结对第2次作业——WordCount进阶需求
结对同学博客链接:https://www.cnblogs.com/lgyou/p/9745189.html
作业链接:https://edu.cnblogs.com/campus/fzu/FZUSoftwareEngineering1816W/homework/2160
Github项目地址:https://github.com/wyz0918/PairProject-Java
具体分工#
- 队友负责爬虫以及附加题的代码实现和相关撰写。
- 我负责词频统计的代码实现和相关撰写。
PSP表格#
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| • Estimate | • 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 890 | 850 |
| • Analysis | • 需求分析 (包括学习新技术) | 200 | 150 |
| • Design Spec | • 生成设计文档 | 30 | 25 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| • Design | • 具体设计 | 30 | 20 |
| • Coding | • 具体编码 | 300 | 360 |
| • Code Review | • 代码复审 | 10 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 300 | 240 |
| Reporting | 报告 | 110 | 90 |
| • Test Repor | • 测试报告 | 60 | 40 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1015 | 955 |
解题思路描述与设计实现说明#
爬虫使用##
- 用C++实现论文信息的爬取。
主要思路:首先便是通过获取CVPR2018官网的内容,对网页内容进行分析,发现里面有关论文介绍的网页文件存储在服务器主机的/content_cvpr_2018/html/目录下,所以对应论文网页URL中的文件路径均以此开头以.html结尾。从网页上提取相关URL存入队列就可以得到每编论文介绍网页的URl。最后遍历队列去浏览每个URL,从URL中获取的网页内容里会有title和abstract的内容,从网页内容中匹配相关信息保存到文件result.txt中即可。以上内容涉及编程的实现过程中用到了WinSock编程、sscanf字符串匹配的使用、文件的操作知识。
代码组织与内部实现设计##
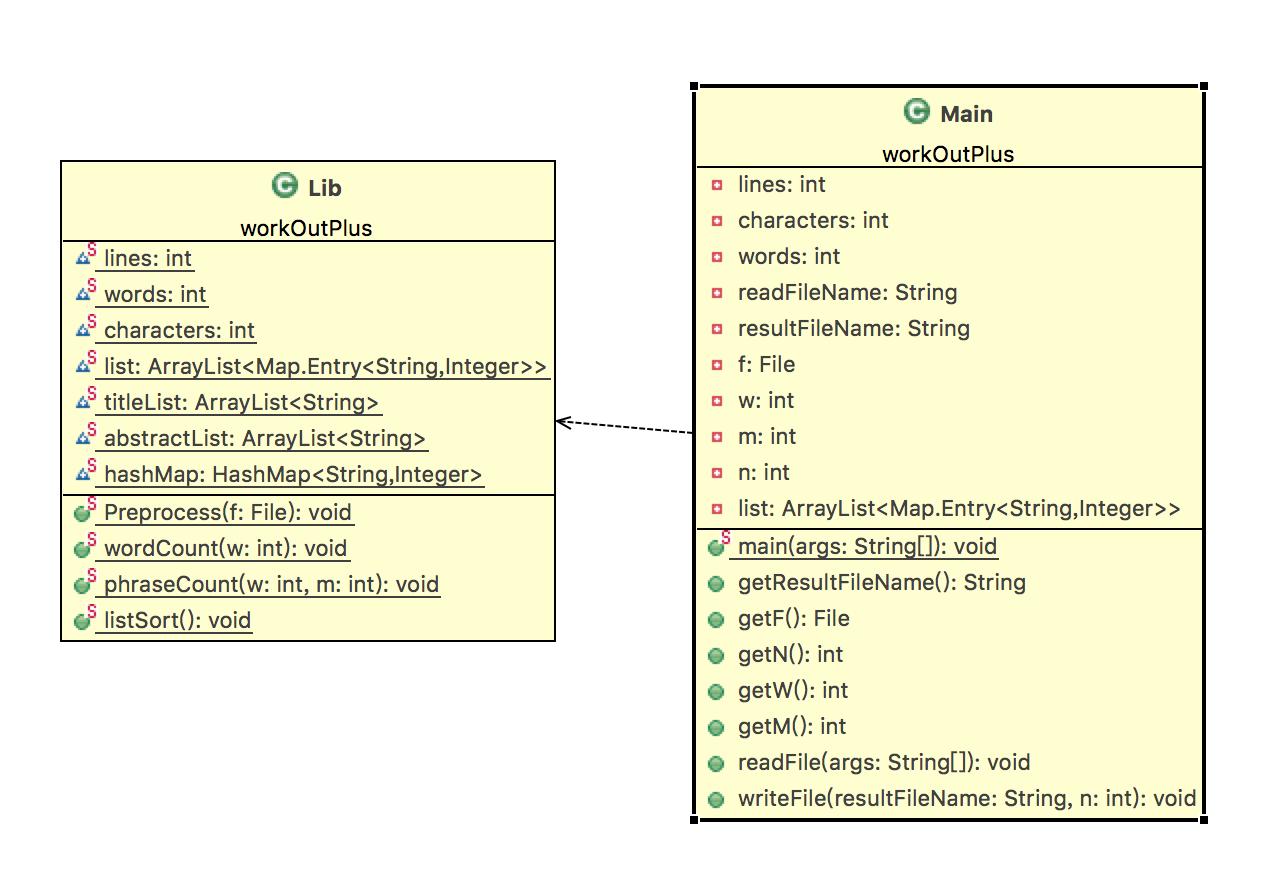
一、相关类设计
- 一个Main类,用于处理文件输入输出,Main类对象直接调用Lib类中的方法。
- 一个Lib类作为工具类,用于计算字符数、行数、单词总数、单词频率、词组频率等静态方法。
二、相关函数设计
-
1、Main类中的方法
- readFile方法实现从控制端口读入文件名,获得相关命令行参数。
- writeFile方法实现把信息按照指定格式写入指定文件。
-
2、Lib类中的方法
- Preprocess方法实现预处理,计算出行数以及字符数,将Title和Abstract中的单词分开存放。
- wordCount方法实现单词词频相关计算,包括Title和Abstract中的单词。
- phraseCount方法实现词组词频相关计算,包括Title和Abstract中的词组。
- listSort()方法实现hashMap中的单词/词组排序
三、类图
算法的关键与关键实现部分流程图##
-
算法的关键
我认为算法的关键在于实现词组词频统计。在上一个workOut版本中,已经实现了基础的功能,只需要稍微调整即可用于当前版本。而除了排序可以重用外,词频统计功能应该算得上是一个全新的功能,不仅需要考虑词组的格式,也需要检索出所有词组。 -
流程图

附加题设计与展示#
-
设计的创意独到之处
通过爬取论文信息,提取出标题、作者和摘要。可以统计出每位作者发表的论文数量,对每个作者发表论文数进行排序,可以得出前50位发表论文数量最多的作者。在这50位作者中,通过爬取到的数据进行分析,可以查看到这50位论文发表数量最多的作者之间的合作关系。通过最后产生的一个合作关系图谱,如果合作关系密切,说明多次合作经验和可以成功发表论文是有关系的,也就是说合作经验越足,他们的论文往往会被成功发表。而如果合作关系稀疏,也就是说和不同的人合作,涉及广泛,那么也就有更多新鲜的合作经历,新颖点也会越多,这样的论文发表的成功性更大。 -
实现思路
首选便是对网页论文提取不仅仅涉及标头、摘要,还有作者,只要根据对应的关键字进行匹配,就可以提取到相关信息。在提取生成的result.txt文件里,通过遍历文件,将作者名字作为key,Authors行中其出现的次数作为values值加入Treemap中,最后将Treemap根据values排序,可以得到一个作者论文发表数量降序排序的Treemap。之后保留其中前50位作者,将剩余作者移出Treemap。之后在一个继承Jpanel的类中再次遍历文件,查看作者是不是在之前的Treemap中,如果是就绘制一个点表示该作者,同时会出其名字和发表论文数。再查看其同编论文的合作伙伴是否也在Treemap中,如果是则也绘制一个点,并与之前的作者之间绘一条线,表示两人有合作关系,这样如果一个点引出的线越多,其与别人合作越多,最后就绘出了整个发表论文数量前50名作者之间的合作关系。 -
实现成果展示
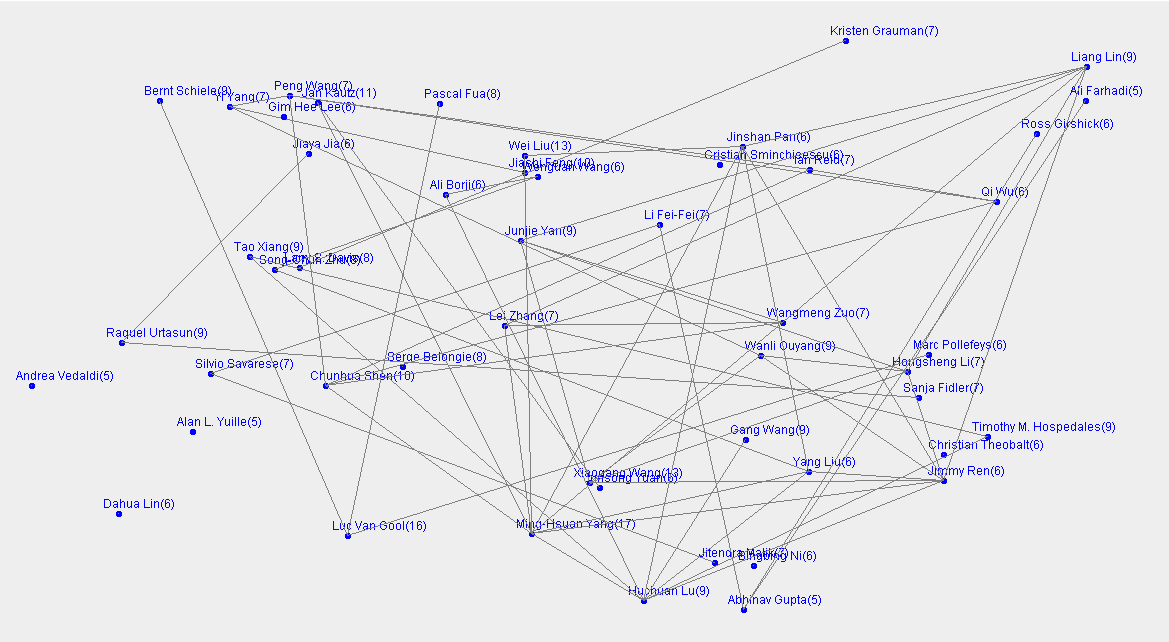
-
从图中可以看出合作关系还是挺紧密的,并且这50位作者中都有多次合作的关系。也就是说合作次数越多,那么合作经验则相对丰富,效率和成功作品的可能性都会有所提高,当然这不可一概而论。
相关执行程序附件
关键代码解释#
- 词频统计代码:
词频统计中Title部分代码
//处理Title
for (int p = 0; p < titleList.size(); p++) {
tmp = 0;
count = 0;
wordArray = titleList.get(p).split("\\s*[^a-zA-Z0-9]+");
sepArray = titleList.get(p).split("[a-zA-Z0-9]+");
// 若以分隔符开头 合并时以第二个分隔符开始
if (titleList.get(p).matches("\\s*[^a-zA-Z0-9]+[\\s\\S]*")) {
tmp = 1;
}
for (int i = 0; i < wordArray.length; i++) {
if (wordArray[i].matches("[a-zA-Z]{4,}[a-zA-Z0-9]*")) {
Lib.words++;
count++;
} else {
if (count >= m) {
int tmpCount = count - m + 1;
for (int j = 0; j < tmpCount; j++) {
sb.delete(0, sb.length());
sb.append(wordArray[i - count + j]);
for (int k = 1, l = i - count + 1 + j; k < m; k++, l++) {
sb.append(sepArray[l - tmp]).append(wordArray[l]);
}
String phrase = sb.toString().toLowerCase();
if (hashMap.containsKey(phrase)) {
hashMap.put(phrase, hashMap.get(phrase) + incre);
} else {
hashMap.put(phrase, incre);
}
}
}
count = 0;
}
}
if (count >= m) {
int tmpCount = count - m + 1;
wALength = wordArray.length;
for (int j = 0; j < tmpCount; j++) {
sb.delete(0, sb.length());
sb.append(wordArray[wALength - count + j]);
for (int k = 1, l = wALength - count + 1 + j; k < m; k++, l++) {
sb.append(sepArray[l - tmp]).append(wordArray[l]);
}
String phrase = sb.toString().toLowerCase();
if (hashMap.containsKey(phrase)) {
hashMap.put(phrase, hashMap.get(phrase) + incre);
} else {
hashMap.put(phrase, incre);
}
}
}
}
- 代码解释:
在词组词频计算中,词组由单词以及分隔符共同构成,因此我采用分开单词和分隔符,最后再组合在一起的方法。分开单词的分隔符采用String.spilt()方法,组合采用StringBuffer.append()方法,因为有设定统计的词组长度m的存在,因此用count变量计数,当遇到不符合要求的单词或到达结尾,count清零,并同时开始检索符合要求的词组,加入hashMap中,其中需要注意的是合并单词与分隔符时由于位置关系需要注意考虑两种情况.
性能分析与改进#
JProfiler性能分析图:
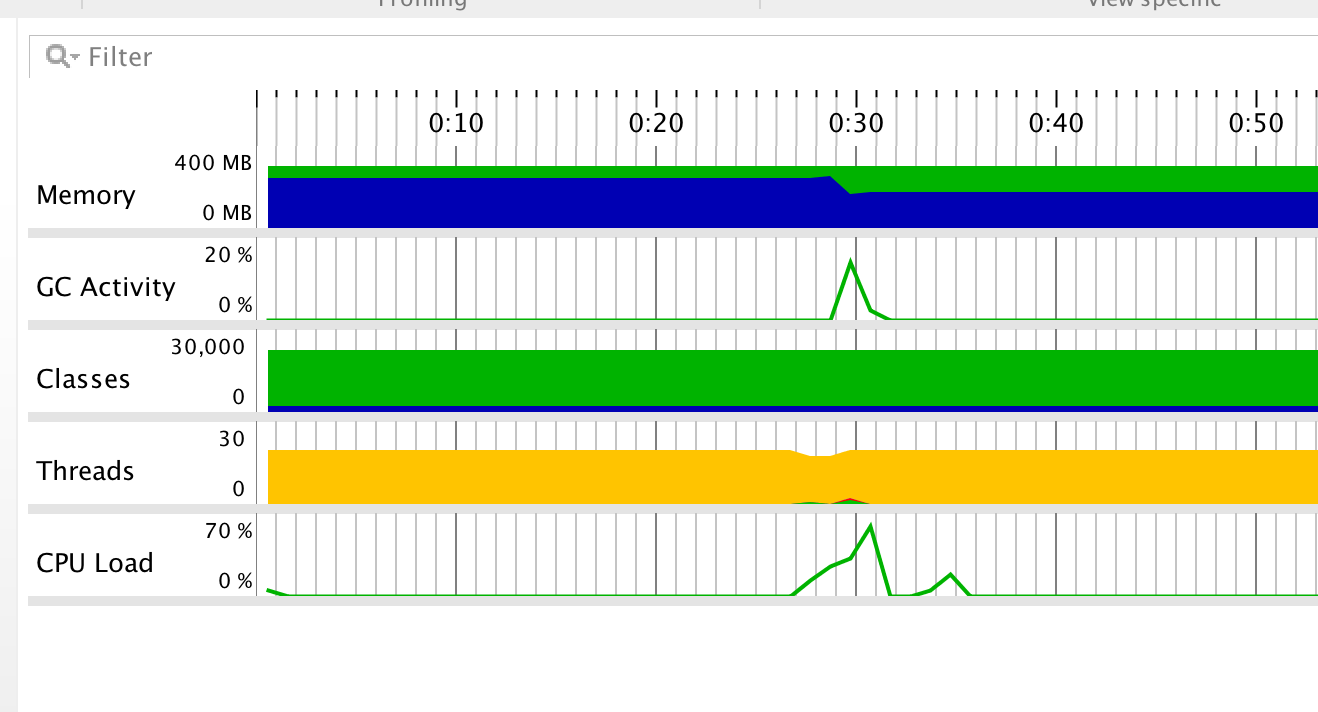

由图可知,程序中开销最大的函数是词频统计中的HashMap。
改进的思路:
- 用StringBuffer.append()代替String的“+”进行循环添加操作,这样可以避免多次创建String对象,提高性能。
- 尽量在一次br.readline中完成所有操作,避免多次读取造成时间成本增加。
单元测试#
预处理统计字符数Preprocess()的测试函数:##
@Test
public void testPreprocess() {
File f = new File("input.txt");
Lib.Preprocess(f);
assertEquals(Lib.characters,74);
assertEquals(Lib.titleList.get(0),"Monday Tuesday Wednesday Thursday");
assertEquals(Lib.abstractList.get(0),"Monday Tuesday Wednesday Thursday Friday");
}

- 构造测试数据的思路:
将input.txt作为参数输入,对照字符数以及存放Title和Abstract的数组是否符合预期的结果。
词组词频统计PhraseCount()的测试函数:##
测试一:
@Test
public void testPhraseCount() {
Lib.titleList.add("monday tuesday {thursday");
Lib.abstractList.add("tuesdaa,wednesday thursday");
Lib.abstractList.add("tuesdaa,wednesday thursday");
Lib.abstractList.add("tuesday wednesday thursday");
Lib.abstractList.add("tuesday wednesday thursday");
String[] str = {"monday tuesday {thursday","tuesdaa,wednesday thursday","tuesday wednesday thursday"};
String[] str2 = {"10","2","2"};
ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>();
Lib.phraseCount(1, 3);
Lib.listSort();
list = Lib.list;
for (int i = 0; i < 10 && i < list.size(); i++) {
assertEquals(list.get(i).getKey(),str[i]);
}
for (int i = 0; i < 10 && i < list.size(); i++) {
assertEquals(list.get(i).getValue().toString(),str2[i]);
}
}
}
测试二:
@Test
public void testPhraseCount2() {
Lib.titleList.add("monday tuesday {thursday");
Lib.abstractList.add("\"tuesdaa\",wednesday thursday");
Lib.abstractList.add("tuesdaa,wednesday thursday");
Lib.abstractList.add("tuesdaa,wednesday thursday.");
String[] str = {"monday tuesday {thursday","tuesdaa,wednesday thursday","tuesdaa\",wednesday thursday"};
String[] str2 = {"10","2","1"};
ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>();
Lib.phraseCount(1, 3);
Lib.listSort();
list = Lib.list;
for (int i = 0; i < 10 && i < list.size(); i++) {
assertEquals(list.get(i).getKey(),str[i]);
}
for (int i = 0; i < 10 && i < list.size(); i++) {
assertEquals(list.get(i).getValue().toString(),str2[i]);
}
}
}
- 构造测试数据的思路:
将w=1、m=3作为参数输入,对照List中存储的值看是否符合预期的结果,为了更加全面地测试,我检测了多种分隔符的情况 。
其他函数因为之前的作业有测试过不再写出。
Github的代码签入记录#
遇到的代码模块异常或结对困难及解决方法#
-
问题描述
在进行代码测试时,发现词组词频统计模块无法正常输出,里面的逻辑较为复杂。 -
做过哪些尝试?
首先一步步排查,利用输出函数输出每一步运行的结果与预期进行比对,找到错误的地方后再进一步审查是逻辑错误还是API使用错误。 -
是否解决?
解决了问题,成功输出了结果,提高了代码的质量。 -
有何收获?
对java API等有了更深的理解,并且在错误排查方面也更加有了经验。
评价你的队友#
-
值得学习的地方
队友雷光游非常的可靠,他能非常及时地和我讨论分工以及计划,并且在我有疑惑时可以为我解答。他完成任务的效率和准确性都非常高,因此我们可以提前完成任务。他还具有很强的责任心,他这次负责的爬虫以及附加题的设计完成的都很优秀。这些都是我应该学习的地方。 -
需要改进的地方
感觉已经非常优秀了,如果要说的话,可能就是沟通较少。
学习进度条#
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 50 | 50 | 4 | 4 | 熟悉了github的基本操作以及运用markdown撰写博客 |
| 2 | 364 | 414 | 11.8 | 15.8 | 提升了java编程能力,熟悉了一个项目的实现过程 |
| 3 | 0 | 0 | 15 | 30.8 | 学习了构建之法中模型设计的ABCD、学习了墨刀原型的设计 |
| 4 | 508 | 922 | 15.9 | 46.7 | 提升了java编程能力,对接口封装以及网络编程有了更深的理解 |

