
python函数进阶
知识内容:
1.函数即变量
2.嵌套函数
3.lambda表达式与匿名函数
4.递归函数
5.函数式编程简介
6.高阶函数与闭包
一、函数即变量
1.变量的本质
声明一个变量,在python里本质上讲是把变量对应的值和变量名联系起来,变量里保存的不是值,而是值对应的地址;而赋值时从本质上讲是把变量名对应的值的内存地址赋给了另一个变量
1 a = 1 2 b = a
可以这样理解,变量名相对于酒店里的房牌号,而变量名对应的值就相对于对应的房间
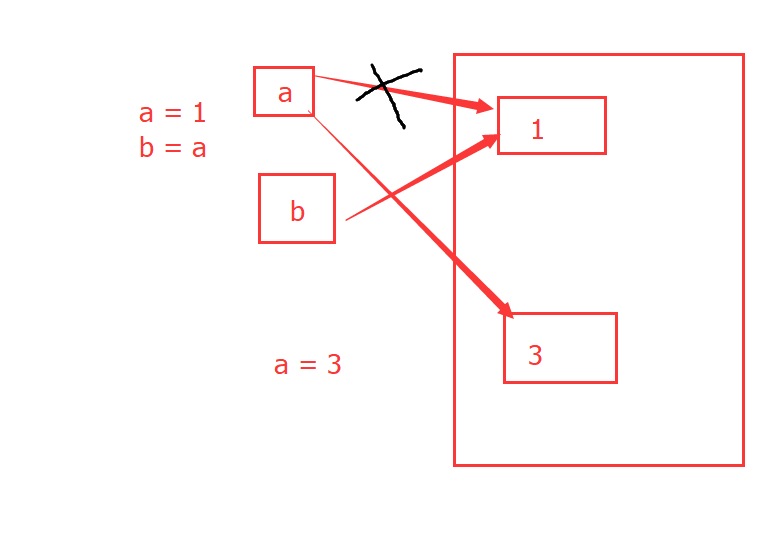
在上图中,刚开始a和b都是指向1对应的内存位置,后来把赋值a为3,赋值其实就算改变了变量名与内存位置的对应关系,也就是赋值后a这个变量名对应的值为3而b这个变量名依然对应的值为1
python是基于值的内存管理体系,当1对应的变量没有了,也就是上面的a和b都赋值为其他值时,系统便会自动清除掉1的内存
2.def的本质
def的本质就是将函数名和函数体联系在一起,放入内存中,也就是函数名相当于上面的变量名,函数体相当于上面的值,定义一个函数就相当于将值赋给变量,也就是将函数体赋给了函数名,因此才可以通过函数名来执行函数体
3.几段代码及其解释
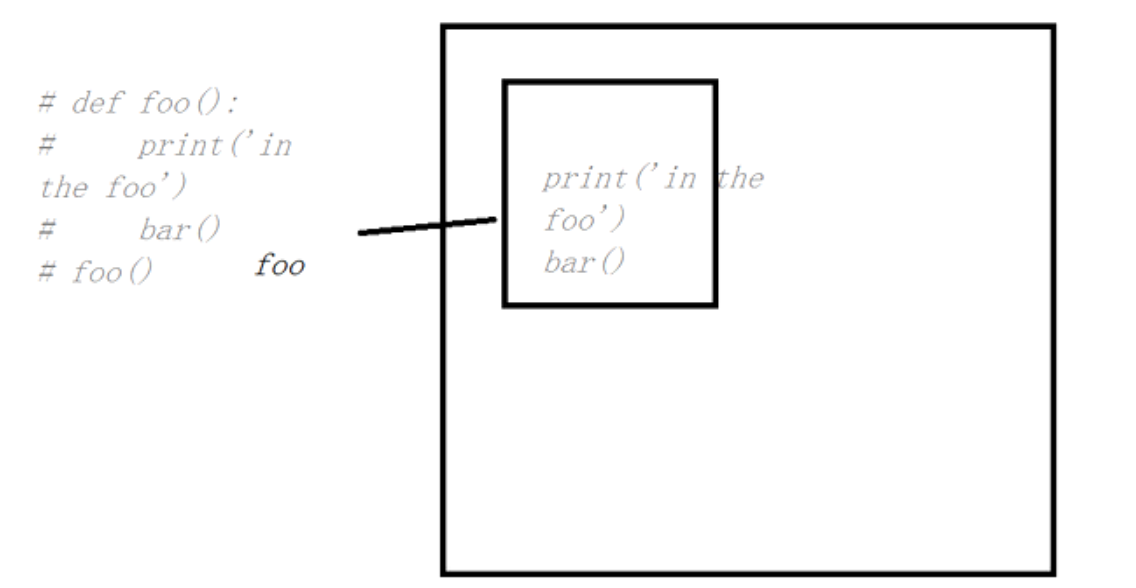
1 # (1) 2 # def foo(): 3 # print("in the fool") 4 # bar() 5 # foo() 6 # 运行结果: 输出in the fool然后报错
解释: 定义foo之后函数解释时将foo与函数体相关联,解释到foo(),函数执行函数名foo对应的函数体函数名foo对应的函数体在内存可以找到,于是执行该函数体,但是执行到bar时解释器麻痹了,找不到函数名bar对应的函数体,于是就报错了,如下图所示:
1 # (2) 2 # def bar(): 3 # print("in the bar") 4 # def foo(): 5 # print("in the fool") 6 # bar() 7 # foo() 8 # 输出结果: 9 # # in the fool 10 # # in the bar 11 12 # (3) 13 # def foo(): 14 # print("in the fool") 15 # bar() 16 # def bar(): 17 # print("in the bar") 18 # foo() 19 # # 输出结果: 20 # # in the fool 21 # # in the bar
解释:
(2)和(3)的输出结果一样,但是从解释的流程来讲并不是一样的,但是与下一段代码有异曲同工之妙
1 x = 1 2 y = 2 3 print(x, y) 4 5 y = 2 6 x = 1 7 print(x, y) 8 9 # 输出结果都是: 1 2
x和y虽然定义的顺序不一样,当两者都是把变量名与对应变量联系起来,所以只要输出顺序一样自然结果就一定一样同样的道理,函数foo和函数bar虽然定义的顺序不一样,但他们的定义的本质与变量是一样的,是将函数名与函数体联系起来,所以只要调用函数的顺序一样自然它们输出的结果也一样,至于它们的具体解释流程可以参见第一段代码的解释,两者的流程是类似的
二、嵌套函数
1.嵌套函数
python中的函数还可以嵌套定义,即一个函数的定义里还有另一个函数的定义,如下:
1 # __author__ = "wyb" 2 # date: 2018/3/21 3 # 函数嵌套 4 5 name = "zzz" 6 7 8 def f1(): 9 name = "wyb" 10 11 def f2(): 12 name = "wyb666" 13 print("第一层打印: ", name) 14 15 f2() 16 print("第二层打印: ", name) 17 18 19 f1() 20 print("最外层打印: ", name) 21 22 # 输出结果: 23 # 第一层打印: wyb666 24 # 第二层打印: wyb 25 # 最外层打印: zzz
注: 函数嵌套是在函数体内还有一个函数体,而不是在函数体内调用另一个函数
2.前向引用
函数func体内嵌套某一函数logger的调用,则logger函数的声明定义必须在func函数之前,否则程序会报错!
1 # 前向引用 2 def logger(): 3 print("in the logger") 4 5 def func(): 6 print("in the func") 7 logger() 8 9 func() 10 11 # 输出结果: 12 # in the func 13 # in the logger
3.嵌套函数的定义域
在嵌套函数中要格外注意局部作用域和全局作用域的访问顺序
1 x = 0 2 def grandpa(): 3 x = 1 4 def dad(): 5 x = 2 6 def son(): 7 x = 3 8 print(x) 9 son() 10 dad() 11 grandpa()
注: son()和dad()和grandpa()这几个函数调用少了任何一个程序都将不会执行
三、lambda表达式与匿名函数
1.匿名函数
python使用 lambda 来创建匿名函数,所谓匿名是指不再使用 def 语句这样标准的形式定义一个函数,lambda的特点:
- python中的匿名函数也叫lambda表达式,lambda只是一个表达式,比def定义的函数简单很多
- 匿名函数的核心:一些简单的需要用函数去解决的问题,匿名函数的函数体只有一行并且参数可以有多个,用逗号隔开
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去
- 返回值和正常的函数一样可以是任意的数据类型
- 匿名函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
2.匿名函数示例
1 >>> f = lambda x, y, z: x+y+z 2 >>> print(f(1,2,3)) 3 6 4 >>> g = lambda x, y=2, z=3: x+y+z # 含有默认值参数 5 >>> print(g(1)) 6 6 7 >>> print(g(2, z=5, y=6)) # 调用时使用位置参数 8 13 9 >>> list(map(lambda x: x+10, [1,2,3,4,5])) # 包含函数调用没有名字的lambda表达式 10 [11, 12, 13, 14, 15]
四、递归函数
递归的详细讲解:http://www.cnblogs.com/alex3714/articles/8955091.html
1.递归的定义
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数,所谓递归就是在函数内部调用自身
1 def proc(n): 2 if n < 0: 3 print('-', end = '') 4 n = -n 5 if n // 10: 6 proc(n // 10 ) 7 print(n % 10, end = '') 8 9 proc(-345) 10 # 输出: -345
2.递归特性:
(1)必须有一个明确的结束条件
(2)每次进入更深一层递归时,问题规模相比上次递归都应有所减少
(3)递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
3.递归的要领
(1)找相似性 -> 寻找问题在不同大小规模下的相似性,抽象出共同特征,根据共同特征写出递归的核心方程式或者递推公式
(2)找出口 -> 问题不可能一直递归下去,总要有一个出口,结束递归从而结束循环
4.经典递归算法的python实现


1 # __author__ = "wyb" 2 # date: 2018/3/30 3 # Fibonacci数列递归求解 4 5 6 # # 普通写法: 7 # def fib(n): 8 # if n == 0 or n == 1: 9 # return n 10 # a, b = 0, 1 11 # count = 0 12 # while count < n: 13 # a, b = b, a+b 14 # count = count + 1 15 # return a 16 17 18 # 递归写法: 19 def fib(n): 20 if n == 0 or n == 1: 21 return n 22 else: 23 return fib(n-1)+fib(n-2) 24 25 26 print(fib(0)) 27 print(fib(1)) 28 print(fib(2)) 29 print(fib(3)) 30 print(fib(4)) 31 print(fib(5))
1 # __author__ = "wyb" 2 # date: 2018/3/30 3 # 汉诺塔问题 4 5 6 def hanoi(a, b, c, n): 7 if n == 1: 8 print(a, "->", c) 9 else: 10 hanoi(a, c, b, n-1) 11 print(a, "->", c) 12 hanoi(b, a, c, n-1) 13 14 15 hanoi('a', 'b', 'c', 4)
五、函数式编程简介
1.引言
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元,在编程中函数是指逻辑结构化和过程化的一种编程方法。在过去的10年间,大家所熟悉的编程方式不是面向对象就是面向过程,两种都是编程的规范或如何编程的方法论。而如今,一种更为古老的编程方式--函数式编程,以其不保存状态、不修改变量等特性重出江湖,重新进入人们的思想中
面向对象 --> 类 --> class
面向过程 --> 过程 --> def
函数式编程 --> 函数 --> def
1 # __author__ = "wyb" 2 # date: 2018/3/27 3 4 5 # 函数 6 def func1(): 7 """testing1""" 8 print("in the func1") 9 return 0 10 11 12 # 过程 -> 没有返回值的函数 13 def func2(): 14 """testing2""" 15 print("int the func2") 16 17 18 x = func1() 19 y = func2() 20 print(x, y) 21 """ 22 输出结果: 23 in the func1 24 int the func2 25 0 None 26 """
2.函数式编程定义
简单说,"函数式编程"是一种编程范式(programming paradigm),也就是如何编写程序的方法论。
函数式编程中的函数这个术语不是指计算机中的函数,而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
3.经典的函数式编程语言
LISP: 长期以来垄断人工智能领域的应用,是为人工智能而设计的语言
Haskell: 是一种标准化的、通用纯函数式编程语言,有非限定性语义和强静态类型
Erlang: 是一种通用的面向并发的编程语言,它支持并发与函数式编程
4.函数式编程的特性
- 闭包和高阶函数
- 惰性计算
- 递归
- 函数是"第一等公民"
- 只用"表达式",不用"语句"
- 没有"副作用"
5.函数式编程的优点
- 代码简洁,开发快速
- 接近自然语言,易于理解
- 更方便的代码管理
- 易于"并发编程"
六、高阶函数与闭包
1.高阶函数定义
变量可以指向函数,函数的参数能接收变量,当然一个函数就可以接收另一个函数作为参数或者返回值中包含函数名,这种函数就称之为高阶函数。
2.高阶函数的要求
满足以下两个条件之一的函数可称为高阶函数:
(1)把一个函数名作为实参传给另一个函数 -> 可以在不修改函数源代码的情况下为函数添加功能
(2)返回值中包含函数名 -> 不修改函数的调用方式
3.高阶函数示例
(1)符合第一个标准的高阶函数
1 def bar(): 2 print("in the bar") 3 4 def test1(func): 5 print(func) # 函数名->地址 6 func() # run bar 7 8 test1(bar) 9 # # 输出结果: 10 # <function bar at 0x053E85D0> 11 # in the bar
(2)符合第二个标准的高阶函数
1 def bar(): 2 print("in the bar") 3 4 def test2(func): 5 print(func) 6 return func 7 8 t = test2(bar) 9 print(t) 10 t() # run bar 11 12 # # 输出结果: 13 # <function bar at 0x05938618> 14 # <function bar at 0x05938618> 15 # in the bar
4.闭包
(1)概念
闭包就是能够读取其他函数内部变量的函数。例如在javascript、python中,只有函数内部的子函数才能读取局部变量,所以闭包可以理解成“定义在一个函数内部的函数“。在本质上,闭包是将函数内部和函数外部连接起来的桥梁
简单说: 如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数,那么闭包就是在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的函数名(引用)。这样就构成了一个闭包
(2)理解
概念看起来不是很容易理解,我直接举实例解释上述概念
1 def func(): 2 n = 10 3 4 def func2(): 5 print("func2: ", n) 6 return func2 7 8 9 f = func() 10 print(f) 11 f() 12 # 输出结果: 13 # <function func.<locals>.func2 at 0x049294F8> 14 # func2: 10
上述代码中的func返回的是func2函数的内存地址,调用func返回func2的内存地址然后调用执行会打印n的值,按照局部变量在函数运行完后就释放不再存在的原则似乎这里有点问题,但是这其实就算闭包。原来调用func2只能在func中进行调用,但是现在有了闭包后只需返回fanc2的地址然后可以在func函数外调用,就相当于在func外面拿到了func2函数,如果此时func2调用了func中的变量比如n,此时n是不会释放内存的
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号