(一)zookeeper介绍
一.介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户
提供:
1)文件系统
2)通知机制
zookeeper简单来讲是一个注册中心 用于注册服务和发现服务的
二.原理
工作机制

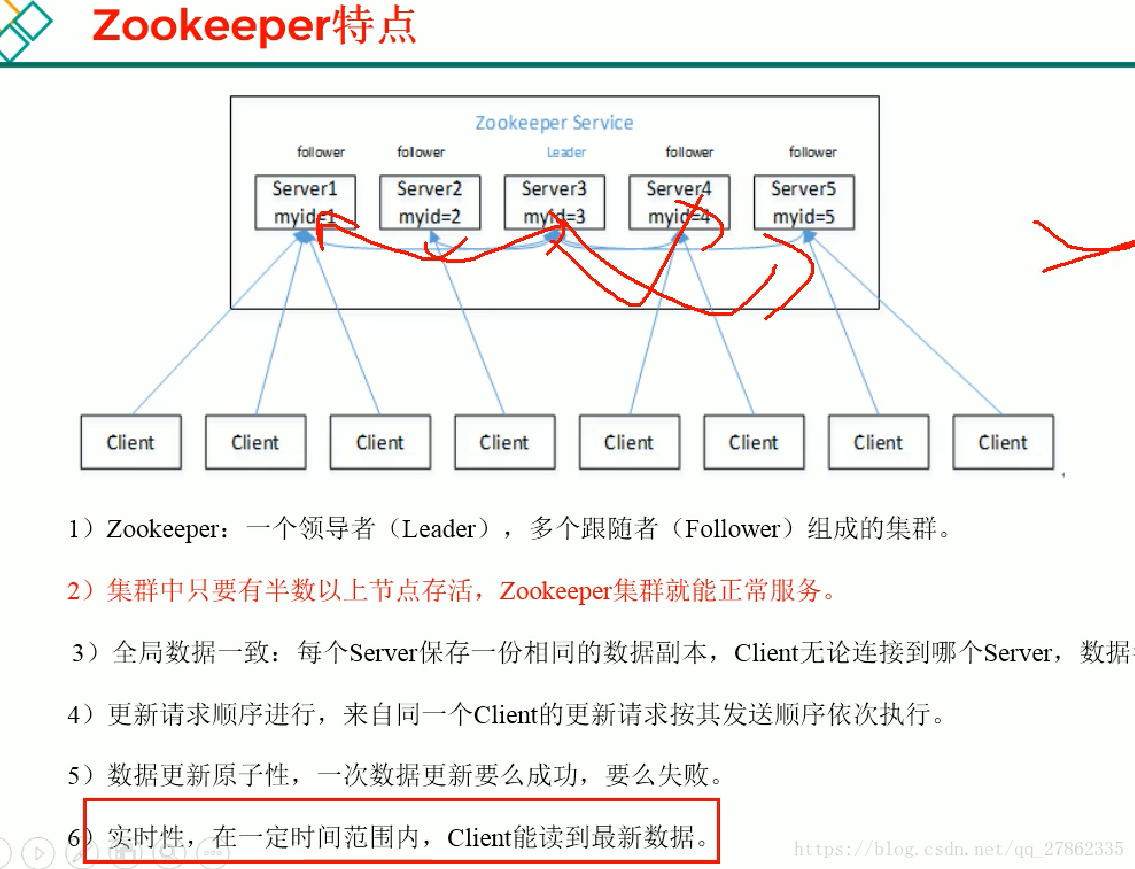
zookeeper的特点
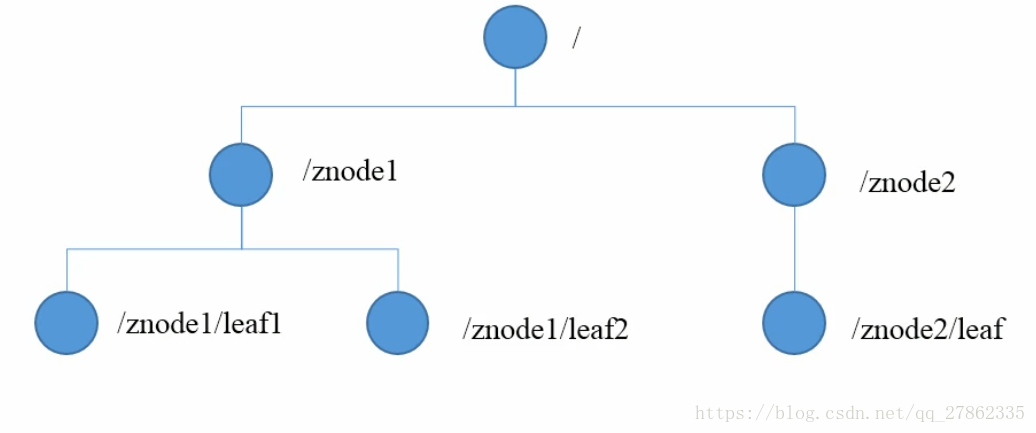
zookeeper的数据结构
zookeeper的数据模型结构与Unix文件很类似,整体上可以看作是一棵树,每个节点称作一个ZNode。每个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
三.zookeeper的应用场景
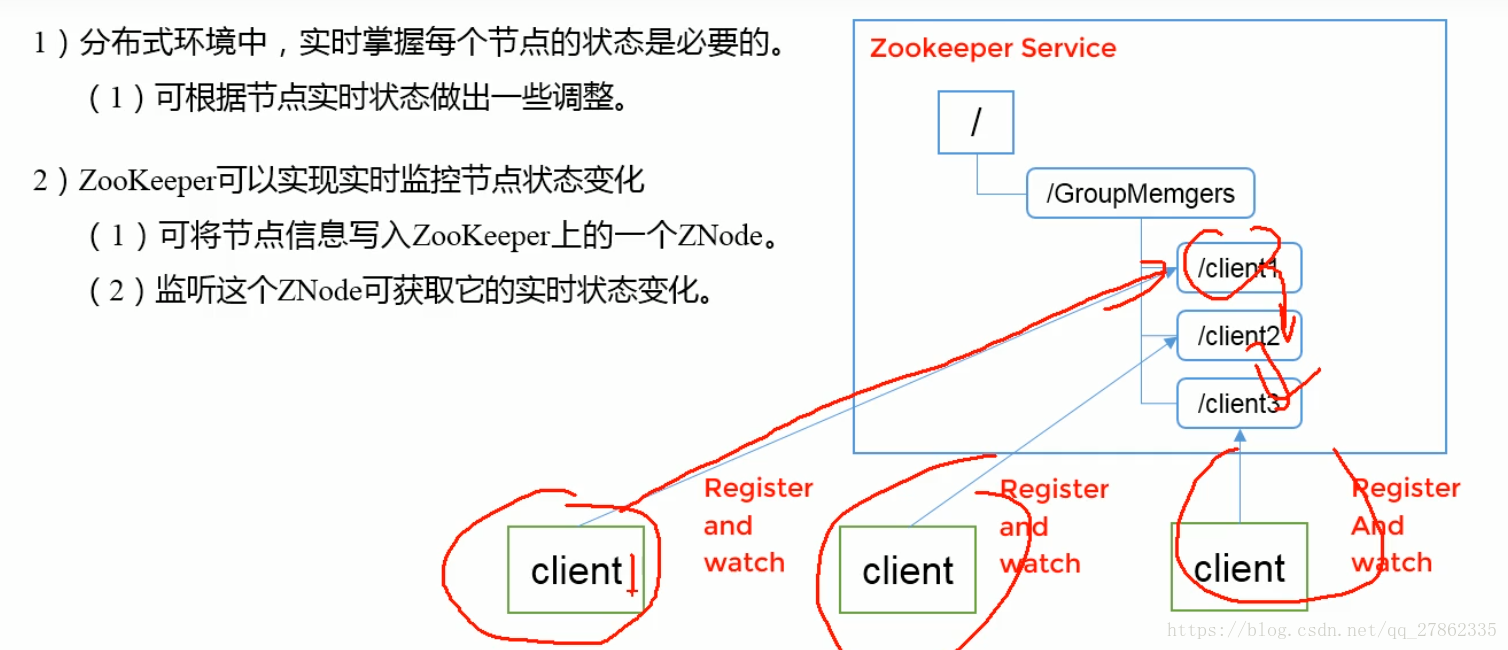
命名服务
在日常开发中,我们会遇到这样的场景:服务A(开发者:小李)需要访问服务B(开发者:小王),但是服务B还在开发过程中(未完成),那么服务A(此时已完成)就不知道如何获取服务B的访问路径了(假设我们使用http服务),小李还有其他工作要做,该怎么办呢?
使用zookeeper的服务就可以简单解决:小李和小王约定好:服务B部署成功后,先到zookeeper注册服务(即在zookeeper添加节点/service/B和节点数据)。服务A开发结束后,部署到服务器,然后服务A监控zookeeper服务节点/service/B,如果发现节点数据了,那么服务A就可以访问服务B了。
通俗的语句就是:
A和B合伙开饭店,A负责接受点菜,传菜,收钱,B负责做菜。然而当前A准备好了,而B在厨房一直没准备好,导致A不敢接待客人。
于是B准备好后,就在一个叫zookeeper的牌子上写上‘厨房准备好了’,挂到大厅。A就没事看下大厅的牌子,发现A准备好了,就准备迎客工作了。
命名服务器是给程序或者机器一个唯一的标示,就像身份证一样,根据这个标示,可以获取到相关信息,例如这个人的年龄,性别等等。
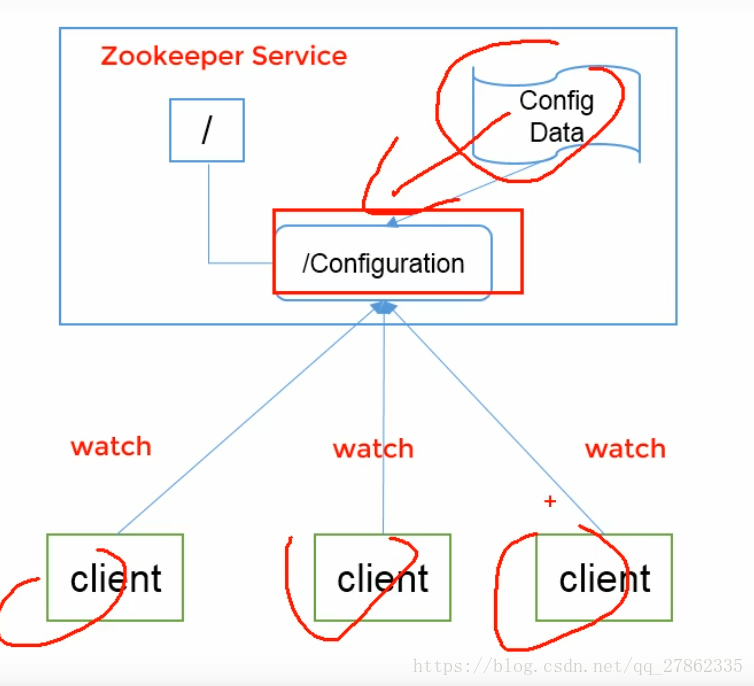
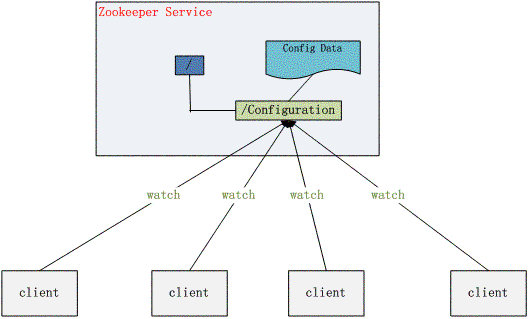
统一配置管理
(1)分布式环境下,配置文件同步,要求一个集群中的所有配置信息都是一致的,比如kafka集群
(2)对配置文件修改后,希望能够快速同步到各个节点上
(3)配置管理交由zooKeeper实现: ①可以将配置信息写入到zookeeper上的一个ZNode;②各个客户端服务器监听这个ZNode③一旦ZNode中的数据被修改,zookeeper将通知各个客户端服务器。

白话:
目前很多公司开发或者使用的程序都是分布式的,而程序总会或多或少的存在一些额外配置,且分散部署在多台机器上。某一条要修改配置,要逐个去修改配置就变得有些困难,特别是应用部署的点数特别大的时候,就成了不可能完成的事情了。一种方式就是把相关配置写到数据库中,每个应用去读取数据库的配置,这种方式优点就是把配置集中管理,缺点也很明显,就是不能及时获得配置的变革,要及时获得变更后的配置,就要不停的去扫描数据库,而这又会造成数据库的压力巨大。
我要说的这种方式就是利用zookeeper的这种发布订阅、watch来实现。即,把相关的配置数据写到zookeeper的某个指定的节点下。应用服务监听这个节点的数据变化,一旦节点数据(配置信息)发生了变化,应用服务就会收到zookeeper的通知,然后应用服务就可以从zookeeper获得新的配置信息。
软负载均衡
在zookeeper中记录每台服务器的访问数,让访问最少的服务器去处理最新的客户端请求。
四.zookeeper的配置参数
(1)tickTime = 2000;通信心跳数;Zookeeper服务器与客户端心跳时间,单位为毫秒;
zk使用的基本时间,服务器之间或者客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。用于心跳机制,并且设置最小的session超时时间为两倍的心跳时间。
(2)initLimit:LF初始通信时限
集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时,能容忍的最多心跳数,,用来限定集群中zk服务器连接到leader的时限。 initLimit*tickTime 长的时间
(3)syncLimit:LF同步通信时限
集群中Leader与Follwer之间最大响应时间单位,假如响应时间超过syncLimit*tickTime,Leader认为Follower挂掉,从服务器中删除Follower。
(3)clientPort:监听客户端连接的端口
(4)dataDir:数据文件目录+数据持久化路径
