隔指定时长生成文件保存这段时间内收集到的日志信息。
参数说明:
channel –
type – 类型,必须是"file_roll"
sink.directory – 文件被存储的目录
sink.rollInterval 30 滚动文件每隔30秒(应该是每隔30秒钟单独切割数据到一个文件的意思)。如果设置为0,则禁止滚动,从而导致所有数据被写入到一个文件中。
sink.serializer TEXT Other possible options include avro_event or the FQCN of an implementation of EventSerializer.Builder interface.
batchSize 100
修改内容:
a1.sources.r1.type = http #内置类型
a1.sources.r1.port = 22222 #设置监测目录
a1.sinks.k1.type = file_roll #文件落地
a1.sinks.k1.sink.directory = /usr/local/src/flume/data #存放目录
配置第一行,注释第二行,启用console。默认是注释第一行,开启第二行。
curl -X POST -d '[{"headers":{"tester":"tony"},"body":"hello http flume"}]' http://0.0.0.0:22222
执行结果
[root@localhost data]# pwd
/usr/local/src/flume/data #数据所在目录
[root@localhost data]# ll
total 4
-rw-r--r--. 1 root root 0 Nov 9 16:21 1510273266537-1
-rw-r--r--. 1 root root 22 Nov 9 16:21 1510273266537-2
-rw-r--r--. 1 root root 0 Nov 9 16:22 1510273266537-3
-rw-r--r--. 1 root root 0 Nov 9 16:22 1510273266537-4
-rw-r--r--. 1 root root 0 Nov 9 16:23 1510273266537-5
-rw-r--r--. 1 root root 0 Nov 9 16:23 1510273266537-6
[root@localhost data]# tail 1510273266537-2 #数据已经写入
hello file-roll flume
[root@localhost data]# tail 1510273266537-6 #即使没有数据也会产生文件
注意:默认每隔30秒产生一个日志文件,但时间不够精准
Avro Sink
是实现多级流动 和 扇出流(1到多) 扇入流(多到1) 的基础。
channel –
type – avro.
hostname – The hostname or IP address to bind to.
port – The port # to listen on.
batch-size 100 number of event to batch together for send.
connect-timeout 20000 Amount of time (ms) to allow for the first (handshake) request.
request-timeout 20000 Amount of time (ms) to allow for requests after the first.
我们要演示多级流动,就需要多个源,我们在安装两台服务器。
克隆两台新的虚拟机 flume02、flume03
多级部署结构
修改内容:
a1.sources.r1.type = http
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 22222
#描述Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.163.130
a1.sinks.k1.port = 22222
复制文件到其它主机
[root@localhost conf]# pwd
/usr/local/src/flume/apache-flume-1.6.0-bin/conf
[root@localhost conf]# scp flume-avro-sink.properties root@192.168.163.130:/usr/local/src/flume/apache-flume-1.6.0-bin/conf/flume-avro-sink.properties
The authenticity of host '192.168.163.130 (192.168.163.130)' can't be established.
RSA key fingerprint is 40:d6:4e:bd:3e:d0:90:3b:86:41:72:90:ec:dd:95:f9.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.163.130' (RSA) to the list of known hosts.
flume-avro-sink.properties 100% 477 0.5KB/s 00:00
[root@localhost conf]# scp flume-avro-sink.properties root@192.168.163.131:/usr/local/src/flume/apache-flume-1.6.0-bin/conf/flume-avro-sink.properties
The authenticity of host '192.168.163.131 (192.168.163.131)' can't be established.
RSA key fingerprint is 40:d6:4e:bd:3e:d0:90:3b:86:41:72:90:ec:dd:95:f9.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.163.131' (RSA) to the list of known hosts.
flume-avro-sink.properties 100% 477 0.5KB/s 00:00
[root@localhost conf]#
修改内容:
a1.sources.r1.type = avro #内置类型
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 22222
#描述Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.163.131
a1.sinks.k1.port = 22222
修改内容:
a1.sources.r1.type = avro #内置类型
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 22222
#描述Sink
a1.sinks.k1.type = logger
[root@localhost conf]# ../bin/flume-ng agent -c ./ -f ./flume-avro-sink.properties -n a1 -Dflume.root.logger=INFO,console
在flume01节点上发送消息
curl -X POST -d '[{"headers":{"tester":"tony"},"body":"hello http flume"}]' http://0.0.0.0:22222
执行结果:
2017-11-09 18:58:33,863 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xdd9a2bfc, /192.168.163.130:34945 => /192.168.163.131:22222] BOUND: /192.168.163.131:22222
2017-11-09 18:58:33,863 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xdd9a2bfc, /192.168.163.130:34945 => /192.168.163.131:22222] CONNECTED: /192.168.163.130:34945
2017-11-09 19:00:28,463 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{tester=tony} body: 68 65 6C 6C 6F 20 6D 6F 72 65 20 61 76 72 6F 20 hello more avro }
启动节点是有先后顺序,flume01要访问192.168.163.130:22222,但flume02还没有启动,所以报下列错误。
解决办法:依次倒着启动各个节点,先flume03,再flume02,再flume01。下面提示绑定成功。

flume01服务器接收http格式数据为来源,输出avro格式数据;flume02服务器接收avro格式数据为来源,输出avro格式数据;flume03服务器接收avro格式数据为来源,输出到log4j,打印结果到控制台。
HDFS Sink
HDFS分布式海量数据的存储和备份,
HDFS Sink将事件写入到HDFS中,支持创建文本文件和序列化文件,支持压缩。
这些文件可以分区,按照指定的时间或数据量或事件的数量为基础。(如:多少条记录放一个文件,如果每条日志都放一个文件,那HDFS就会产生小文件的问题,将来处理的效率太低。可以设置规则,什么时候文件发生滚动,形成新文件)。它还可以通过时间戳或者机器属性对数据进行buckets(分桶)/partitions(分区)操作。HDFS的目录流程可以包含将要由替换格式的转移序列用于生成存储事件的目录/文件名。使用这个Sink要求hadoop必须依据安装好,以便flume可以通过hadoop提供的jar包与HDFS进行通信。注意,此版本的hadoop必须支持sync()调用,这样数据可以追加到尾部。
#命名Agent a1的组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#描述/配置Source
a1.sources.r1.type = http
a1.sources.r1.port = 22222
#描述Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/flume/data
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
channel –
type – 类型名称,必须是“HDFS”
hdfs.path – HDFS 目录路径 (eg hdfs://namenode/flume/webdata/)
hdfs.fileType SequenceFile File format: currently SequenceFile, DataStream or CompressedStream (1)DataStream will not compress output file and please don’t set codeC (2)CompressedStream requires set hdfs.codeC with an available codeC
默认是序列化文件,可选项:SequenceFile序列化文件/DataStream文本文件/CompressedStream 压缩文件
hdfs.filePrefix FlumeData Flume在目录下创建文件的名称前缀
hdfs.fileSuffix – 追加到文件的名称后缀 (eg .avro - 注: 日期时间不会自动添加)
hdfs.inUsePrefix – Flume正在处理的文件所加的前缀
hdfs.inUseSuffix .tmp Flume正在处理的文件所加的后缀
hdfs.rollInterval 30 Number of seconds to wait before rolling current file (0 = never roll based on time interval)
hdfs.rollSize 1024 File size to trigger roll, in bytes (0: never roll based on file size)
hdfs.rollCount 10 Number of events written to file before it rolled (0 = never roll based on number of events)
hdfs.idleTimeout 0 Timeout after which inactive files get closed (0 = disable automatic closing of idle files)
hdfs.batchSize 100 number of events written to file before it is flushed to HDFS
hdfs.codeC – Compression codec. one of following : gzip, bzip2, lzo, lzop, snappy
hdfs.maxOpenFiles 5000 Allow only this number of open files. If this number is exceeded, the oldest file is closed.
hdfs.minBlockReplicas – Specify minimum number of replicas per HDFS block. If not specified, it comes from the default Hadoop config in the classpath.
hdfs.writeFormat – Format for sequence file records. One of “Text” or “Writable” (the default).
hdfs.callTimeout 10000 Number of milliseconds allowed for HDFS operations, such as open, write, flush, close. This number should be increased if many HDFS timeout operations are occurring.
hdfs.threadsPoolSize 10 Number of threads per HDFS sink for HDFS IO ops (open, write, etc.)
hdfs.rollTimerPoolSize 1 Number of threads per HDFS sink for scheduling timed file rolling
hdfs.kerberosPrincipal – Kerberos user principal for accessing secure HDFS
hdfs.kerberosKeytab – Kerberos keytab for accessing secure HDFS
hdfs.proxyUser
hdfs.round false 时间戳是否向下取整(如果是true,会影响所有基于时间的转移序列,除了%T)
hdfs.roundValue 1 舍值的边界值
hdfs.roundUnit 向下舍值的单位 - second, minute , hour
hdfs.timeZone Local Time Name of the timezone that should be used for resolving the directory path, e.g. America/Los_Angeles.
hdfs.useLocalTimeStamp false Use the local time (instead of the timestamp from the event header) while replacing the escape sequences.
hdfs.closeTries 0 Number of times the sink must try renaming a file, after initiating a close attempt. If set to 1, this sink will not re-try a failed rename (due to, for example, NameNode or DataNode failure), and may leave the file in an open state with a .tmp extension. If set to 0, the sink will try to rename the file until the file is eventually renamed (there is no limit on the number of times it would try). The file may still remain open if the close call fails but the data will be intact and in this case, the file will be closed only after a Flume restart.
hdfs.retryInterval 180 Time in seconds between consecutive attempts to close a file. Each close call costs multiple RPC round-trips to the Namenode, so setting this too low can cause a lot of load on the name node. If set to 0 or less, the sink will not attempt to close the file if the first attempt fails, and may leave the file open or with a ”.tmp” extension.
serializer TEXT Other possible options include avro_event or the fully-qualified class name of an implementation of the EventSerializer.Builder interface.
复制依赖jar文件
/usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/common/lib 所有的jar复制过去
/usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/common 3个jar包
/usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/hdfs 目录 hadoop-hdfs-2.7.1.jar
[root@localhost conf]# ../bin/flume-ng agent -c ./ -f ./flume-hdfs.properties -n a1 -Dflume.root.logger=INFO,console
执行结果,飞速打印结果
模拟发HTTP请求
在flume01节点上发送消息
curl -X POST -d '[{"headers":{"tester":"tony"},"body":"hello http flume"}]' http://0.0.0.0:22222
执行结果:
org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:234)] Creating hdfs://hadoop01:9000/flume/data/FlumeData.1510560200492.tmp
hadoop fs -put '/usr/local/src/hive/data/english.txt' /user/hive/warehouse/test.db/tb_book

