

python——BeautifulSoup4解析器,JSON与JsonPATH,多线程爬虫,动态HTML处理
爬虫的自我修养_3
一、CSS 选择器:BeautifulSoup4
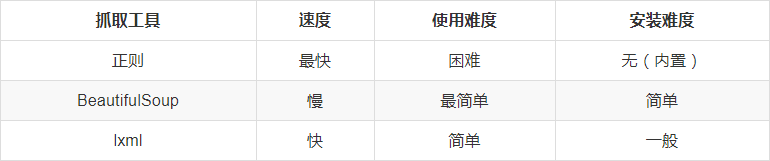
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。使用 pip 安装即可:
pip install beautifulsoup4
四大对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
1. Tag
Tag 通俗点讲就是 HTML 中的一个个标签,例如:
<head><title>The Dormouse's story</title></head> <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a> <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
上面的 title head a p等等 HTML 标签加上里面包括的内容就是 Tag,那么试着使用 Beautiful Soup 来获取 Tags:
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建 Beautiful Soup 对象
soup = BeautifulSoup(html)
print(soup.title)
# <title>The Dormouse's story</title>
print(soup.head)
# <head><title>The Dormouse's story</title></head>
print(soup.a) # 只能取出第一个a标签
# <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print(soup.p)
# <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
print(type(soup.p)) # 类型
# <class 'bs4.element.Tag'>
# 取出所有的a标签并获取他们的属性,注意用的是i["..."]
for i in soup.find_all('a'):
print(i)
print(i['id'])
print(i['class'])
print(i['href'])
# <a class="sister" href="http://example.com/elsie" id="link1"
# name="6123">123</a>
# link1
# ['sister']
# http://example.com/elsie
对于 Tag,它有两个重要的属性,是 name 和 attrs
print(soup.name)
# [document] #soup 对象本身比较特殊,它的 name 即为 [document]
print(soup.head.name)
# head 对于其他内部标签,输出的值便为标签本身的名称
# 标签内部的name是算在attrs中的
# {'name': '我是a标签', 'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
print(soup.p.attrs)
# {'class': ['title'], 'name': 'dromouse'}
# 在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
print(soup.p['class'] # soup.p.get('class'))
# ['title'] #还可以利用get方法,传入属性的名称,二者是等价的
soup.p['class'] = "newClass"
print(soup.p) # 可以对这些属性和内容等等进行修改
# <p class="newClass" name="dromouse"><b>The Dormouse's story</b></p>
del soup.p['class'] # 还可以对这个属性进行删除
print(soup.p)
# <p name="dromouse"><b>The Dormouse's story</b></p>
2. NavigableString
使用 .string 方法获取标签中的内容
print(soup.p.string) # The Dormouse's story print(type(soup.p.string)) # <class 'bs4.element.NavigableString'>
3. BeautifulSoup
BeautifulSoup 对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称。
soup = BeautifulSoup(html,'lxml') # BeautifulSoup对象
print(type(soup.name))
# <type 'unicode'>
print(soup.name)
# [document]
print(soup.attrs) # 文档本身的属性为空
# {}
4. Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。
print(soup.a) # <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a> print(soup.a.string) # Elsie ,在输出的时候把<-!->注释符号去掉了 print(type(soup.a.string)) # <class 'bs4.element.Comment'>
遍历文档树
1. 直接子节点 :.contents .children 属性
.content
tag 的 .content 属性可以将tag的子节点以列表的方式输出(把当前标签下的所有标签以列表的方式输出)
print soup.body.contents # 也可以直接遍历HTML文档
# [<p class="title" name="dromouse"><b>The Dormouse's story</b></p>, '\n', <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1" name="6123">123</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, '\n', <p class="story">...</p>, '\n']
输出方式为列表,我们可以用列表索引来获取它的某一个元素
print soup.head.contents[0] # <p class="title" name="dromouse"><b>The Dormouse's story</b></p>
.children
它返回的不是一个 list,不过我们可以通过遍历获取所有子节点。
我们打印输出 .children 看一下,可以发现它是一个 list 生成器对象
print(soup.head.children)
#<listiterator object at 0x7f71457f5710>
for child in soup.body.children: # 也可以直接遍历整个HTML文档
print(child)
结果
<p class="title" name="dromouse"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p>
2. 所有子孙节点: .descendants 属性
.contents 和 .children 属性仅包含tag的直接子节点,.descendants 属性可以对所有tag的子孙节点进行递归循环,和 children类似(也是list生成器),我们也需要遍历获取其中的内容。
html = """
<html>
<head>
<title>The Dormouse's story<a>sadcx</a></title>
</head>
"""
bs = BeautifulSoup(html,'lxml')
for child in bs.head.descendants: # 也可以直接遍历整个HTML文档
print(child)
结果
<title>The Dormouse's story<a>sadcx</a></title> The Dormouse's story <a>sadcx</a> sadcx
搜索文档树
1.find_all(name, attrs, recursive, text, **kwargs)
1)name 参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉
A.传字符串
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的<b>标签:
print(soup.find_all('b'))
# [<b>The Dormouse's story</b>]
print(soup.find_all('a'))
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
B.传正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
C.传列表
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有<a>标签和<b>标签:
soup.find_all(["a", "b"]) # [<b>The Dormouse's story</b>, # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
2)keyword 参数(属性)
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
soup.find_all(input,attrs={"name":"_xsrf","class":"c1","id":"link2"})
# 属性也可以以字典的格式传
3)text 参数
通过 text 参数可以搜搜文档中的字符串内容,与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表
soup.find_all(text="Elsie")
# [u'Elsie']
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(text=re.compile("Dormouse"))
[u"The Dormouse's story", u"The Dormouse's story"]
2.find(name, attrs, recursive, text, **kwargs)
find方法和find_all的使用方法是一样的,只不过find只找一个值,find_all返回的是一个列表
CSS选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法.
-
写 CSS 时,标签名不加任何修饰,类名前加
.,id名前加# -
在这里我们也可以利用类似的方法来筛选元素,用到的方法是
soup.select(),返回类型是list
(1)通过标签名查找
print soup.select('title')
#[<title>The Dormouse's story</title>]
print soup.select('a')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('b')
#[<b>The Dormouse's story</b>]
(2)通过类名查找
print soup.select('.sister')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
(3)通过 id 名查找
print soup.select('#link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
(4)组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print soup.select('p #link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
直接子标签查找,则使用 > 分隔
print soup.select("head > title")
#[<title>The Dormouse's story</title>]
(5)属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print soup.select('a[class="sister"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
(6) 获取内容
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('title'))
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print title.get_text()


1 from bs4 import BeautifulSoup 2 import requests,time 3 4 # 请求报头 5 headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"} 6 7 def captcha(captcha_data): 8 """ 9 处理验证码 10 :return: 11 """ 12 with open("captcha.jpg",'wb')as f: 13 f.write(captcha_data) 14 text = input("请输入验证码:") 15 return text # 返回用户输入的验证码 16 17 def zhihuLogin(): 18 """ 19 获取页面的_xsrf 20 验证码-抓包工具 21 发送post表单请求-抓包工具 22 :return: 23 """ 24 25 # 相当于urllib2,通过HTTPCookieProcessor()处理器类构建一个处理器对象, 26 # 再用urllib2.build_opener构建一个自定义的opener来保存cookie 27 # 构建一个Session对象,可以保存页面Cookie 28 sess = requests.session() # 创建一个能够储存cookie的opener 29 30 # 首先获取登录页面,找到需要POST的数据(_xsrf),同时会记录当前网页的Cookie值 31 # 也可以直接用requests.get("...")发送请求,但这样就没法保存cookie值了 32 # 获取HTML内容可以用.text/.content来获取 33 html = sess.get('https://www.zhihu.com/#signin',headers=headers).text # get <==> 发送get请求 34 35 # 调用lxml解析库 36 bs = BeautifulSoup(html, 'lxml') 37 38 # _xsrf 作用是防止CSRF攻击(跨站请求伪造),通常叫跨域攻击,是一种利用网站对用户的一种信任机制来做坏事 39 # 跨域攻击通常通过伪装成网站信任的用户的请求(利用Cookie),盗取用户信息、欺骗web服务器 40 # 所以网站会通过设置一个隐藏字段来存放这个MD5字符串,这个字符串用来校验用户Cookie和服务器Session的一种方式 41 42 # 找到name属性值为 _xsrf 的input标签,再取出value 的值 43 _xsrf = bs.find("input", attrs={"name":"_xsrf"}).get("value") # 获取_xsrf 44 # 根据UNIX时间戳,匹配出验证码的URL地址 45 # 发送图片的请求,获取图片数据流, 46 captcha_data = sess.get('https://www.zhihu.com/captcha.gif?r=%d&type=login'%(time.time()*1000),headers=headers).content 47 # 调用上面的方法(需要手动输入),获取验证码里的文字 48 captcha_text = captcha(captcha_data) 49 data = { 50 "_xsrf": _xsrf, 51 "phone_num": "xxx", 52 "password": "xxx", 53 "captcha": captcha_text 54 } 55 # 发送登录需要的POST数据,获取登录后的Cookie(保存在sess里) 56 sess.post('https://www.zhihu.com/login/phone_num',data=data,headers=headers) 57 58 # 用已有登录状态的Cookie发送请求,获取目标页面源码 59 response = sess.get("https://www.zhihu.com/people/peng-peng-34-48-53/activities",headers=headers) 60 61 with open("jiaxin.html",'wb') as f: 62 f.write(response.content) 63 64 if __name__ == '__main__': 65 zhihuLogin()
二、JSON与JsonPATH
JSON
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
对象:对象在js中表示为
{ }括起来的内容,数据结构为{ key:value, key:value, ... }的键值对的结构,在面向对象的语言中,key为对象的属性,value为对应的属性值,所以很容易理解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种。数组:数组在js中是中括号
[ ]括起来的内容,数据结构为["Python", "javascript", "C++", ...],取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种。
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
1. json.loads() 字符串 ==> python类型
把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:
import json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}'
print(json.loads(strList))
# [1, 2, 3, 4]
print(json.loads(strDict)) # python3中json数据自动按utf-8存储
# {'city': '北京', 'name': '大猫'}
2. json.dumps() python类型 ==> 字符串
实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串
从python原始类型向json类型的转化对照如下:
import json
dictStr = {"city": "北京", "name": "大猫"}
# 注意:json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
# chardet.detect()返回字典, 其中confidence是检测精确度
print(json.dumps(dictStr))
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}'
print(json.dumps(dictStr, ensure_ascii=False))
# {"city": "北京", "name": "大刘"}
3. json.dump() # 基本不用
将Python内置类型序列化为json对象后写入文件
import json
listStr = [{"city": "北京"}, {"name": "大刘"}]
json.dump(listStr, open("listStr.json","wb"), ensure_ascii=False)
dictStr = {"city": "北京", "name": "大刘"}
json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
4. json.load() # 基本不用
读取文件中json形式的字符串元素 转化成python类型
# json_load.py
import json
strList = json.load(open("listStr.json"))
print strList
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]
strDict = json.load(open("dictStr.json"))
print strDict
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
JsonPath
python3中没有jsonpath,改为jsonpath_rw,用法不明
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击
Download URL链接下载jsonpath,解压之后执行python setup.py install
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。

1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 import urllib2 5 # json解析库,对应到lxml 6 import json 7 # json的解析语法,对应到xpath 8 import jsonpath 9 10 url = "http://www.lagou.com/lbs/getAllCitySearchLabels.json" 11 headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} 12 13 request = urllib2.Request(url, headers = headers) 14 15 response = urllib2.urlopen(request) 16 # 取出json文件里的内容,返回的格式是字符串 17 html = response.read() 18 19 # 把json形式的字符串转换成python形式的Unicode字符串 20 unicodestr = json.loads(html) 21 22 # Python形式的列表 23 city_list = jsonpath.jsonpath(unicodestr, "$..name") 24 25 #for item in city_list: 26 # print item 27 28 # dumps()默认中文为ascii编码格式,ensure_ascii默认为Ture 29 # 禁用ascii编码格式,返回的Unicode字符串,方便使用 30 array = json.dumps(city_list, ensure_ascii=False) 31 #json.dumps(city_list) 32 #array = json.dumps(city_list) 33 34 with open("lagoucity.json", "w") as f: 35 f.write(array.encode("utf-8"))
三、多线程爬虫案例
python多线程简介
一个CPU一次只能执行一个进程,其他进程处于非运行状态 进程里面包含的执行单位叫线程,一个进程包含多个线程 一个进程里面的内存空间是共享的,里面的线程都可以使用这个内存空间 一个线程在使用这个共享空间时,其他线程必须等他结束(通过加锁实现) 锁的作用:防止多个线程同时用这块共享的内存空间,先使用的线程会上一把锁,其他线程想要用的话就要等他用完才可以进去 python中的锁(GIL) python的多线程很鸡肋,所以scrapy框架用的是协程 python多进程适用于:大量密集的并行计算 python多线程适用于:大量密集的I/O操作
Queue(队列对象)
Queue是python中的标准库,可以直接import Queue引用;队列是线程间最常用的交换数据的形式
python下多线程的思考
对于资源,加锁是个重要的环节。因为python原生的list,dict等,都是not thread safe的。而Queue,是线程安全的,因此在满足使用条件下,建议使用队列
-
初始化: class Queue.Queue(maxsize) FIFO 先进先出
-
包中的常用方法:
-
Queue.qsize() 返回队列的大小
-
Queue.empty() 如果队列为空,返回True,反之False
-
Queue.full() 如果队列满了,返回True,反之False
-
Queue.full 与 maxsize 大小对应
-
Queue.get([block[, timeout]])获取队列,timeout等待时间
-
-
创建一个“队列”对象
- import Queue
- myqueue = Queue.Queue(maxsize = 10)
-
将一个值放入队列中
- myqueue.put(10)
-
将一个值从队列中取出
- myqueue.get()
多线程示意图
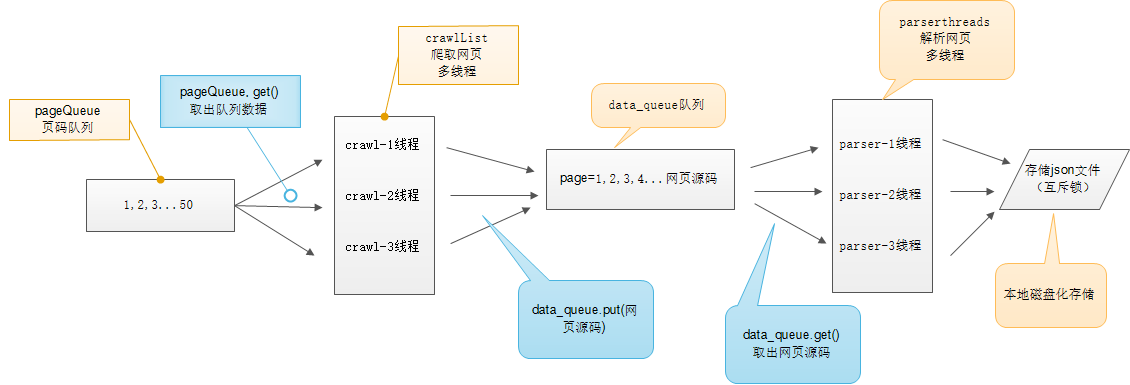
示例:多线程爬取糗事百科上的段子(好好看这个)
import threading,json,time,requests
from lxml import etree
from queue import Queue
class ThreadCrawl(threading.Thread):
def __init__(self,thread_name,pageQueue,dataQueue):
super(ThreadCrawl,self).__init__() # 调用父类初始化方法
self.thread_name = thread_name # 线程名
self.pageQueue = pageQueue # 页码队列
self.dataQueue = dataQueue # 数据队列
self.headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
def run(self):
print("启动"+self.thread_name)
while not self.pageQueue.empty(): # 如果pageQueue为空,采集线程退出循环 Queue.empty() 判断队列是否为空
try:
# 取出一个数字,先进先出
# 可选参数block,默认值为True
#1. 如果对列为空,block为True的话,不会结束,会进入阻塞状态,直到队列有新的数据
#2. 如果队列为空,block为False的话,就弹出一个Queue.empty()异常,
page = self.pageQueue.get(False)
url = "http://www.qiushibaike.com/8hr/page/" + str(page) +"/"
html = requests.get(url,headers = self.headers).text
time.sleep(1) # 等待1s等他全部下完
self.dataQueue.put(html)
except Exception as e:
pass
print("结束" + self.thread_name)
class ThreadParse(threading.Thread):
def __init__(self,threadName,dataQueue,lock):
super(ThreadParse,self).__init__()
self.threadName = threadName
self.dataQueue = dataQueue
self.lock = lock # 文件读写锁
self.headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
def run(self):
print("启动"+self.threadName)
while not self.dataQueue.empty(): # 如果pageQueue为空,采集线程退出循环
try:
html = self.dataQueue.get() # 解析为HTML DOM
text = etree.HTML(html)
node_list = text.xpath('//div[contains(@id, "qiushi_tag_")]') # xpath返回的列表,这个列表就这一个参数,用索引方式取出来,用户名
for i in node_list:
username = i.xpath('.//h2')[0].text # 用户名
user_img = i.xpath('.//img/@src')[0] # 用户头像连接
word_content = i.xpath('.//div[@class="content"]/span')[0].text # 文字内容
img_content = i.xpath('.//img/@src') # 图片内容
zan = i.xpath('./div[@class="stats"]/span[@class="stats-vote"]/i')[0].text # 点赞
comments = i.xpath('./div[@class="stats"]/span[@class="stats-comments"]//i')[0].text # 评论
items = {
"username": username,
"image": user_img,
"word_content": word_content,
"img_content": img_content,
"zan": zan,
"comments": comments
}
# with 后面有两个必须执行的操作:__enter__ 和 _exit__
# 不管里面的操作结果如何,都会执行打开、关闭
# 打开锁、处理内容、释放锁
with self.lock:
with open('qiushi-threading.json123','ab') as f:
# json.dumps()时,里面一定要加 ensure_ascii = False 否则会以ascii嘛的形式进行转码,文件中就不是中文了
f.write((self.threadName+json.dumps(items, ensure_ascii = False)).encode("utf-8") + b'\n')
except Exception as e:
print(e)
def main():
pageQueue = Queue(10) # 页码的队列,表示10个页面,不写表示不限制个数
for i in range(1,11): # 放入1~10的数字,先进先出
pageQueue.put(i)
dataQueue = Queue() # 采集结果(每页的HTML源码)的数据队列,参数为空表示不限制个数
crawlList = ["采集线程1号", "采集线程2号", "采集线程3号"] # 存储三个采集线程的列表集合,留着后面join(等待所有子进程完成在退出程序)
threadcrawl = []
for thread_name in crawlList:
thread = ThreadCrawl(thread_name,pageQueue,dataQueue)
thread.start()
threadcrawl.append(thread)
for i in threadcrawl:
i.join()
print('1')
lock = threading.Lock() # 创建锁
# *** 解析线程一定要在采集线程join(结束)以后写,否则会出现dataQueue.empty()=True(数据队列为空),因为采集线程还没往里面存东西呢 ***
parseList = ["解析线程1号","解析线程2号","解析线程3号"] # 三个解析线程的名字
threadparse = [] # 存储三个解析线程,留着后面join(等待所有子进程完成在退出程序)
for threadName in parseList:
thread = ThreadParse(threadName,dataQueue,lock)
thread.start()
threadparse.append(thread)
for j in threadparse:
j.join()
print('2')
print("谢谢使用!")
if __name__ == "__main__":
main()
四、动态HTML处理
获取JavaScript,jQuery,Ajax...加载的网页数据
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium ,也可以用 第三方管理器 pip用命令安装:
pip install seleniumSelenium 官方参考文档:http://selenium-python.readthedocs.io/index.html
PhantomJS
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
注意:PhantomJS 只能从它的官方网站http://phantomjs.org/download.html) 下载。 因为 PhantomJS 是一个功能完善(虽然无界面)的浏览器而非一个 Python 库,所以它不需要像 Python 的其他库一样安装,但我们可以通过Selenium调用PhantomJS来直接使用。
PhantomJS 官方参考文档:http://phantomjs.org/documentation
快速入门
Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像 BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
# 导入 webdriver
from selenium import webdriver
# 要想调用键盘按键操作需要引入keys包
from selenium.webdriver.common.keys import Keys
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.PhantomJS()
# 如果没有在环境变量指定PhantomJS位置
# driver = webdriver.PhantomJS(executable_path="./phantomjs"))
# get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择 time.sleep(2)
driver.get("http://www.baidu.com/")
# 获取页面名为 wrapper的id标签的文本内容
data = driver.find_element_by_id("wrapper").text
# 打印数据内容
print data
# 打印页面标题 "百度一下,你就知道"
print driver.title
# 生成当前页面快照并保存
driver.save_screenshot("baidu.png")
# id="kw"是百度搜索输入框,输入字符串"长城"
driver.find_element_by_id("kw").send_keys(u"长城")
# id="su"是百度搜索按钮,click() 是模拟点击
driver.find_element_by_id("su").click()
# 获取新的页面快照
driver.save_screenshot("长城.png")
# 打印网页渲染后的源代码
print driver.page_source
# 获取当前页面Cookie
print driver.get_cookies()
# ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
# ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')
# 输入框重新输入内容
driver.find_element_by_id("kw").send_keys("itcast")
# 模拟Enter回车键
driver.find_element_by_id("su").send_keys(Keys.RETURN)
# 清除输入框内容
driver.find_element_by_id("kw").clear()
# 生成新的页面快照
driver.save_screenshot("itcast.png")
# 获取当前url
print driver.current_url
# 关闭当前页面,如果只有一个页面,会关闭浏览器
# driver.close()
# 关闭浏览器
driver.quit()
页面操作
Selenium 的 WebDriver提供了各种方法来寻找元素,假设下面有一个表单输入框:
<input type="text" name="user-name" id="passwd-id" />
那么:
# 获取id标签值
element = driver.find_element_by_id("passwd-id")
# 获取name标签值
element = driver.find_element_by_name("user-name")
# 获取标签名值
element = driver.find_elements_by_tag_name("input")
# 也可以通过XPath来匹配
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
定位UI元素 (WebElements)
关于元素的选取,有如下的API 单个元素选取
find_element_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
-
By ID
<div id="coolestWidgetEvah">...</div>-
实现
element = driver.find_element_by_id("coolestWidgetEvah") ------------------------ or ------------------------- from selenium.webdriver.common.by import By element = driver.find_element(by=By.ID, value="coolestWidgetEvah")
-
-
By Class Name
<div class="cheese"><span>Cheddar</span></div><div class="cheese"><span>Gouda</span></div>-
实现
cheeses = driver.find_elements_by_class_name("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheeses = driver.find_elements(By.CLASS_NAME, "cheese")
-
-
By Tag Name
<iframe src="..."></iframe>-
实现
frame = driver.find_element_by_tag_name("iframe") ------------------------ or ------------------------- from selenium.webdriver.common.by import By frame = driver.find_element(By.TAG_NAME, "iframe")
-
-
By Name
<input name="cheese" type="text"/>-
实现
cheese = driver.find_element_by_name("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.NAME, "cheese")
-
-
By Link Text
<a href="http://www.google.com/search?q=cheese">cheese</a>-
实现
cheese = driver.find_element_by_link_text("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.LINK_TEXT, "cheese")
-
-
By Partial Link Text
<a href="http://www.google.com/search?q=cheese">search for cheese</a>>-
实现
cheese = driver.find_element_by_partial_link_text("cheese") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.PARTIAL_LINK_TEXT, "cheese")
-
-
By CSS
<div id="food"><span class="dairy">milk</span><span class="dairy aged">cheese</span></div>-
实现
cheese = driver.find_element_by_css_selector("#food span.dairy.aged") ------------------------ or ------------------------- from selenium.webdriver.common.by import By cheese = driver.find_element(By.CSS_SELECTOR, "#food span.dairy.aged")
-
-
By XPath
<input type="text" name="example" /> <INPUT type="text" name="other" />-
实现
inputs = driver.find_elements_by_xpath("//input") ------------------------ or ------------------------- from selenium.webdriver.common.by import By inputs = driver.find_elements(By.XPATH, "//input")
-
鼠标动作链
有些时候,我们需要再页面上模拟一些鼠标操作,比如双击、右击、拖拽甚至按住不动等,我们可以通过导入 ActionChains 类来做到:
示例:
#导入 ActionChains 类
from selenium.webdriver import ActionChains
# 鼠标移动到 ac 位置
ac = driver.find_element_by_xpath('element')
ActionChains(driver).move_to_element(ac).perform()
# 在 ac 位置单击
ac = driver.find_element_by_xpath("elementA")
ActionChains(driver).move_to_element(ac).click(ac).perform()
# 在 ac 位置双击
ac = driver.find_element_by_xpath("elementB")
ActionChains(driver).move_to_element(ac).double_click(ac).perform()
# 在 ac 位置右击
ac = driver.find_element_by_xpath("elementC")
ActionChains(driver).move_to_element(ac).context_click(ac).perform()
# 在 ac 位置左键单击hold住
ac = driver.find_element_by_xpath('elementF')
ActionChains(driver).move_to_element(ac).click_and_hold(ac).perform()
# 将 ac1 拖拽到 ac2 位置
ac1 = driver.find_element_by_xpath('elementD')
ac2 = driver.find_element_by_xpath('elementE')
ActionChains(driver).drag_and_drop(ac1, ac2).perform()
填充表单
我们已经知道了怎样向文本框中输入文字,但是有时候我们会碰到<select> </select>标签的下拉框。直接点击下拉框中的选项不一定可行。
<select id="status" class="form-control valid" onchange="" name="status">
<option value=""></option>
<option value="0">未审核</option>
<option value="1">初审通过</option>
<option value="2">复审通过</option>
<option value="3">审核不通过</option>
</select>
Selenium专门提供了Select类来处理下拉框。 其实 WebDriver 中提供了一个叫 Select 的方法,可以帮助我们完成这些事情:
# 导入 Select 类
from selenium.webdriver.support.ui import Select
# 找到 name 的选项卡
select = Select(driver.find_element_by_name('status'))
#
select.select_by_index(1)
select.select_by_value("0")
select.select_by_visible_text(u"未审核")
以上是三种选择下拉框的方式,它可以根据索引来选择,可以根据值来选择,可以根据文字来选择。注意:
- index 索引从 0 开始
- value是option标签的一个属性值,并不是显示在下拉框中的值
- visible_text是在option标签文本的值,是显示在下拉框的值
全部取消选择怎么办呢?很简单:
select.deselect_all()
弹窗处理
当你触发了某个事件之后,页面出现了弹窗提示,处理这个提示或者获取提示信息方法如下:
alert = driver.switch_to_alert()
页面切换
一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下:
driver.switch_to.window("this is window name")
也可以使用 window_handles 方法来获取每个窗口的操作对象。例如:
for handle in driver.window_handles:
driver.switch_to_window(handle)
页面前进和后退
操作页面的前进和后退功能:
driver.forward() #前进
driver.back() # 后退
Cookies
获取页面每个Cookies值,用法如下
for cookie in driver.get_cookies():
print "%s -> %s" % (cookie['name'], cookie['value'])
删除Cookies,用法如下
# By name
driver.delete_cookie("CookieName")
# all
driver.delete_all_cookies()
页面等待
注意:这是非常重要的一部分!!
现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,那么就会抛出NullPointer的异常。
为了避免这种元素定位困难而且会提高产生 ElementNotVisibleException 的概率。所以 Selenium 提供了两种等待方式,一种是隐式等待,一种是显式等待。
隐式等待是等待特定的时间,显式等待是指定某一条件直到这个条件成立时继续执行。
显式等待
显式等待指定某个条件,然后设置最长等待时间。如果在这个时间还没有找到元素,那么便会抛出异常了。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("http://www.xxxxx.com/loading")
try:
# 页面一直循环,直到 id="myDynamicElement" 出现
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会 0.5s 调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己写某些等待条件了。
title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – it is Displayed and Enabled.
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待
隐式等待比较简单,就是简单地设置一个等待时间,单位为秒。
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然如果不设置,默认等待时间为0。
示例一:使用Selenium + PhantomJS模拟豆瓣网登录
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
# 实例化一个浏览器对象
driver = webdriver.PhantomJS("F:/Various plug-ins/phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver.get("http://www.douban.com")
# 输入账号密码
driver.find_element_by_name("form_email").send_keys("xx@qq.com") # 找到name=..的位置输入值
driver.find_element_by_name("form_password").send_keys("xxx")
# 模拟点击登录
driver.find_element_by_xpath("//input[@class='bn-submit']").click() # 按照xpath的方式找到登录按钮,点击
# 等待3秒
time.sleep(3)
# 生成登陆后快照
driver.save_screenshot("douban.png")
with open("douban.html", "wb") as file:
file.write(driver.page_source.encode("utf-8")) # driver.page_source获取当前页面的html
driver.quit() # 关闭浏览器
示例2:模拟动态页面的点击(斗鱼)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import unittest,time
from selenium import webdriver
from bs4 import BeautifulSoup as bs
class douyu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.PhantomJS("F:/Various plug-ins/phantomjs-2.1.1-windows/bin/phantomjs.exe")
self.num = 0
def testDouyu(self):
self.driver.get("https://www.douyu.com/directory/all")
while True:
soup = bs(self.driver.page_source,'lxml')
names = soup.find_all('h3',attrs={"class" : "ellipsis"})
numbers = soup.find_all("span", attrs={"class" :"dy-num fr"})
for name, number in zip(names, numbers):
print u"观众人数: -" + number.get_text().strip() + u"-\t房间名: " + name.get_text().strip()
self.num += 1
if self.driver.page_source.find("shark-pager-disable-next") != -1:
break
time.sleep(0.5) # 要sleep一会,等页面加载完,否则会报错
self.driver.find_element_by_class_name("shark-pager-next").click()
# 单元测试模式的测试结束执行的方法
def tearDown(self):
# 退出PhantomJS()浏览器
print "当前网站直播人数" + str(self.num)
# print "当前网站观众人数" + str(self.count)
self.driver.quit()
if __name__ == "__main__":
# 启动测试模块,必须这样写
unittest.main()
示例3:执行JavaScript语句,模拟滚动条滚动到底部
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
driver = webdriver.PhantomJS()
driver.get("https://movie.douban.com/typerank?type_name=剧情&type=11&interval_id=100:90&action=")
# 向下滚动10000像素
js = "document.body.scrollTop=10000"
#js="var q=document.documentElement.scrollTop=10000"
time.sleep(3)
#查看页面快照
driver.save_screenshot("douban.png")
# 执行JS语句
driver.execute_script(js)
time.sleep(10)
#查看页面快照
driver.save_screenshot("newdouban.png")
driver.quit()
示例4:模拟登录kmust教务管理系统
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 导入这个包,才能操作键盘
driver = webdriver.PhantomJS("F:/Various plug-ins/phantomjs-2.1.1-windows/bin/phantomjs.exe") # 实例化浏览器对象
driver.get("http://kmustjwcxk1.kmust.edu.cn/jwweb/") # 发送get请求,访问昆工校园网
driver.find_element_by_id('m14').click() # 点击用户登录按钮,我们的校园网是采用的iframe加载的
driver.switch_to.frame("frmHomeShow") # 所以我们要采用driver.switch_to.frame("iframe标签名")方法,进到iframe里面
with open("kmust.html", "wb") as file: # 保存一下,iframe里面的HTML
file.write(driver.page_source.encode("utf-8"))
driver.find_element_by_id('txt_asmcdefsddsd').send_keys('xxx') # 找到学号标签,添加数据
driver.find_element_by_id('txt_pewerwedsdfsdff').send_keys('xxx') # 找到密码标签,添加数据
driver.find_element_by_id('txt_sdertfgsadscxcadsads').click() # 我们学校的验证码需要点一下验证码的input框才可以显示出来
driver.save_screenshot("kmust.png") # 保存当前界面的截屏
captcha = raw_input('请输入验证码:') # 打开截屏文件,这里需要手动输入
driver.find_element_by_id('txt_sdertfgsadscxcadsads').send_keys(captcha) # 找到验证码标签,添加数据
driver.find_element_by_id("txt_sdertfgsadscxcadsads").send_keys(Keys.RETURN) # 模拟键盘的Enter键
time.sleep(1) # 网速太慢,让他加载一会
driver.save_screenshot("kmust_ok.png") # 保存一下登录成功的截图
driver.switch_to.frame("banner") # 我们的教务网站是由下面4个iframe组成的
# driver.switch_to.frame("menu")
# driver.switch_to.frame("frmMain")
# driver.switch_to.frame("frmFoot")
with open("kmust-ok.html", "ab") as file: # 所以我们要进入每个iframe,执行相应的操作(我不多说了,抢课脚本...)
file.write(driver.page_source.encode("utf-8")) # 保存下当前iframe页面的HTML数据


一个CPU一次只能执行一个进程,其他进程处于非运行状态
进程里面包含的执行单位叫线程,一个进程包含多个线程
一个进程里面的内存空间是共享的,里面的线程都可以使用这个内存空间
一个线程在使用这个共享空间时,其他线程必须等他结束(通过加锁实现)
锁的作用:防止多个线程同时用这块共享的内存空间,先使用的线程会上一把锁,其他线程想要用的话就要等他用完才可以进去
python中的锁(GIL)
python的多线程很鸡肋,所以scrapy框架用的是协程
python多进程适用于:大量密集的并行计算python多线程适用于:大量密集的I/O操作
