
爬取腾讯招聘官网
1.爬取目标
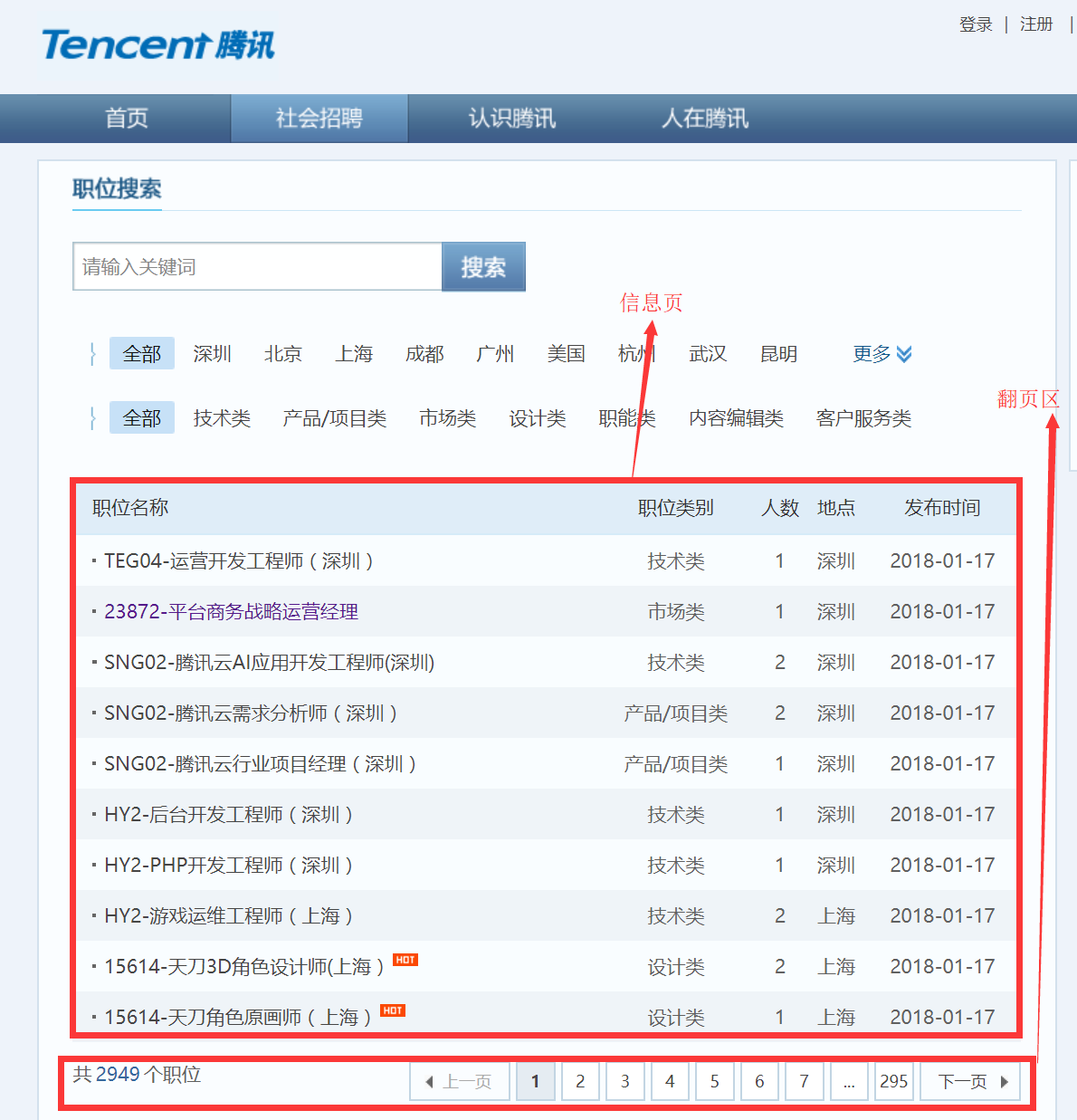
这次爬虫爬取的信息是腾讯官方招聘网站上的首页下的热招职位,如下图所示

2.爬取步骤
进入该页面下,观察该页面,我们爬取的信息就是下面我标出的信息页,信息页下面就是翻页区,不断翻页发现这些网页的链接后面有一定的规则
每页的链接:http://hr.tencent.com/position.php?&start=?#a 注:?就是改变的位置
使用requests模块获取页面信息:
1 # 请求获取网站页面的信息(html代码) 网址:http://hr.tencent.com/position.php 2 def load_request(number, items): 3 # User-Agent: 请求报头,用来把程序伪装成浏览器 4 headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36"} 5 # 使用requests的get请求服务器获取信息 6 request = requests.get('http://hr.tencent.com/position.php?&start='+str(number)+"#a", headers=headers) 7 # 取出返回信息的文本信息(html代码) 8 html = request.text
使用BeautifulSoup解析库对获取的页面代码进行解析,获取的页面信息其实就是上面第二张图的一页,打开浏览器的检查观察页面HTML代码的规则,每一条职位信息都在类名为even或odd的td标签内,先用select方法提取每一条信息的职位信息,再循环取每一条信息里的特定信息:
select方法使用: https://www.cnblogs.com/yizhenfeng168/p/6979339.html(转载)
1 # 网站代码解析 2 def parser(html, items): 3 # soup是一个BeautifulSoup对象,把HTML代码转换成树形结构存储在soup中 4 soup = BeautifulSoup(html, 'html.parser') 5 # 使用BeautifulSoup中的select方法提取HTML代码中的信息 6 even = soup.select('.even') 7 odd = soup.select('.odd') 8 str = odd + even # 字符串拼接 9 for item in str: # for循环迭代(遍历) 10 # _item为一个字典,存储一个工作职位的信息 11 _item = {} 12 # 职位名称 13 _item['name_of_work'] = item.select('td')[0].get_text() 14 # 职位链接 15 _item['link_of_work'] = 'http://hr.tencent.com' + item.select('td a')[0].attrs['href'] 16 # 职位类别 17 _item['category_of_work'] = item.select('td')[1].get_text() 18 # 工作地点 19 _item['where_of_work'] = item.select('td')[3].get_text() 20 # 发布时间 21 _item['time_of_release'] = item.select('td')[4].get_text() 22 # 所需人数 23 _item['number_of_person'] = item.select('td')[2].get_text() 24 # 把以上信息添加到列表中 25 items.append(_item)
最后写主函数,把爬取的信息以json格式存储,程序的所有代码如下:


1 # __author__ = 'wyb' 2 # date: 2018/1/9 3 4 from bs4 import BeautifulSoup # 导入BeautifulSoup解析库 5 import requests # 请求网站获取网页数据 6 import json # python中的一种轻量级的数据交换格式 7 8 # import sys # python中的操作系统模块 9 # sys.getdefaultencoding() 10 11 # 网站代码解析 12 def parser(html, items): 13 # soup是一个BeautifulSoup对象,把HTML代码转换成树形结构存储在soup中 14 soup = BeautifulSoup(html, 'html.parser') 15 # 使用BeautifulSoup中的select方法提取HTML代码中的信息 16 even = soup.select('.even') 17 odd = soup.select('.odd') 18 str = odd + even # 字符串拼接 19 for item in str: # for循环迭代(遍历) 20 # _item为一个字典,存储一个工作职位的信息 21 _item = {} 22 # 职位名称 23 _item['name_of_work'] = item.select('td')[0].get_text() 24 # 职位链接 25 _item['link_of_work'] = 'http://hr.tencent.com' + item.select('td a')[0].attrs['href'] 26 # 职位类别 27 _item['category_of_work'] = item.select('td')[1].get_text() 28 # 工作地点 29 _item['where_of_work'] = item.select('td')[3].get_text() 30 # 发布时间 31 _item['time_of_release'] = item.select('td')[4].get_text() 32 # 所需人数 33 _item['number_of_person'] = item.select('td')[2].get_text() 34 # 把以上信息添加到列表中 35 items.append(_item) 36 37 # 请求获取网站页面的信息(html代码) 网址:http://hr.tencent.com/position.php 38 def load_request(number, items): 39 # User-Agent: 请求报头,用来把程序伪装成浏览器 40 headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36"} 41 # 使用requests的get请求服务器获取信息 42 request = requests.get('http://hr.tencent.com/position.php?&start='+str(number)+"#a", headers=headers) 43 # 取出返回信息的文本信息(html代码) 44 html = request.text 45 parser(html, items) 46 47 if __name__ == "__main__": 48 number = 0 # 49 items = [] # 列表 50 swith = True 51 while swith: 52 if number >= 50: 53 # swith相当于一个开关请示,如果请求发出,爬虫启动 54 swith = False 55 load_request(number, items) 56 # 一次性爬取10页数据 57 number += 10 58 content = json.dumps(items, ensure_ascii=False) 59 # 数据读入json中 60 with open('txzhaoping.json', 'w',encoding='utf-8') as f: 61 f.write(content)
运行程序,结果如下:

too young too simple sometimes native!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号