
机器学习降维算法二:LDA(Linear Discriminant Analysis)
很多基础知识有些遗忘了,也算作是一种复习。我尽量推导的关键的地方写写,建议大家还是要手动推一推公式增加理解。
Linear Discriminant Analysis (也有叫做Fisher Linear Discriminant)是一种有监督的(supervised)线性降维算法。与PCA保持数据信息不同,LDA是为了使得降维后的数据点尽可能地容易被区分!
假设原始数据表示为X,(m*n矩阵,m是维度,n是sample的数量)
既然是线性的,那么就是希望找到映射向量a,使得 a'X后的数据点能够保持以下两种性质:
1、同类的数据点尽可能的接近(within class)
2、不同类的数据点尽可能的分开(between class)
来看一个例子:两堆点会这样被降维

再看上次PCA用的这张图,如果图中两堆点是两类的话,那么我们就希望他们能够投影到轴1去(PCA结果为轴2),这样在一维空间中也是很容易区分的。

接下来是推导,因为这里写公式很不方便,我就引用Deng Cai老师的一个ppt中的一小段图片了:
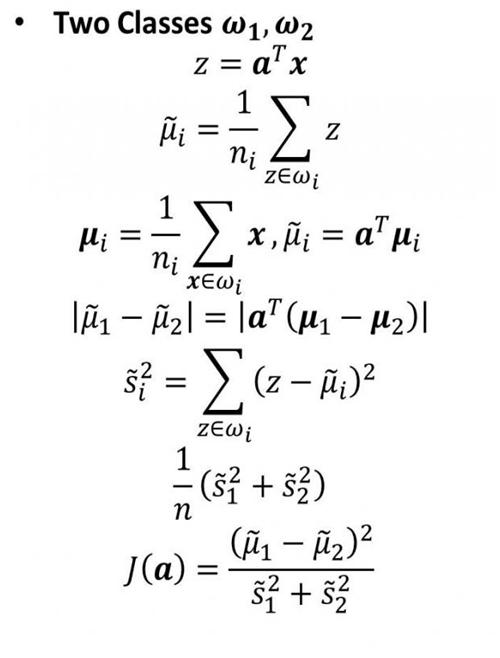
a是投影向量,z是映射后的数据,x是原始数据,μ是一类点的质心(平均值)。
思路还是非常清楚的,目标函数就是最后一行J(a),μ(一飘)就是映射后的中心用来评估类间距,s(一飘)就是映射后的点与中心的距离之和用来评估类内距。J(a)正好就是从上述两个性质演化出来的。

因此两类情况下:
加上a'a=1的条件(类似于PCA)
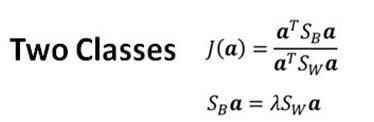
可以拓展成多类:

以上公式推导可以具体参考pattern classification书中的相应章节,讲fisher discirminant的
OK,计算映射向量a就是求最大特征向量,也可以是前几个最大特征向量组成矩阵A=[a1,a2,....ak]之后,就可以对新来的点进行降维了:
y = A'X
(线性的一个好处就是计算方便!)
可以发现,LDA最后也是转化成为一个求矩阵特征向量的问题,和PCA很像,事实上很多其他的算法也是归结于这一类,一般称之为谱(spectral)方法。
线性降维算法我想最重要的就是PCA和LDA了,后面还会介绍一些非线性的方法。


