
python文件操作与字符编码
知识内容:
1.文件对象与文件处理流程
2.基本操作
3.上下文管理
4.文件的修改与文件内光标的移动
5.字符编码
一、文件对象与文件处理流程
1.文件对象
(1)文件分类
按文件中数据的组织形式可以把文件分为文本文件和二进制文件
文本文件中存储的是常规字符串,由若干文本行组成,通常每行以换行符('\n')结尾
二进制文件把对象内容以字节串(bytes)进行存储,无法用记事本及其他普通文本处理软件打开,也无法直接被人阅读理解,需要使用专门的软件进行解码才能读取其中的内容
(2)文件对象: python中内置了文件对象,通过open函数可以打开一个文件并创建一个文件对象,通过对这个文件对象的一系列操作来修改、读、写文件
eg: 文件对象名 = open(文件名[, 打开方式[,缓冲区]])
f1 = open('file.txt', 'r')
(3)文件打开方式(文件打开模式):
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
(4)文件对象常用的方法:
flush() -> 把缓冲区的内容写入文件,当不关闭文件
close() -> 把缓冲区的内容写入文件,同时关闭文件,并释放文件对象
read([size]) -> 从文件中读取size个字节(python2)或字符(python3)的内容作为结果返回,如果省略size则一次性读取所有内容
readline() -> 从文本文件中读取一行内容作为结果返回
readlines() -> 把文本文件中的每一行作为一个字符串存入列表中返回该列表
tell() -> 返回文件指针的位置
seek(offset[,where]) -> 移动文件指针
truncate([size]) -> 删除从当前指针位置到文件末尾的内容,如果指定了size则不论指针在哪只留下前size个字符其余的删除
write(s) -> 把字符串s的内容写入文件
writelines(s) -> 把字符串列表写入文本文件,不添加换行符
2.文件处理流程
(1)打开文件,得到文件句柄(文件对象)并赋值给一个变量
(2)通过句柄(文件对象)对文件进行操作
(3)关闭文件
1 # 打开文件: 2 f = open('yesterday2.txt', 'a', encoding='utf-8') # 文件句柄 3 4 # 操作文件(读): 5 data = f.read() 6 7 # 输出读的结果: 8 print('--read: \n', data) 9 10 # 关闭文件 11 f.close()
二、基本操作
1.向文件写入内容
- write(s) -> 把字符串s的内容写入文件
- writelines(s) -> 把字符串列表写入文本文件,不添加换行符
注: w模式创建一个新文件, 不可读;不存在则创建;存在则清空内容。所有若文件已存在且只是想向里面添加内容建议
使用a模式(追加模式: 不存在则创建;存在则只追加内容)
1 # w: 创建一个新文件, 不可读;不存在则创建;存在则清空内容 2 f = open('fool.txt', 'w', encoding='utf-8') 3 f.write("这是写入的内容\n") 4 f.write("1234567890") 5 6 f.close()
1 # a: 追加模式: 不存在则创建,存在则只追加内容 2 f = open('fool.txt', 'a', encoding='utf-8') 3 f.write("这是写入的内容\n") 4 f.write("1234567890") 5 6 f.close()
2.从文件中读取内容
- read([size]) -> 从文件中读取size个字节(python2)或字符(python3)的内容作为结果返回,如果省略size则一次性读取所有内容
- readline() -> 从文本文件中读取一行内容作为结果返回
- readlines() -> 把文本文件中的每一行作为一个字符串存入列表中返回该列表
1 # 打开一个文件 2 f = open("foo.txt", "r", encoding='utf-8') 3 s1 = f.read(10) # 读取10个字符 4 5 print("s1: ", s1) 6 7 # 关闭打开的文件 8 fo.close()
1 # 打开一个文件 2 f = open("foo.txt", "r", encoding='utf-8') 3 s2 = f.readline() # 读取一行返回字符串 4 5 print("s2: ", s1) 6 7 # 关闭打开的文件 8 fo.close()
1 # 打开一个文件 2 f = open("foo.txt", "r", encoding='utf-8') 3 s3 = f.readlines() # 读取所有的行返回字符串列表 4 5 print("s3: ", s1) 6 7 # 关闭打开的文件 8 fo.close()
注: encoding = "utf-8"申明文件编码集,文件编码是什么就用什么编码声明,一般不声明时默认使用utf-8,而用二进制模式打开文件时不需要声明文件编码集
3.读写文件
文件打开模式中"+" 表示可以同时读写某个文件:
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
(1)读写模式:
1 f = open("1.txt", "r+", encoding="utf-8") 2 3 data = f.read() 4 print(data) 5 6 f.write("写入的内容\n") 7 8 f.close()
注: 读写模式 r+打开文件会保持原文件内容不变,同样可以同时对文件进行读写
(2)写读模式: -> 基本没什么卵用
1 f = open("1.txt", "w+", encoding="utf-8") 2 3 data = f.read() 4 print(data) 5 6 f.write("写入的内容1\n") 7 f.write("写入的内容2\n") 8 f.write("写入的内容3\n") 9 f.write("写入的内容4\n") 10 11 print("after write: ", f.read()) 12 f.close()
注: 写读模式 w+打开文件会将原文件内容删除,可以同时对文件进行读写
4.读写二进制文件
1 # 读二进制文件 2 f = open('yesterday.txt', 'rb') 3 4 print(f.readline()) 5 print(f.readline()) 6 print(f.readline()) 7 8 f.close() 9 10 # 写二进制文件(添加) 11 f = open('yesterday.txt', 'a') 12 13 f.write('\n666') 14 15 f.close()
注: b表示以字节的方式读取或写入,这里指的是编码,而不是指文件中的内容变成了二进制(010101)!
5.循环遍历文件
1 f = open('fool.txt', 'r', encoding='utf-8') 2 count = 0 3 4 for line in f: 5 print(count, line.strip()) 6 count += 1 7 8 f.close()
6.文件的追加
文件操作时以a或ab模式打开,则只能追加,即在源文件的尾部追加内容
1 f = open("1.txt", "a", encoding="utf-8") 2 3 f.write("追加的内容\n") 4 5 f.close()
三、上下文管理
上下文管理详细解释见 https://blog.csdn.net/immortal_codeFarmer/article/details/76796868
可以使用with打开文件,这时就不用自己关闭文件,因为上下文管理器会自动帮我们关闭打开的文件,可以打开一个也可以打开多个,如下所示:
1 with open('a.txt','w') as f: 2 3 pass 4 5 with open('a.txt','r') as read_f, open('b.txt','w') as write_f: 6 7 data=read_f.read() 8 9 write_f.write(data)
四、文件的修改与文件内光标的移动
1.文件的修改
注: 在源文件里修改会覆盖源文件里的内容因此为了保存源文件要把修改后的行写入新的文件
1 f = open('yesterday2.txt', 'r', encoding='utf-8') 2 f_new = open('yesterday2.bak', 'w', encoding='utf-8') 3 4 for line in f: 5 if "我" in line: 6 line = line.replace("我", "我我我我") 7 f_new.write(line) 8 9 f.close() 10 f_new.close()
2.文件内光标的移动
- tell() -> 返回文件指针的位置
- seek(offset[,where]) -> 移动文件指针
1 f = open("yesterday.txt", 'r', encoding='utf-8') 2 3 print(f.tell()) # 输出: 0 4 print(f.read(50)) 5 print(f.tell()) # 输出: 50 6 7 print() 8 f.seek(0) 9 print(f.tell()) # 输出: 0 10 print(f.readline().strip()) # 输出第一行 11 12 f.close()
五、字符编码
字符编码详细解释:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.cnblogs.com/alex3714/articles/7550940.html
1.什么是编码
基本概念很简单。首先,我们从一段信息即消息说起,消息以人类可以理解、易懂的表示存在。我打算将这种表示称为“明文”,对于说英语的人,纸张上打印的或屏幕上显示的英文单词都算作明文。其次,我们需要能将明文表示的消息转成另外某种表示,我们还需要能将编码文本转回成明文。从明文到编码文本的转换称为“编码”,从编码文本又转回成明文则为“解码”
2.有哪些字符编码
字符编码: ASCII、GB2312、GBK、Unicode、UTF-8,具体解释:
(1)ASCII
记住一句话:计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。
再说简单点,计算机只懂二进制数字! 所以,目的明确了:如何将我们能识别的符号唯一的与一组二进制数字对应上?
于是美利坚的同志想到通过一个电平的高低状态来代指0或1, 八个电平做为一组就可以表示出 256种不同状态,每种状态就唯一对应一个字符,
比如A--->00010001,而英文只有26个字符,算上一些特殊字符和数字,128个状态也够 用了;每个电平称为一个比特为,约定8个比特位构成一个字节,
这样计算机就可以用127个不同字节来存储英语的文字了。这就是ASCII编码。
扩展ANSI编码: 才说了,最开始,一个字节有八位,但是最高位没用上,默认为0;后来为了计算机也可以表示拉丁文,就将最后一位也用上了,从128到255的字符集对应拉丁文啦。至此,一个字节就用满了!
(2)GB2312
计算机漂洋过海来到中国后,问题来了,计算机不认识中文,当然也没法显示中文;而且一个字节所有状态都被占满了,于是中国重写一张表,
直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,
前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了;这种
汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展
(3)GBK
GBK是将GB2312扩展之后得到的编码方案,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号
现在我们用的Windows操作系统上默认的编码就是GBK
(4)Unicode
很多其它国家都搞出自己的编码标准,彼此间却相互不支持。这就带来了很多问题。于是,国际标谁化组织为了统一编码:提出了标准编码准
则:Unicode,Unicode是用两个字节来表示为一个字符,它总共可以组合出65535不同的字符,这足以覆盖世界上所有符号(包括甲骨文)
Unicode编码的作用:
(1)用其他编码标准编码的程序可以用Unicode来解码然后就不会乱码,这是因为Unicode包含了跟全球所有国家编码的映射关系,可以支持全球所有语言
(2)Unicode作为一个中间桥梁的作用来将程序的编码转换成另一种编码
(5)utf-8
对于英文世界的人们来讲,一个字节完全够了,比如要存储A,本来00010001就可以了,unicode 得用两个字节:00000000 00010001才行,浪费太严重
基于此,美国提出:utf8,UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号
并根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。这样显著的好处是,虽然在内存中的数据
都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦!这也是为什么utf8是我们的推荐编码方式
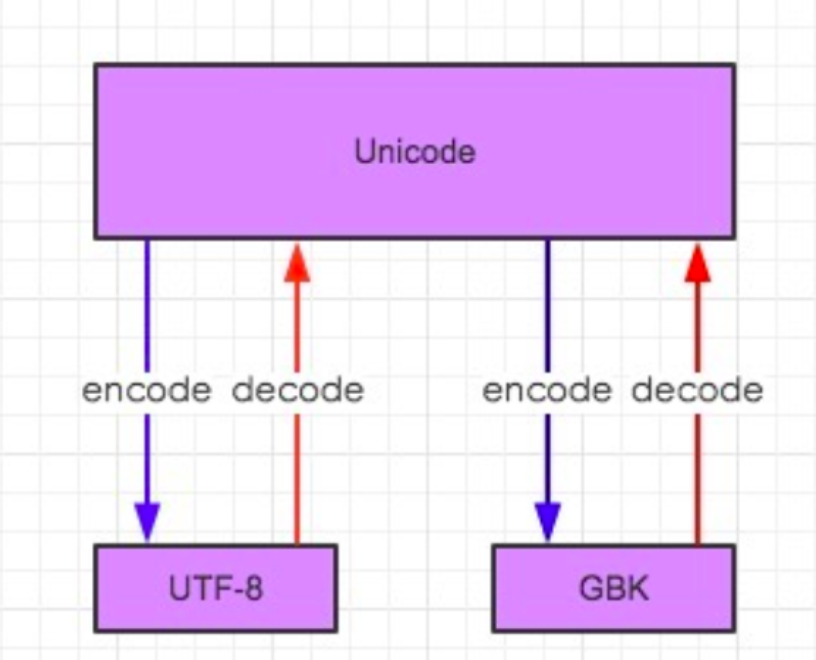
(6)Unicode和utf-8的关系
Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现),这也是UTF与Unicode的区别
(7)总结
ASCII一个字符占1个字节且只支持英文不支持中文;Unicode俗称万国码,一个字符占两个字节
UTF-8对字符和符号进行分类,是可变长编码: ASCII中的字符用1个字节存,欧洲的字符占两个字节,而东亚的字符占三个字节
GBK|GB2312是中国自己的编码,一个字符占两个字节
Windows系统中的中文默认编码是GBK;Linux\Mac系统中的编码默认是UTF-8
3.python字符编码与转码
(1)python中的编码
在python2默认编码是ASCII, python3里默认编码是unicode,因为python2的默认编码为ASCII无法支持中文,所以需在文件开头(第一行)声明使用的编码改为UTF-8,然后就可以支持中文了
1 #coding:utf8
(2)python3 执行代码的过程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
(3)编码过程
python3:
在python3上代码如果以utf-8编写, 保存,然后在windows上执行,utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode , 但是这只是python3
python2:
python2的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味意味着,你以utf-8编码的文件,在windows中还是乱码
既然Python2并不会自动的把文件编码转为unicode存在内存里, 那就只能使出最后一招了,自己转。Py3 自动把文件编码转为unicode从本质上看是调用了以下两种方法: decode(解码) 和encode(编码),具体解释见下面:
(4)解码与编码
1 UTF-8->GBK: 先用decode解码成Unicode再用encode编码成GBK 2 GBK->UTF-8: 先用decode解码成Unicode再用encode编码成UTF-8 3 4 UTF-8 --> decode 解码 --> Unicode 5 Unicode --> encode 编码 --> GBK / UTF-8 ..
decode() 方法以 encoding 指定的编码格式解码字符串。默认编码为字符串编码(python2为ASCII,python3为Unicode)
encode() 方法以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案
unicode编码的字符串可以在utf-8编码的文件中直接打印,但GBK不行,GBK需要进行转化成UTF-8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号