

文章标题
A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets
且谈Apache Spark的API三剑客:RDD、DataFrame和Dataset
When to use them and why
什么时候用他们,为什么?
- tale [tel] 传说,传言;(尤指充满惊险的)故事;坏话,谣言;〈古〉计算,总计
作者介绍
Jules S. Damji是Databricks在Apache Spark社区的布道者。他也是位一线的开发者,在业界领先的公司里有超过15年的大型分布式系统开发经验。在加入Databricks之前,他在Hortonworks公司做Developer Advocate。
文章正文
Of all the developer's delight, none is more attractive than a set of APIs that make developers productive,that is easy to use, and that is intuitive and expressive. One of Apache Spark's appeal to developers has been its easy-to-use APIs, for operating on large datasets, across languages: Scala, Java, Python, and R.
最令开发者们高兴的事莫过于有一组API,可以大大提高开发者们的工作效率,容易使用、非常直观并且富有表现力。Apache Spark广受开发者们欢迎的一个重要原因也在于它那些非常容易使用的API,可以方便地通过多种语言,如Scala、Java、Python和R等来操作大数据集。
- delight [dɪˈlaɪt] 快乐,高兴;使人高兴的东西或人 使高兴,使欣喜
- attractive [əˈtræktɪv] 迷人的;有魅力的;引人注目的;招人喜爱的 有吸引力
- intuitive [ɪnˈtu:ɪtɪv] 直观的;直觉的;凭直觉获知的
In this blog, I explore three sets of APIs—RDDs, DataFrames, and Datasets—available in Apache Spark 2.2 and beyond; why and when you should use each set; outline their performance and optimization benefits; and enumerate scenarios when to use DataFrames and Datasets instead of RDDs. Mostly, I will focus on DataFrames and Datasets, because in Apache Spark 2.0, these two APIs are unified.
在本文中,我将深入讲讲Apache Spark 2.2以及以上版本提供的三种API——RDD、DataFrame和Dataset,在什么情况下你该选用哪一种以及为什么,并概述它们的性能和优化点,列举那些应该使用DataFrame和Dataset而不是RDD的场景。我会更多地关注DataFrame和Dataset,因为在Apache Spark 2.0中这两种API被整合起来了。
- explore [ɪkˈsplɔr] 勘查, 探测, 勘探;[医]探查(伤处等),探索,研究
- outline [ˈaʊtˌlaɪn] 梗概,大纲,提纲,草稿,要点,轮廓线,轮廓画法,略图(画法)概述;略述
- scenarios [sɪ'nɑ:ri:oʊz] [意]情节;剧本;事态;脚本 场景
Our primary motivation behind this unification is our quest to simplify Spark by limiting the number of concepts that you have to learn and by offering ways to process structured data. And through structure, Spark can offer higher-level abstraction and APIs as domain-specific language constructs.
这次整合背后的动机在于我们希望可以让使用Spark变得更简单,方法就是减少你需要掌握的概念的数量,以及提供处理结构化数据的办法。在处理结构化数据时,Spark可以像针对特定领域的语言所提供的能力一样,提供高级抽象和API。
- unification [ˌju:nɪfɪ'keɪʃn] 统一,联合;一致
1、Resilient Distributed Dataset (RDD)
弹性分布式数据集(RDD)
RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
从一开始RDD就是Spark提供的面向用户的主要API。从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层API进行并行处理。
- inception [ɪnˈsɛpʃən] 开始,开端,初期;获得学位
1.1 When to use RDDs?
在什么情况下使用RDD?
Consider these scenarios or common use cases for using RDDs when:
下面是使用RDD的场景和常见案例:
- you want low-level transformation and actions and control on your dataset;
- 你希望可以对你的数据集进行最基本的转换、处理和控制;
- your data is unstructured, such as media streams or streams of text;
- 你的数据是非结构化的,比如流媒体或者字符流;
- you want to manipulate your data with functional programming constructs than domain specific expressions;
- 你想通过函数式编程而不是特定领域内的表达来处理你的数据;
- you don’t care about imposing a schema, such as columnar format, while processing or accessing data attributes by name or column; and
- 你不希望像进行列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性;
- you can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
- 你并不在意通过DataFrame和Dataset进行结构化和半结构化数据处理所能获得的一些优化和性能上的好处;
- manipulate [məˈnɪpjəˌlet] 操纵;操作,处理;巧妙地控制;[医] 推拿,调整
- forgo [fɔrˈɡo, for-] 没有也行,放弃
- available [əˈveləbəl] 可获得的;有空的;可购得的;能找到的
- semi-structured 半结构
1.2 What happens to RDDs in Apache Spark 2.0?
Apache Spark 2.0 中的RDD有哪些改变?
You may ask: Are RDDs being relegated as second class citizens? Are they being deprecated?
可能你会问:RDD是不是快要降级成二等公民了?是不是快要退出历史舞台了?
The answer is a resounding NO!
答案是非常坚决的:不!
What’s more, as you will note below, you can seamlessly move between DataFrame or Dataset and RDDs at will—by simple API method calls—and DataFrames and Datasets are built on top of RDDs.
而且,接下来你还将了解到,你可以通过简单的API方法调用在DataFrame或Dataset与RDD之间进行无缝切换,事实上DataFrame和Dataset也正是基于RDD提供的。
- relegate [ˈrɛlɪˌɡet] 使降级;使降职;转移;把…归类
- deprecate [ˈdɛprɪˌket] 不赞成,反对
- resounding [rɪˈzaʊndɪŋ] 反响的,共鸣的;响亮的,宏亮的;彻底的,完全的;夸张的,虚夸的
- seamlessly 无空隙地;无停顿地 无缝
- seamless [ˈsimlɪs] 无缝的;无漏洞的
2、DataFrames
Like an RDD, a DataFrame is an immutable distributed collection of data. Unlike an RDD, data is organized into named columns, like a table in a relational database. Designed to make large data sets processing even easier, DataFrame allows developers to impose a structure onto a distributed collection of data, allowing higher-level abstraction; it provides a domain specific language API to manipulate your distributed data; and makes Spark accessible to a wider audience, beyond specialized data engineers.
与RDD相似,DataFrame也是数据的一个不可变分布式集合。但与RDD不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计DataFrame的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的API来处理你的分布式数据,并让更多的人可以更方便地使用Spark,而不仅限于专业的数据工程师。
- accessible [ækˈsɛsəbəl] 易接近的;可理解的;易相处的;易感的
- audience [ˈɔdiəns] 观众;听众;读者;接见
In our preview of Apache Spark 2.0 webinar and subsequent blog, we mentioned that in Spark 2.0, DataFrame APIs will merge with Datasets APIs, unifying data processing capabilities across libraries. Because of this unification, developers now have fewer concepts to learn or remember, and work with a single high-level and type-safe API called Dataset.
在我们的Apache Spark 2.0网络研讨会以及后续的博客中,我们提到在Spark 2.0中,DataFrame和Dataset的API将融合到一起,完成跨函数库的数据处理能力的整合。在整合完成之后,开发者们就不必再去学习或者记忆那么多的概念了,可以通过一套名为Dataset的高级并且类型安全的API完成工作。
- webinar 在线研讨会
- capability [ˌkeɪpə'bɪləti] 性能;容量;才能,能力;生产率
- across libraries 跨函数库
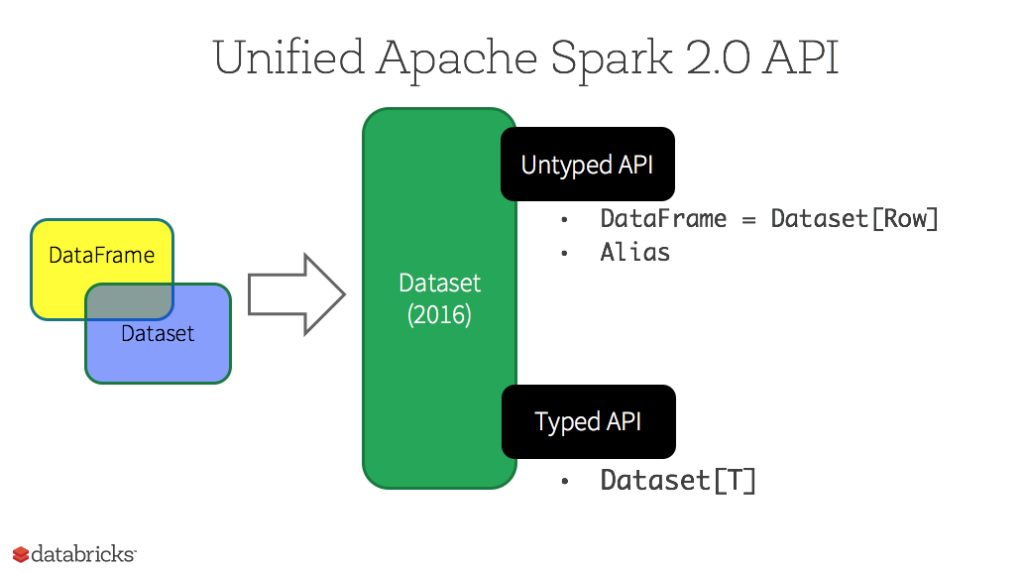
3、Datasets
Starting in Spark 2.0, Dataset takes on two distinct APIs characteristics: a strongly-typed API and an untyped API, as shown in the table below. Conceptually, consider DataFrame as an alias for a collection of generic objects Dataset[Row], where a Row is a generic untyped JVM object. Dataset, by contrast, is a collection of strongly-typed JVM objects, dictated by a case class you define in Scala or a class in Java.
如下面的表格所示,从Spark 2.0开始,Dataset开始具有两种不同类型的API特征:有明确类型的API和无类型的API。从概念上来说,你可以把DataFrame当作一些通用对象Dataset[Row]的集合的一个别名,而一行就是一个通用的无类型的JVM对象。与之形成对比,Dataset就是一些有明确类型定义的JVM对象的集合,通过你在Scala中定义的Case Class或者Java中的Class来指定。
- conceptually [kən'septʃʊrlɪ] 概念地 从概念上讲
- dictate [ˈdɪkteɪt] 口述;命令,指示;使听写;控制,支配
3.1 Typed and Un-typed APIs
有类型和无类型的API
| Language | Main Abstraction |
| Scala | Dataset[T] & DataFrame (alias for Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Note: Since Python and R have no compile-time type-safety, we only have untyped APIs, namely DataFrames.
注意:因为Python和R没有编译时类型安全,所以我们只有称之为DataFrame的无类型API。
4、Benefits of Dataset APIs
Dataset API 的优点
As a Spark developer, you benefit with the DataFrame and Dataset unified APIs in Spark 2.0 in a number of ways.
在Spark 2.0里,DataFrame和Dataset的统一API会为Spark开发者们带来许多方面的好处。
4.1 Static-typing and runtime type-safety
静态类型与运行时类型安全
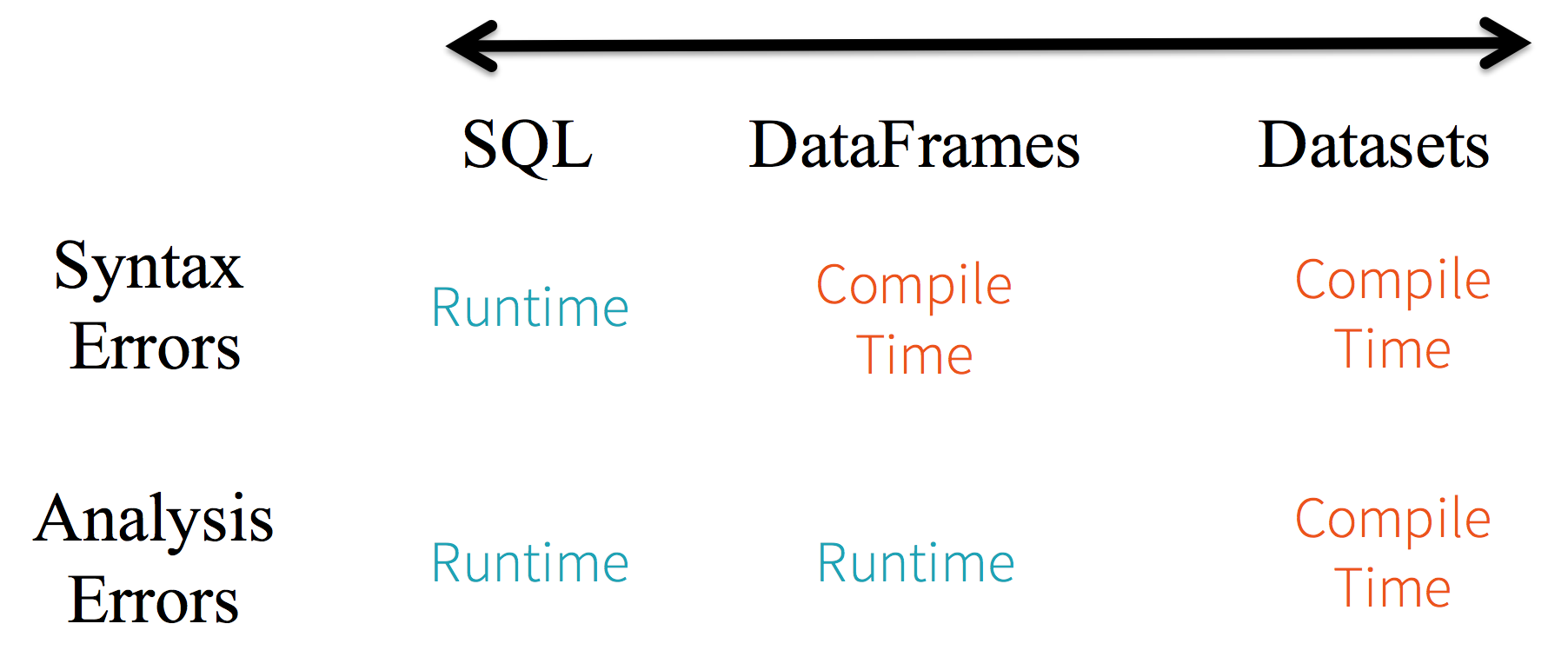
Consider static-typing and runtime safety as a spectrum, with SQL least restrictive to Dataset most restrictive. For instance, in your Spark SQL string queries, you won’t know a syntax error until runtime (which could be costly), whereas in DataFrames and Datasets you can catch errors at compile time (which saves developer-time and costs). That is, if you invoke a function in DataFrame that is not part of the API, the compiler will catch it. However, it won’t detect a non-existing column name until runtime.
从SQL的最小约束到Dataset的最严格约束,把静态类型和运行时安全想像成一个图谱。比如,如果你用的是Spark SQL的查询语句,要直到运行时你才会发现有语法错误(这样做代价很大),而如果你用的是DataFrame和Dataset,你在编译时就可以捕获错误(这样就节省了开发者的时间和整体代价)。也就是说,当你在DataFrame中调用了API之外的函数时,编译器就可以发现这个错。不过,如果你使用了一个不存在的字段名字,那就要到运行时才能发现错误了。
- spectrum [ˈspɛktrəm] 光谱;波谱;范围;系列 图谱
- restrictive [rɪˈstrɪktɪv] 限制的;约束的;限定的
- detect [dɪˈtɛkt] 查明,发现;洞察;侦察,侦查;[电子学]检波
At the far end of the spectrum is Dataset, most restrictive. Since Dataset APIs are all expressed as lambda functions and JVM typed objects, any mismatch of typed-parameters will be detected at compile time. Also, your analysis error can be detected at compile time too, when using Datasets, hence saving developer-time and costs.
图谱的另一端是最严格的Dataset。因为Dataset API都是用lambda函数和JVM类型对象表示的,所有不匹配的类型参数都可以在编译时发现。而且在使用Dataset时,你的分析错误也会在编译时被发现,这样就节省了开发者的时间和代价。
- since [sɪns] 因为;既然;自从…以来;自从…的时候起
- hence [hɛns] 从此;因此,所以;从此处
All this translates to is a spectrum of type-safety along syntax and analysis error in your Spark code, with Datasets as most restrictive yet productive for a developer.
所有这些最终都被解释成关于类型安全的图谱,内容就是你的Spark代码里的语法和分析错误。在图谱中,Dataset是最严格的一端,但对于开发者来说也是效率最高的。
4.2 High-level abstraction and custom view into structured and semi-structured data
关于结构化和半结构化数据的高级抽象和定制视图
DataFrames as a collection of Datasets[Row] render a structured custom view into your semi-structured data. For instance, let’s say, you have a huge IoT device event dataset, expressed as JSON. Since JSON is a semi-structured format, it lends itself well to employing Dataset as a collection of strongly typed-specific Dataset[DeviceIoTData].
把DataFrame当成Dataset[Row]的集合,就可以对你的半结构化数据有了一个结构化的定制视图。比如,假如你有个非常大量的用JSON格式表示的物联网设备事件数据集。因为JSON是半结构化的格式,那它就非常适合采用Dataset来作为强类型化的Dataset[DeviceIoTData]的集合。
- IoT Internet of things 物联网
- lend [lɛnd] 增加;增添;给…增加;给予
- employ [ɛmˈplɔɪ] 雇用;使用,利用 采用
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}
You could express each JSON entry as DeviceIoTData, a custom object, with a Scala case class.
你可以用一个Scala Case Class来把每条JSON记录都表示为一条DeviceIoTData,一个定制化的对象。
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
Next, we can read the data from a JSON file.
接下来,我们就可以从一个JSON文件中读入数据。
// read the json file and create the dataset from the // case class DeviceIoTData // ds is now a collection of JVM Scala objects DeviceIoTData val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]
Three things happen here under the hood in the code above:
- Spark reads the JSON, infers the schema, and creates a collection of DataFrames.
- At this point, Spark converts your data into DataFrame = Dataset[Row], a collection of generic Row object, since it does not know the exact type.
- Now, Spark converts the Dataset[Row] -> Dataset[DeviceIoTData] type-specific Scala JVM object, as dictated by the class DeviceIoTData.
上面的代码其实可以细分为三步:
- Spark读入JSON,根据模式创建出一个DataFrame的集合;
- 在这时候,Spark把你的数据用“DataFrame = Dataset[Row]”进行转换,变成一种通用行对象的集合,因为这时候它还不知道具体的类型;
- 然后,Spark就可以按照类DeviceIoTData的定义,转换出“Dataset[Row] -> Dataset[DeviceIoTData]”这样特定类型的Scala JVM对象了。
- hood [hʊd] 兜帽;头巾;车篷;引擎罩 罩上;覆盖
- infer [ɪnˈfɚ] 推断;猜想,推理;暗示;意指
Most of us have who work with structured data are accustomed to viewing and processing data in either columnar manner or accessing specific attributes within an object. With Dataset as a collection of Dataset[ElementType] typed objects, you seamlessly get both compile-time safety and custom view for strongly-typed JVM objects. And your resulting strongly-typed Dataset[T] from above code can be easily displayed or processed with high-level methods.
许多和结构化数据打过交道的人都习惯于用列的模式查看和处理数据,或者访问对象中的某个特定属性。将Dataset作为一个有类型的Dataset[ElementType]对象的集合,你就可以非常自然地又得到编译时安全的特性,又为强类型的JVM对象获得定制的视图。而且你用上面的代码获得的强类型的Dataset[T]也可以非常容易地用高级方法展示或处理。
- accustom [əˈkʌstəm] 使习惯

4.3 Ease-of-use of APIs with structure
方便易用的结构化API
Although structure may limit control in what your Spark program can do with data, it introduces rich semantics and an easy set of domain specific operations that can be expressed as high-level constructs. Most computations, however, can be accomplished with Dataset’s high-level APIs. For example, it’s much simpler to perform agg, select, sum, avg, map, filter, or groupBy operations by accessing a Dataset typed object’s DeviceIoTData than using RDD rows’ data fields.
虽然结构化可能会限制你的Spark程序对数据的控制,但它却提供了丰富的语义,和方便易用的特定领域内的操作,后者可以被表示为高级结构。事实上,用Dataset的高级API可以完成大多数的计算。比如,它比用RDD数据行的数据字段进行agg、select、sum、avg、map、filter或groupBy等操作简单得多,只需要处理Dataset类型的DeviceIoTData对象即可。
Expressing your computation in a domain specific API is far simpler and easier than with relation algebra type expressions (in RDDs). For instance, the code below will filter() and map() create another immutable Dataset.
用一套特定领域内的API来表达你的算法,比用RDD来进行关系代数运算简单得多。比如,下面的代码将用filter()和map()来创建另一个不可变Dataset。
- algebra [ˈældʒəbrə] 代数学,代数
- relation algebra 关系代数
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read,
// and expressive
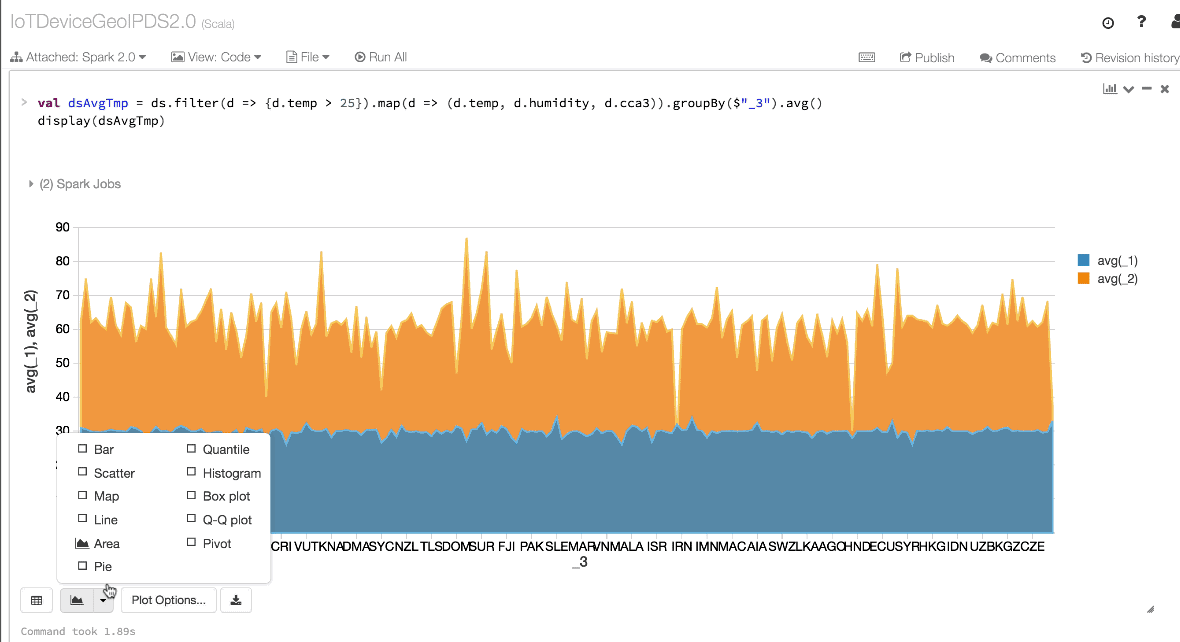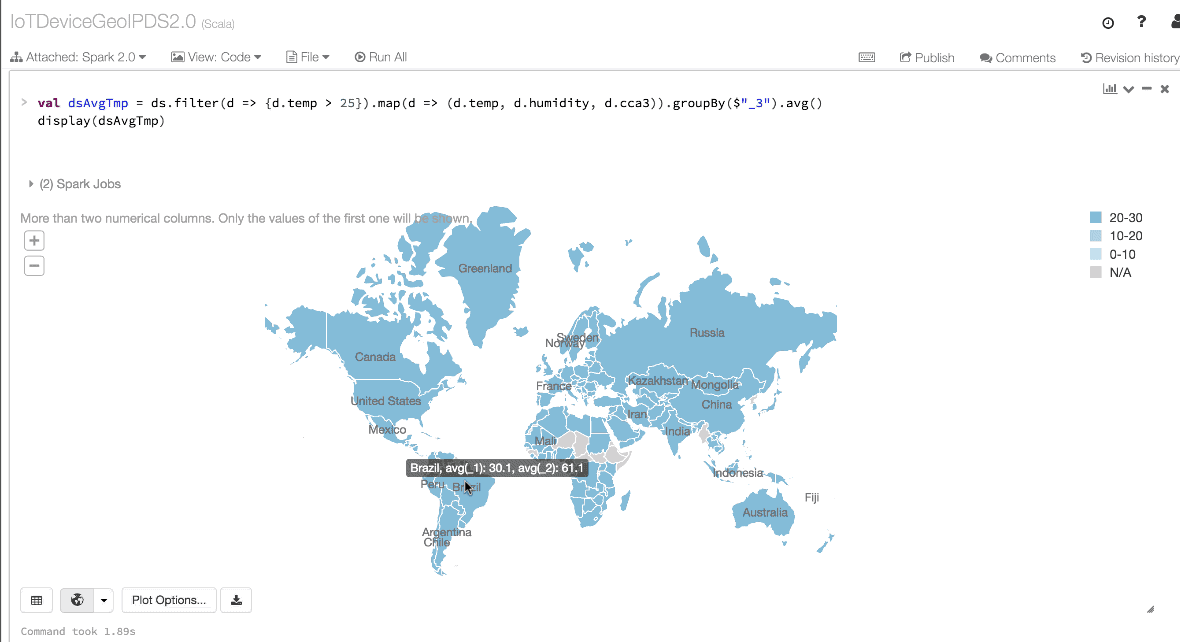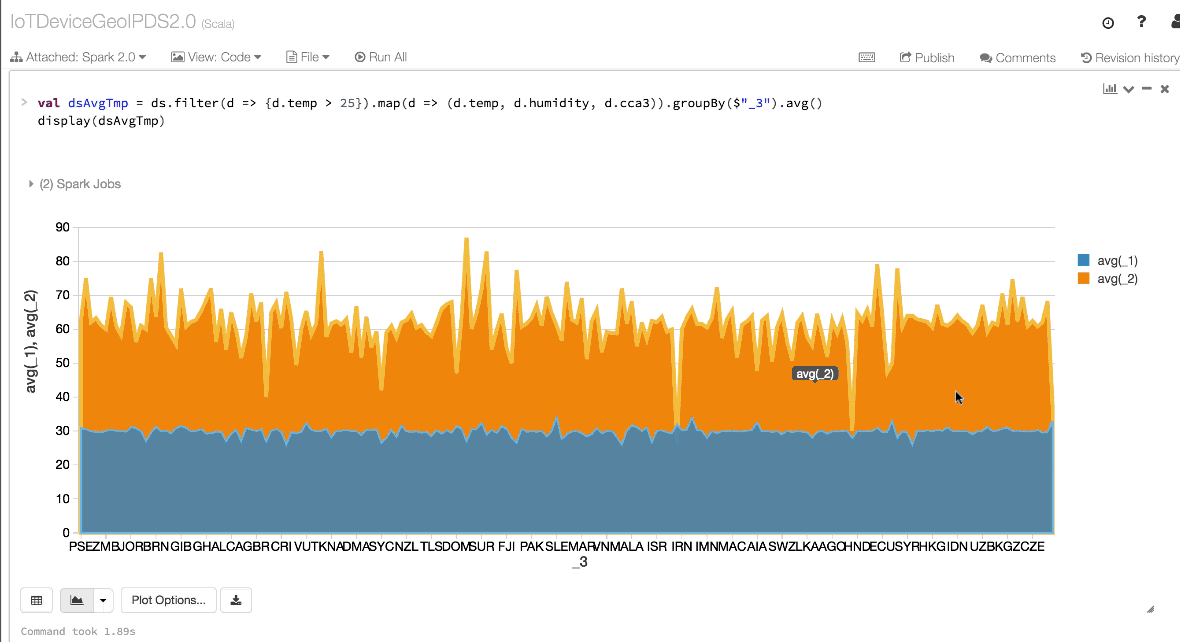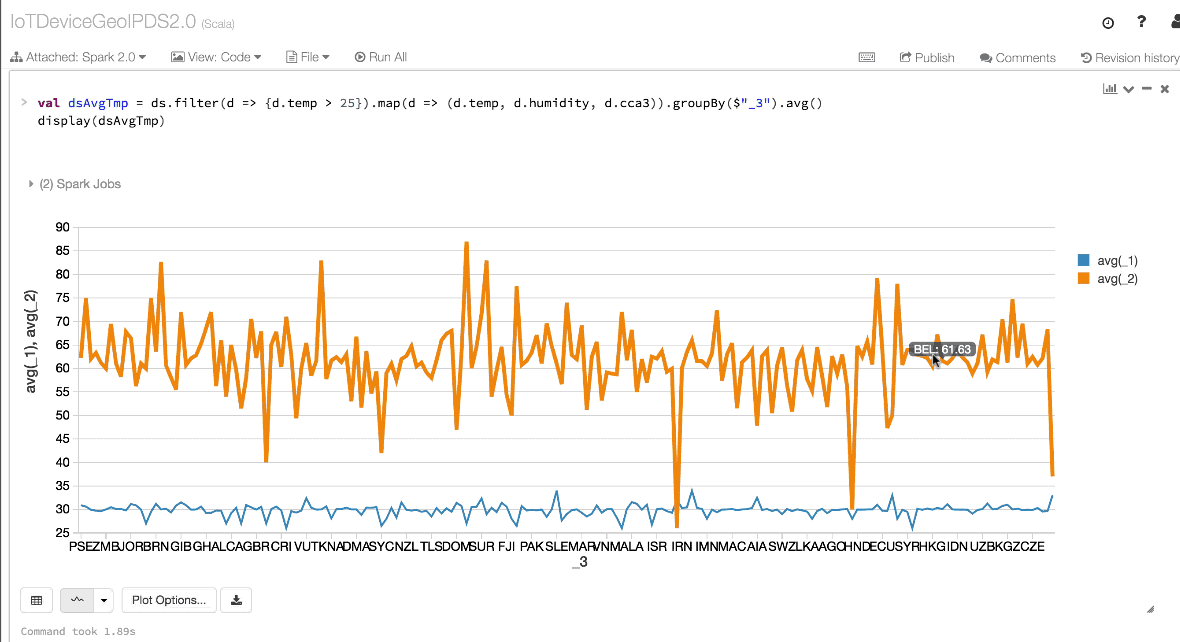
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)
4.4 Performance and Optimization
性能与优化
Along with all the above benefits, you cannot overlook the space efficiency and performance gains in using DataFrames and Dataset APIs for two reasons.
除了上述优点之外,你还要看到使用DataFrame和Dataset API带来的空间效率和性能提升。原因有如下两点:
- space efficiency 空间效率
- performance gains 性能提升
First, because DataFrame and Dataset APIs are built on top of the Spark SQL engine, it uses Catalyst to generate an optimized logical and physical query plan. Across R, Java, Scala, or Python DataFrame/Dataset APIs, all relation type queries undergo the same code optimizer, providing the space and speed efficiency. Whereas the Dataset[T] typed API is optimized for data engineering tasks, the untyped Dataset[Row] (an alias of DataFrame) is even faster and suitable for interactive analysis.
首先,因为DataFrame和Dataset API都是基于Spark SQL引擎构建的,它使用Catalyst来生成优化后的逻辑和物理查询计划。所有R、Java、Scala或Python的DataFrame/Dataset API,所有的关系型查询的底层使用的都是相同的代码优化器,因而会获得空间和速度上的效率。尽管有类型的Dataset[T] API是对数据处理任务优化过的,无类型的Dataset[Row](别名DataFrame)却运行得更快,适合交互式分析。
- undergo [ˌʌndərˈgoʊ] 经历,经验;遭受,承受

Second, since Spark as a compiler understands your Dataset type JVM object, it maps your type-specific JVM object to Tungsten’s internal memory representation using Encoders. As a result, Tungsten Encoders can efficiently serialize/deserialize JVM objects as well as generate compact bytecode that can execute at superior speeds.
其次,Spark作为一个编译器,它可以理解Dataset类型的JVM对象,它会使用编码器来把特定类型的JVM对象映射成Tungsten的内部内存表示。结果,Tungsten的编码器就可以非常高效地将JVM对象序列化或反序列化,同时生成压缩字节码,这样执行效率就非常高了。
4.5 When should I use DataFrames or Datasets?
- If you want rich semantics, high-level abstractions, and domain specific APIs, use DataFrame or Dataset.
- If your processing demands high-level expressions, filters, maps, aggregation, averages, sum, SQL queries, columnar access and use of lambda functions on semi-structured data, use DataFrame or Dataset.
- If you want higher degree of type-safety at compile time, want typed JVM objects, take advantage of Catalyst optimization, and benefit from Tungsten’s efficient code generation, use Dataset.
- If you want unification and simplification of APIs across Spark Libraries, use DataFrame or Dataset.
- If you are a R user, use DataFrames.
- If you are a Python user, use DataFrames and resort back to RDDs if you need more control.
该什么时候使用DataFrame或Dataset呢?
- 如果你需要丰富的语义、高级抽象和特定领域专用的API,那就使用DataFrame或Dataset;
- 如果你的处理需要对半结构化数据进行高级处理,如filter、map、aggregation、average、sum、SQL查询、列式访问或使用lambda函数,那就使用DataFrame或Dataset;
- 如果你想在编译时就有高度的类型安全,想要有类型的JVM对象,用上Catalyst优化,并得益于Tungsten生成的高效代码,那就使用Dataset;
- 如果你想在不同的Spark库之间使用一致和简化的API,那就使用DataFrame或Dataset;
- 如果你是R语言使用者,就用DataFrame;
- 如果你是Python语言使用者,就用DataFrame,在需要更细致的控制时就退回去使用RDD;
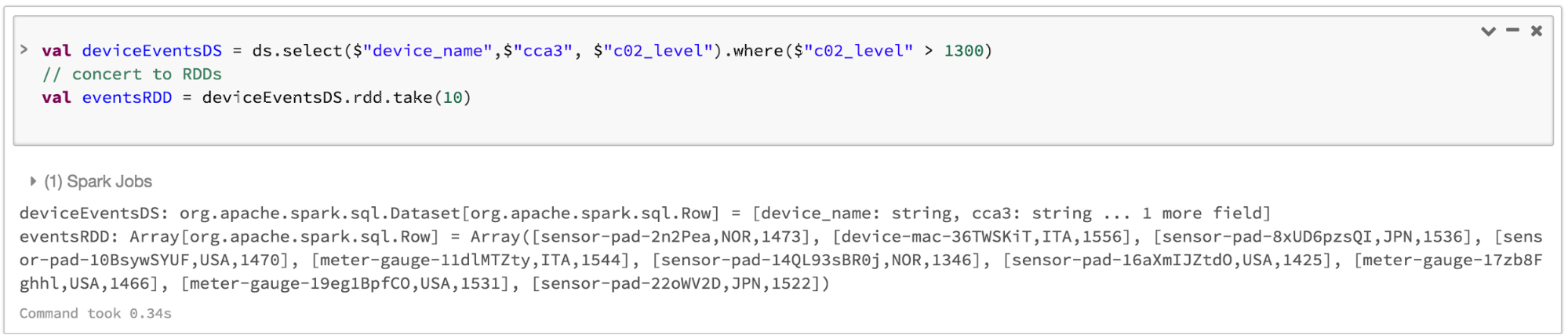
Note that you can always seamlessly interoperate or convert from DataFrame and/or Dataset to an RDD, by simple method call .rdd. For instance,
注意只需要简单地调用一下.rdd,就可以无缝地将DataFrame或Dataset转换成RDD。例子如下:
- interoperate [ˌɪntə'ɒpəreɪt] 交互操作
// select specific fields from the Dataset, apply a predicate // using the where() method, convert to an RDD, and show first 10 // RDD rows val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300) // convert to RDDs and take the first 10 rows val eventsRDD = deviceEventsDS.rdd.take(10)
5、Bringing It All Together
总结
In summation, the choice of when to use RDD or DataFrame and/or Dataset seems obvious. While the former offers you low-level functionality and control, the latter allows custom view and structure, offers high-level and domain specific operations, saves space, and executes at superior speeds.
总之,在什么时候该选用RDD、DataFrame或Dataset看起来好像挺明显。前者可以提供底层的功能和控制,后者支持定制的视图和结构,可以提供高级和特定领域的操作,节约空间并快速运行。
As we examined the lessons we learned from early releases of Spark—how to simplify Spark for developers, how to optimize and make it performant—we decided to elevate the low-level RDD APIs to a high-level abstraction as DataFrame and Dataset and to build this unified data abstraction across libraries atop Catalyst optimizer and Tungsten.
当我们回顾从早期版本的Spark中获得的经验教训时,我们问自己该如何为开发者简化Spark呢?该如何优化它,让它性能更高呢?我们决定把底层的RDD API进行高级抽象,成为DataFrame和Dataset,用它们在Catalyst优化器和Tungsten之上构建跨库的一致数据抽象。
- elevate [ˈɛləˌvet] 提高;提升;举起;鼓舞
- atop [əˈtɑ:p] 在(…)顶上
Pick one—DataFrames and/or Dataset or RDDs APIs—that meets your needs and use-case, but I would not be surprised if you fall into the camp of most developers who work with structure and semi-structured data.
DataFrame和Dataset,或RDD API,按你的实际需要和场景选一个来用吧,当你像大多数开发者一样对数据进行结构化或半结构化的处理时,我不会有丝毫惊讶。
- camp [kæmp] 营地,工地宿舍;阵营;兵营;野营地
- fall into the camp 掉进营地 像
参考文献
- https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
- http://www.infoq.com/cn/articles/three-apache-spark-apis-rdds-dataframes-and-datasets
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【虾皮★csAxp】。
如果,您还想与更多的爱好者进一步交流,不防加入QQ群【虾皮工作室-ABC大数据(232658451)】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

